 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Flows: Pruning Continuous-depth Models
Paper and Code

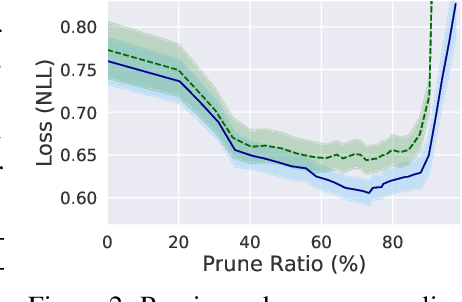
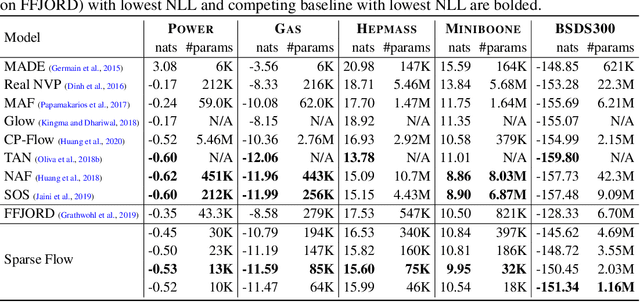
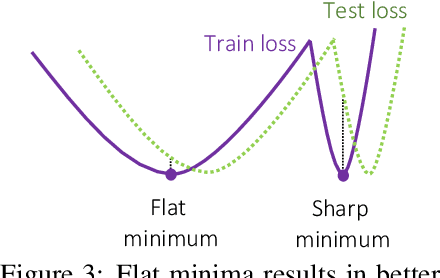
Continuous deep learning architectures enable learning of flexible probabilistic models for predictive modeling as neural ordinary differential equations (ODEs), and for generative modeling as continuous normalizing flows. In this work, we design a framework to decipher the internal dynamics of these continuous depth models by pruning their network architectures. Our empirical results suggest that pruning improves generalization for neural ODEs in generative modeling. Moreover, pruning finds minimal and efficient neural ODE representations with up to 98\% less parameters compared to the original network, without loss of accuracy. Finally, we show that by applying pruning we can obtain insightful information about the design of better neural ODEs.We hope our results will invigorate further research into the performance-size trade-offs of modern continuous-depth models.