 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMAI Gym for Science: Training Liquid Foundation Models for Drug Discovery
Mar 03, 2026General-purpose large language models (LLMs) that rely on in-context learning do not reliably deliver the scientific understanding and performance required for drug discovery tasks. Simply increasing model size or introducing reasoning tokens does not yield significant performance gains. To address this gap, we introduce the MMAI Gym for Science, a one-stop shop molecular data formats and modalities as well as task-specific reasoning, training, and benchmarking recipes designed to teach foundation models the 'language of molecules' in order to solve practical drug discovery problems. We use MMAI Gym to train an efficient Liquid Foundation Model (LFM) for these applications, demonstrating that smaller, purpose-trained foundation models can outperform substantially larger general-purpose or specialist models on molecular benchmarks. Across essential drug discovery tasks - including molecular optimization, ADMET property prediction, retrosynthesis, drug-target activity prediction, and functional group reasoning - the resulting model achieves near specialist-level performance and, in the majority of settings, surpasses larger models, while remaining more efficient and broadly applicable in the domain.
STAR: Synthesis of Tailored Architectures
Nov 26, 2024Iterative improvement of model architectures is fundamental to deep learning: Transformers first enabled scaling, and recent advances in model hybridization have pushed the quality-efficiency frontier. However, optimizing architectures remains challenging and expensive. Current automated or manual approaches fall short, largely due to limited progress in the design of search spaces and due to the simplicity of resulting patterns and heuristics. In this work, we propose a new approach for the synthesis of tailored architectures (STAR). Our approach combines a novel search space based on the theory of linear input-varying systems, supporting a hierarchical numerical encoding into architecture genomes. STAR genomes are automatically refined and recombined with gradient-free, evolutionary algorithms to optimize for multiple model quality and efficiency metrics. Using STAR, we optimize large populations of new architectures, leveraging diverse computational units and interconnection patterns, improving over highly-optimized Transformers and striped hybrid models on the frontier of quality, parameter size, and inference cache for autoregressive language modeling.
Gaussian Splatting to Real World Flight Navigation Transfer with Liquid Networks
Jun 21, 2024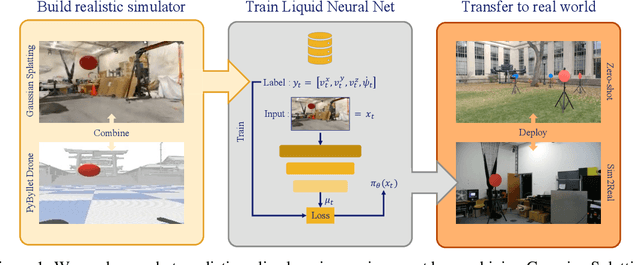



Simulators are powerful tools for autonomous robot learning as they offer scalable data generation, flexible design, and optimization of trajectories. However, transferring behavior learned from simulation data into the real world proves to be difficult, usually mitigated with compute-heavy domain randomization methods or further model fine-tuning. We present a method to improve generalization and robustness to distribution shifts in sim-to-real visual quadrotor navigation tasks. To this end, we first build a simulator by integrating Gaussian Splatting with quadrotor flight dynamics, and then, train robust navigation policies using Liquid neural networks. In this way, we obtain a full-stack imitation learning protocol that combines advances in 3D Gaussian splatting radiance field rendering, crafty programming of expert demonstration training data, and the task understanding capabilities of Liquid networks. Through a series of quantitative flight tests, we demonstrate the robust transfer of navigation skills learned in a single simulation scene directly to the real world. We further show the ability to maintain performance beyond the training environment under drastic distribution and physical environment changes. Our learned Liquid policies, trained on single target manoeuvres curated from a photorealistic simulated indoor flight only, generalize to multi-step hikes onboard a real hardware platform outdoors.
Exploring Latent Pathways: Enhancing the Interpretability of Autonomous Driving with a Variational Autoencoder
Apr 02, 2024Autonomous driving presents a complex challenge, which is usually addressed with artificial intelligence models that are end-to-end or modular in nature. Within the landscape of modular approaches, a bio-inspired neural circuit policy model has emerged as an innovative control module, offering a compact and inherently interpretable system to infer a steering wheel command from abstract visual features. Here, we take a leap forward by integrating a variational autoencoder with the neural circuit policy controller, forming a solution that directly generates steering commands from input camera images. By substituting the traditional convolutional neural network approach to feature extraction with a variational autoencoder, we enhance the system's interpretability, enabling a more transparent and understandable decision-making process. In addition to the architectural shift toward a variational autoencoder, this study introduces the automatic latent perturbation tool, a novel contribution designed to probe and elucidate the latent features within the variational autoencoder. The automatic latent perturbation tool automates the interpretability process, offering granular insights into how specific latent variables influence the overall model's behavior. Through a series of numerical experiments, we demonstrate the interpretative power of the variational autoencoder-neural circuit policy model and the utility of the automatic latent perturbation tool in making the inner workings of autonomous driving systems more transparent.
Toward Efficient Visual Gyroscopes: Spherical Moments, Harmonics Filtering, and Masking Techniques for Spherical Camera Applications
Apr 02, 2024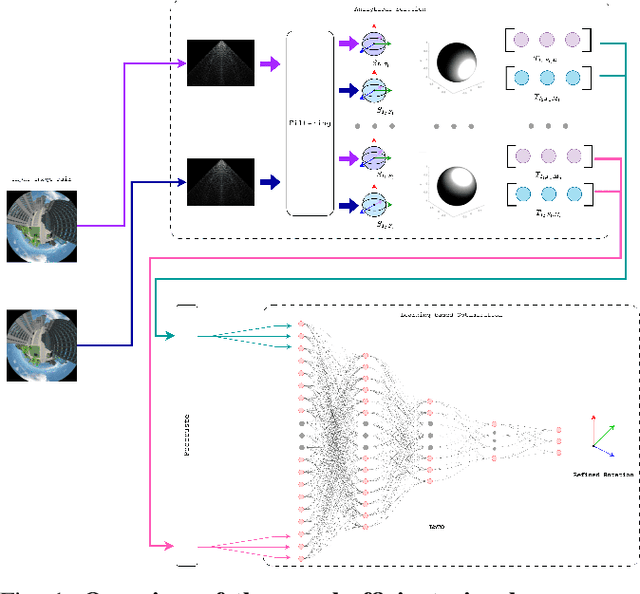



Unlike a traditional gyroscope, a visual gyroscope estimates camera rotation through images. The integration of omnidirectional cameras, offering a larger field of view compared to traditional RGB cameras, has proven to yield more accurate and robust results. However, challenges arise in situations that lack features, have substantial noise causing significant errors, and where certain features in the images lack sufficient strength, leading to less precise prediction results. Here, we address these challenges by introducing a novel visual gyroscope, which combines an analytical method with a neural network approach to provide a more efficient and accurate rotation estimation from spherical images. The presented method relies on three key contributions: an adapted analytical approach to compute the spherical moments coefficients, introduction of masks for better global feature representation, and the use of a multilayer perceptron to adaptively choose the best combination of masks and filters. Experimental results demonstrate superior performance of the proposed approach in terms of accuracy. The paper emphasizes the advantages of integrating machine learning to optimize analytical solutions, discusses limitations, and suggests directions for future research.
Uncertainty-aware Language Modeling for Selective Question Answering
Nov 26, 2023We present an automatic large language model (LLM) conversion approach that produces uncertainty-aware LLMs capable of estimating uncertainty with every prediction. Our approach is model- and data-agnostic, is computationally-efficient, and does not rely on external models or systems. We evaluate converted models on the selective question answering setting -- to answer as many questions as possible while maintaining a given accuracy, forgoing providing predictions when necessary. As part of our results, we test BERT and Llama 2 model variants on the SQuAD extractive QA task and the TruthfulQA generative QA task. We show that using the uncertainty estimates provided by our approach to selectively answer questions leads to significantly higher accuracy over directly using model probabilities.
Drive Anywhere: Generalizable End-to-end Autonomous Driving with Multi-modal Foundation Models
Oct 26, 2023



As autonomous driving technology matures, end-to-end methodologies have emerged as a leading strategy, promising seamless integration from perception to control via deep learning. However, existing systems grapple with challenges such as unexpected open set environments and the complexity of black-box models. At the same time, the evolution of deep learning introduces larger, multimodal foundational models, offering multi-modal visual and textual understanding. In this paper, we harness these multimodal foundation models to enhance the robustness and adaptability of autonomous driving systems, enabling out-of-distribution, end-to-end, multimodal, and more explainable autonomy. Specifically, we present an approach to apply end-to-end open-set (any environment/scene) autonomous driving that is capable of providing driving decisions from representations queryable by image and text. To do so, we introduce a method to extract nuanced spatial (pixel/patch-aligned) features from transformers to enable the encapsulation of both spatial and semantic features. Our approach (i) demonstrates unparalleled results in diverse tests while achieving significantly greater robustness in out-of-distribution situations, and (ii) allows the incorporation of latent space simulation (via text) for improved training (data augmentation via text) and policy debugging. We encourage the reader to check our explainer video at https://www.youtube.com/watch?v=4n-DJf8vXxo&feature=youtu.be and to view the code and demos on our project webpage at https://drive-anywhere.github.io/.
Capsa: A Unified Framework for Quantifying Risk in Deep Neural Networks
Aug 01, 2023



The modern pervasiveness of large-scale deep neural networks (NNs) is driven by their extraordinary performance on complex problems but is also plagued by their sudden, unexpected, and often catastrophic failures, particularly on challenging scenarios. Existing algorithms that provide risk-awareness to NNs are complex and ad-hoc. Specifically, these methods require significant engineering changes, are often developed only for particular settings, and are not easily composable. Here we present capsa, a framework for extending models with risk-awareness. Capsa provides a methodology for quantifying multiple forms of risk and composing different algorithms together to quantify different risk metrics in parallel. We validate capsa by implementing state-of-the-art uncertainty estimation algorithms within the capsa framework and benchmarking them on complex perception datasets. We demonstrate capsa's ability to easily compose aleatoric uncertainty, epistemic uncertainty, and bias estimation together in a single procedure, and show how this approach provides a comprehensive awareness of NN risk.
* Neural Information Processing Systems (NeurIPS) 2022. Workshop on Machine Learning for Autonomous Driving (ML4AD)
Learning Stability Attention in Vision-based End-to-end Driving Policies
Apr 05, 2023Modern end-to-end learning systems can learn to explicitly infer control from perception. However, it is difficult to guarantee stability and robustness for these systems since they are often exposed to unstructured, high-dimensional, and complex observation spaces (e.g., autonomous driving from a stream of pixel inputs). We propose to leverage control Lyapunov functions (CLFs) to equip end-to-end vision-based policies with stability properties and introduce stability attention in CLFs (att-CLFs) to tackle environmental changes and improve learning flexibility. We also present an uncertainty propagation technique that is tightly integrated into att-CLFs. We demonstrate the effectiveness of att-CLFs via comparison with classical CLFs, model predictive control, and vanilla end-to-end learning in a photo-realistic simulator and on a real full-scale autonomous vehicle.
Are All Vision Models Created Equal? A Study of the Open-Loop to Closed-Loop Causality Gap
Oct 09, 2022
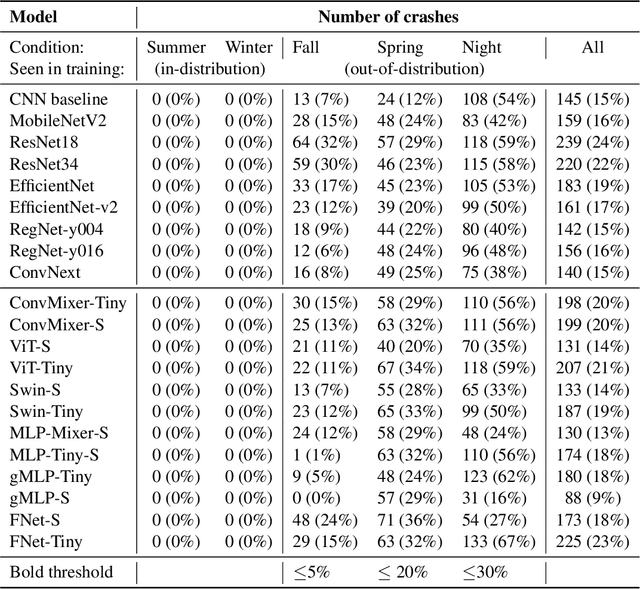


There is an ever-growing zoo of modern neural network models that can efficiently learn end-to-end control from visual observations. These advanced deep models, ranging from convolutional to patch-based networks, have been extensively tested on offline image classification and regression tasks. In this paper, we study these vision architectures with respect to the open-loop to closed-loop causality gap, i.e., offline training followed by an online closed-loop deployment. This causality gap typically emerges in robotics applications such as autonomous driving, where a network is trained to imitate the control commands of a human. In this setting, two situations arise: 1) Closed-loop testing in-distribution, where the test environment shares properties with those of offline training data. 2) Closed-loop testing under distribution shifts and out-of-distribution. Contrary to recently reported results, we show that under proper training guidelines, all vision models perform indistinguishably well on in-distribution deployment, resolving the causality gap. In situation 2, We observe that the causality gap disrupts performance regardless of the choice of the model architecture. Our results imply that the causality gap can be solved in situation one with our proposed training guideline with any modern network architecture, whereas achieving out-of-distribution generalization (situation two) requires further investigations, for instance, on data diversity rather than the model architecture.