 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Meets Projective Clustering
Oct 08, 2020


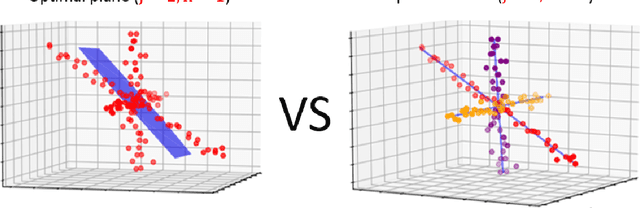
A common approach for compressing NLP networks is to encode the embedding layer as a matrix $A\in\mathbb{R}^{n\times d}$, compute its rank-$j$ approximation $A_j$ via SVD, and then factor $A_j$ into a pair of matrices that correspond to smaller fully-connected layers to replace the original embedding layer. Geometrically, the rows of $A$ represent points in $\mathbb{R}^d$, and the rows of $A_j$ represent their projections onto the $j$-dimensional subspace that minimizes the sum of squared distances ("errors") to the points. In practice, these rows of $A$ may be spread around $k>1$ subspaces, so factoring $A$ based on a single subspace may lead to large errors that turn into large drops in accuracy. Inspired by \emph{projective clustering} from computational geometry, we suggest replacing this subspace by a set of $k$ subspaces, each of dimension $j$, that minimizes the sum of squared distances over every point (row in $A$) to its \emph{closest} subspace. Based on this approach, we provide a novel architecture that replaces the original embedding layer by a set of $k$ small layers that operate in parallel and are then recombined with a single fully-connected layer. Extensive experimental results on the GLUE benchmark yield networks that are both more accurate and smaller compared to the standard matrix factorization (SVD). For example, we further compress DistilBERT by reducing the size of the embedding layer by $40\%$ while incurring only a $0.5\%$ average drop in accuracy over all nine GLUE tasks, compared to a $2.8\%$ drop using the existing SVD approach. On RoBERTa we achieve $43\%$ compression of the embedding layer with less than a $0.8\%$ average drop in accuracy as compared to a $3\%$ drop previously. Open code for reproducing and extending our results is provided.
Provable Filter Pruning for Efficient Neural Networks
Nov 18, 2019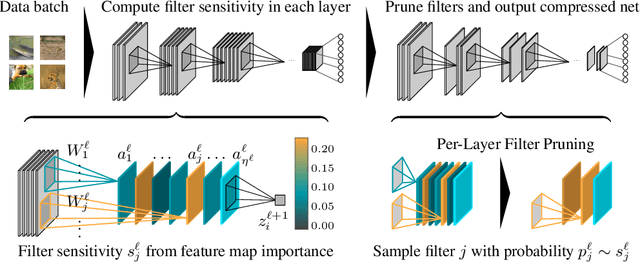



We present a provable, sampling-based approach for generating compact Convolutional Neural Networks (CNNs) by identifying and removing redundant filters from an over-parameterized network. Our algorithm uses a small batch of input data points to assign a saliency score to each filter and constructs an importance sampling distribution where filters that highly affect the output are sampled with correspondingly high probability. In contrast to existing filter pruning approaches, our method is simultaneously data-informed, exhibits provable guarantees on the size and performance of the pruned network, and is widely applicable to varying network architectures and data sets. Our analytical bounds bridge the notions of compressibility and importance of network structures, which gives rise to a fully-automated procedure for identifying and preserving filters in layers that are essential to the network's performance. Our experimental evaluations on popular architectures and data sets show that our algorithm consistently generates sparser and more efficient models than those constructed by existing filter pruning approaches.