 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlex: End-to-End Text-Instructed Visual Navigation with Foundation Models
Oct 16, 2024



End-to-end learning directly maps sensory inputs to actions, creating highly integrated and efficient policies for complex robotics tasks. However, such models are tricky to efficiently train and often struggle to generalize beyond their training scenarios, limiting adaptability to new environments, tasks, and concepts. In this work, we investigate the minimal data requirements and architectural adaptations necessary to achieve robust closed-loop performance with vision-based control policies under unseen text instructions and visual distribution shifts. To this end, we design datasets with various levels of data representation richness, refine feature extraction protocols by leveraging multi-modal foundation model encoders, and assess the suitability of different policy network heads. Our findings are synthesized in Flex (Fly-lexically), a framework that uses pre-trained Vision Language Models (VLMs) as frozen patch-wise feature extractors, generating spatially aware embeddings that integrate semantic and visual information. These rich features form the basis for training highly robust downstream policies capable of generalizing across platforms, environments, and text-specified tasks. We demonstrate the effectiveness of this approach on quadrotor fly-to-target tasks, where agents trained via behavior cloning on a small simulated dataset successfully generalize to real-world scenes, handling diverse novel goals and command formulations.
Gaussian Splatting to Real World Flight Navigation Transfer with Liquid Networks
Jun 21, 2024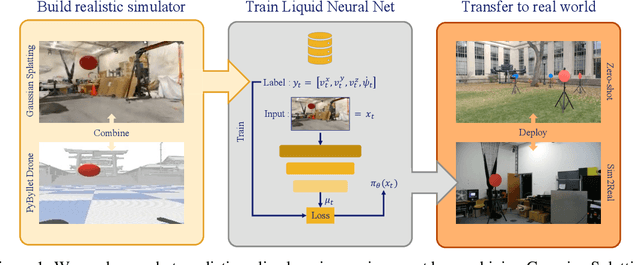



Simulators are powerful tools for autonomous robot learning as they offer scalable data generation, flexible design, and optimization of trajectories. However, transferring behavior learned from simulation data into the real world proves to be difficult, usually mitigated with compute-heavy domain randomization methods or further model fine-tuning. We present a method to improve generalization and robustness to distribution shifts in sim-to-real visual quadrotor navigation tasks. To this end, we first build a simulator by integrating Gaussian Splatting with quadrotor flight dynamics, and then, train robust navigation policies using Liquid neural networks. In this way, we obtain a full-stack imitation learning protocol that combines advances in 3D Gaussian splatting radiance field rendering, crafty programming of expert demonstration training data, and the task understanding capabilities of Liquid networks. Through a series of quantitative flight tests, we demonstrate the robust transfer of navigation skills learned in a single simulation scene directly to the real world. We further show the ability to maintain performance beyond the training environment under drastic distribution and physical environment changes. Our learned Liquid policies, trained on single target manoeuvres curated from a photorealistic simulated indoor flight only, generalize to multi-step hikes onboard a real hardware platform outdoors.
Out of Distribution Generalization via Interventional Style Transfer in Single-Cell Microscopy
Jun 15, 2023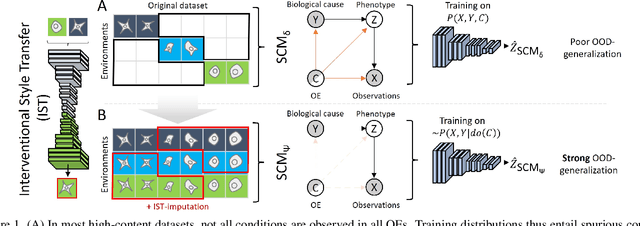
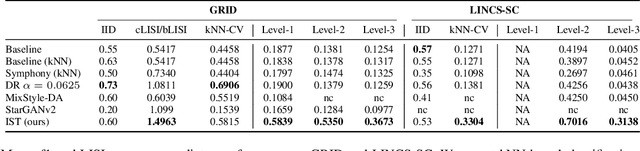

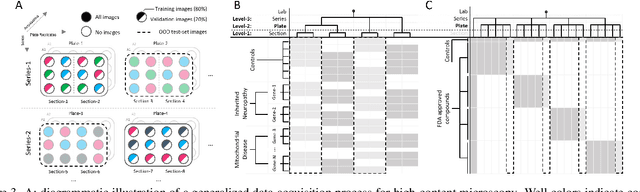
Real-world deployment of computer vision systems, including in the discovery processes of biomedical research, requires causal representations that are invariant to contextual nuisances and generalize to new data. Leveraging the internal replicate structure of two novel single-cell fluorescent microscopy datasets, we propose generally applicable tests to assess the extent to which models learn causal representations across increasingly challenging levels of OOD-generalization. We show that despite seemingly strong performance, as assessed by other established metrics, both naive and contemporary baselines designed to ward against confounding, collapse on these tests. We introduce a new method, Interventional Style Transfer (IST), that substantially improves OOD generalization by generating interventional training distributions in which spurious correlations between biological causes and nuisances are mitigated. We publish our code and datasets.