 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Vision-Based Autonomous Aerial Wildlife Monitoring
Aug 20, 2025



Wildlife field operations demand efficient parallel deployment methods to identify and interact with specific individuals, enabling simultaneous collective behavioral analysis, and health and safety interventions. Previous robotics solutions approach the problem from the herd perspective, or are manually operated and limited in scale. We propose a decentralized vision-based multi-quadrotor system for wildlife monitoring that is scalable, low-bandwidth, and sensor-minimal (single onboard RGB camera). Our approach enables robust identification and tracking of large species in their natural habitat. We develop novel vision-based coordination and tracking algorithms designed for dynamic, unstructured environments without reliance on centralized communication or control. We validate our system through real-world experiments, demonstrating reliable deployment in diverse field conditions.
Flex: End-to-End Text-Instructed Visual Navigation with Foundation Models
Oct 16, 2024



End-to-end learning directly maps sensory inputs to actions, creating highly integrated and efficient policies for complex robotics tasks. However, such models are tricky to efficiently train and often struggle to generalize beyond their training scenarios, limiting adaptability to new environments, tasks, and concepts. In this work, we investigate the minimal data requirements and architectural adaptations necessary to achieve robust closed-loop performance with vision-based control policies under unseen text instructions and visual distribution shifts. To this end, we design datasets with various levels of data representation richness, refine feature extraction protocols by leveraging multi-modal foundation model encoders, and assess the suitability of different policy network heads. Our findings are synthesized in Flex (Fly-lexically), a framework that uses pre-trained Vision Language Models (VLMs) as frozen patch-wise feature extractors, generating spatially aware embeddings that integrate semantic and visual information. These rich features form the basis for training highly robust downstream policies capable of generalizing across platforms, environments, and text-specified tasks. We demonstrate the effectiveness of this approach on quadrotor fly-to-target tasks, where agents trained via behavior cloning on a small simulated dataset successfully generalize to real-world scenes, handling diverse novel goals and command formulations.
Improving Efficiency of Sampling-based Motion Planning via Message-Passing Monte Carlo
Oct 04, 2024Sampling-based motion planning methods, while effective in high-dimensional spaces, often suffer from inefficiencies due to irregular sampling distributions, leading to suboptimal exploration of the configuration space. In this paper, we propose an approach that enhances the efficiency of these methods by utilizing low-discrepancy distributions generated through Message-Passing Monte Carlo (MPMC). MPMC leverages Graph Neural Networks (GNNs) to generate point sets that uniformly cover the space, with uniformity assessed using the the $\cL_p$-discrepancy measure, which quantifies the irregularity of sample distributions. By improving the uniformity of the point sets, our approach significantly reduces computational overhead and the number of samples required for solving motion planning problems. Experimental results demonstrate that our method outperforms traditional sampling techniques in terms of planning efficiency.
Gaussian Splatting to Real World Flight Navigation Transfer with Liquid Networks
Jun 21, 2024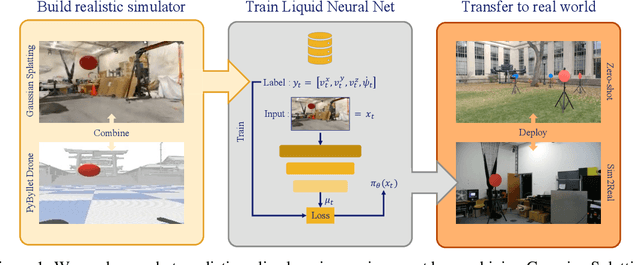



Simulators are powerful tools for autonomous robot learning as they offer scalable data generation, flexible design, and optimization of trajectories. However, transferring behavior learned from simulation data into the real world proves to be difficult, usually mitigated with compute-heavy domain randomization methods or further model fine-tuning. We present a method to improve generalization and robustness to distribution shifts in sim-to-real visual quadrotor navigation tasks. To this end, we first build a simulator by integrating Gaussian Splatting with quadrotor flight dynamics, and then, train robust navigation policies using Liquid neural networks. In this way, we obtain a full-stack imitation learning protocol that combines advances in 3D Gaussian splatting radiance field rendering, crafty programming of expert demonstration training data, and the task understanding capabilities of Liquid networks. Through a series of quantitative flight tests, we demonstrate the robust transfer of navigation skills learned in a single simulation scene directly to the real world. We further show the ability to maintain performance beyond the training environment under drastic distribution and physical environment changes. Our learned Liquid policies, trained on single target manoeuvres curated from a photorealistic simulated indoor flight only, generalize to multi-step hikes onboard a real hardware platform outdoors.
Local Non-Cooperative Games with Principled Player Selection for Scalable Motion Planning
Oct 19, 2023



Game-theoretic motion planners are a powerful tool for the control of interactive multi-agent robot systems. Indeed, contrary to predict-then-plan paradigms, game-theoretic planners do not ignore the interactive nature of the problem, and simultaneously predict the behaviour of other agents while considering change in one's policy. This, however, comes at the expense of computational complexity, especially as the number of agents considered grows. In fact, planning with more than a handful of agents can quickly become intractable, disqualifying game-theoretic planners as possible candidates for large scale planning. In this paper, we propose a planning algorithm enabling the use of game-theoretic planners in robot systems with a large number of agents. Our planner is based on the reality of locality of information and thus deploys local games with a selected subset of agents in a receding horizon fashion to plan collision avoiding trajectories. We propose five different principled schemes for selecting game participants and compare their collision avoidance performance. We observe that the use of Control Barrier Functions for priority ranking is a potent solution to the player selection problem for motion planning.
Follow Anything: Open-set detection, tracking, and following in real-time
Aug 10, 2023



Tracking and following objects of interest is critical to several robotics use cases, ranging from industrial automation to logistics and warehousing, to healthcare and security. In this paper, we present a robotic system to detect, track, and follow any object in real-time. Our approach, dubbed ``follow anything'' (FAn), is an open-vocabulary and multimodal model -- it is not restricted to concepts seen at training time and can be applied to novel classes at inference time using text, images, or click queries. Leveraging rich visual descriptors from large-scale pre-trained models (foundation models), FAn can detect and segment objects by matching multimodal queries (text, images, clicks) against an input image sequence. These detected and segmented objects are tracked across image frames, all while accounting for occlusion and object re-emergence. We demonstrate FAn on a real-world robotic system (a micro aerial vehicle) and report its ability to seamlessly follow the objects of interest in a real-time control loop. FAn can be deployed on a laptop with a lightweight (6-8 GB) graphics card, achieving a throughput of 6-20 frames per second. To enable rapid adoption, deployment, and extensibility, we open-source all our code on our project webpage at https://github.com/alaamaalouf/FollowAnything . We also encourage the reader the watch our 5-minutes explainer video in this https://www.youtube.com/watch?v=6Mgt3EPytrw .
Learning Stability Attention in Vision-based End-to-end Driving Policies
Apr 05, 2023Modern end-to-end learning systems can learn to explicitly infer control from perception. However, it is difficult to guarantee stability and robustness for these systems since they are often exposed to unstructured, high-dimensional, and complex observation spaces (e.g., autonomous driving from a stream of pixel inputs). We propose to leverage control Lyapunov functions (CLFs) to equip end-to-end vision-based policies with stability properties and introduce stability attention in CLFs (att-CLFs) to tackle environmental changes and improve learning flexibility. We also present an uncertainty propagation technique that is tightly integrated into att-CLFs. We demonstrate the effectiveness of att-CLFs via comparison with classical CLFs, model predictive control, and vanilla end-to-end learning in a photo-realistic simulator and on a real full-scale autonomous vehicle.
Cooperative Flight Control Using Visual-Attention -- Air-Guardian
Dec 21, 2022



The cooperation of a human pilot with an autonomous agent during flight control realizes parallel autonomy. A parallel-autonomous system acts as a guardian that significantly enhances the robustness and safety of flight operations in challenging circumstances. Here, we propose an air-guardian concept that facilitates cooperation between an artificial pilot agent and a parallel end-to-end neural control system. Our vision-based air-guardian system combines a causal continuous-depth neural network model with a cooperation layer to enable parallel autonomy between a pilot agent and a control system based on perceived differences in their attention profile. The attention profiles are obtained by computing the networks' saliency maps (feature importance) through the VisualBackProp algorithm. The guardian agent is trained via reinforcement learning in a fixed-wing aircraft simulated environment. When the attention profile of the pilot and guardian agents align, the pilot makes control decisions. If the attention map of the pilot and the guardian do not align, the air-guardian makes interventions and takes over the control of the aircraft. We show that our attention-based air-guardian system can balance the trade-off between its level of involvement in the flight and the pilot's expertise and attention. We demonstrate the effectivness of our methods in simulated flight scenarios with a fixed-wing aircraft and on a real drone platform.
Intention Communication and Hypothesis Likelihood in Game-Theoretic Motion Planning
Sep 26, 2022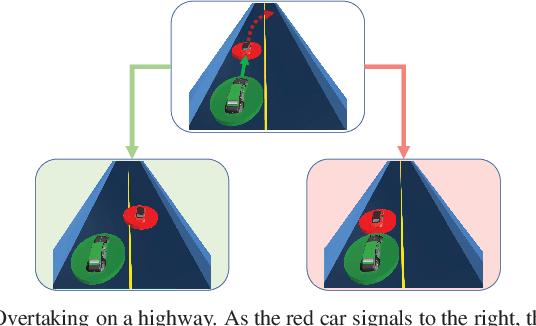
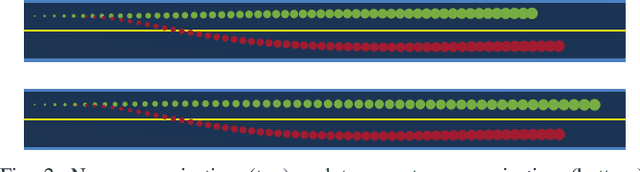


Game-theoretic motion planners are a potent solution for controlling systems of multiple highly interactive robots. Most existing game-theoretic planners unrealistically assume a priori objective function knowledge is available to all agents. To address this, we propose a fault-tolerant receding horizon game-theoretic motion planner that leverages inter-agent communication with intention hypothesis likelihood. Specifically, robots communicate their objective function incorporating their intentions. A discrete Bayesian filter is designed to infer the objectives in real-time based on the discrepancy between observed trajectories and the ones from communicated intentions. In simulation, we consider three safety-critical autonomous driving scenarios of overtaking, lane-merging and intersection crossing, to demonstrate our planner's ability to capitalize on alternative intention hypotheses to generate safe trajectories in the presence of faulty transmissions in the communication network.
Liquid Structural State-Space Models
Sep 26, 2022



A proper parametrization of state transition matrices of linear state-space models (SSMs) followed by standard nonlinearities enables them to efficiently learn representations from sequential data, establishing the state-of-the-art on a large series of long-range sequence modeling benchmarks. In this paper, we show that we can improve further when the structural SSM such as S4 is given by a linear liquid time-constant (LTC) state-space model. LTC neural networks are causal continuous-time neural networks with an input-dependent state transition module, which makes them learn to adapt to incoming inputs at inference. We show that by using a diagonal plus low-rank decomposition of the state transition matrix introduced in S4, and a few simplifications, the LTC-based structural state-space model, dubbed Liquid-S4, achieves the new state-of-the-art generalization across sequence modeling tasks with long-term dependencies such as image, text, audio, and medical time-series, with an average performance of 87.32% on the Long-Range Arena benchmark. On the full raw Speech Command recognition, dataset Liquid-S4 achieves 96.78% accuracy with a 30% reduction in parameter counts compared to S4. The additional gain in performance is the direct result of the Liquid-S4's kernel structure that takes into account the similarities of the input sequence samples during training and inference.