 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Algorithms for Growing Collision-Free Convex Polytopes in Robot Configuration Space
Oct 16, 2024We propose two novel algorithms for constructing convex collision-free polytopes in robot configuration space. Finding these polytopes enables the application of stronger motion-planning frameworks such as trajectory optimization with Graphs of Convex Sets [1] and is currently a major roadblock in the adoption of these approaches. In this paper, we build upon IRIS-NP (Iterative Regional Inflation by Semidefinite & Nonlinear Programming) [2] to significantly improve tunability, runtimes, and scaling to complex environments. IRIS-NP uses nonlinear programming paired with uniform random initialization to find configurations on the boundary of the free configuration space. Our key insight is that finding near-by configuration-space obstacles using sampling is inexpensive and greatly accelerates region generation. We propose two algorithms using such samples to either employ nonlinear programming more efficiently (IRIS-NP2 ) or circumvent it altogether using a massively-parallel zero-order optimization strategy (IRIS-ZO). We also propose a termination condition that controls the probability of exceeding a user-specified permissible fraction-in-collision, eliminating a significant source of tuning difficulty in IRIS-NP. We compare performance across eight robot environments, showing that IRIS-ZO achieves an order-of-magnitude speed advantage over IRIS-NP. IRISNP2, also significantly faster than IRIS-NP, builds larger polytopes using fewer hyperplanes, enabling faster downstream computation. Website: https://sites.google.com/view/fastiris
Growing Q-Networks: Solving Continuous Control Tasks with Adaptive Control Resolution
Apr 05, 2024



Recent reinforcement learning approaches have shown surprisingly strong capabilities of bang-bang policies for solving continuous control benchmarks. The underlying coarse action space discretizations often yield favourable exploration characteristics while final performance does not visibly suffer in the absence of action penalization in line with optimal control theory. In robotics applications, smooth control signals are commonly preferred to reduce system wear and energy efficiency, but action costs can be detrimental to exploration during early training. In this work, we aim to bridge this performance gap by growing discrete action spaces from coarse to fine control resolution, taking advantage of recent results in decoupled Q-learning to scale our approach to high-dimensional action spaces up to dim(A) = 38. Our work indicates that an adaptive control resolution in combination with value decomposition yields simple critic-only algorithms that yield surprisingly strong performance on continuous control tasks.
Cooperative Flight Control Using Visual-Attention -- Air-Guardian
Dec 21, 2022



The cooperation of a human pilot with an autonomous agent during flight control realizes parallel autonomy. A parallel-autonomous system acts as a guardian that significantly enhances the robustness and safety of flight operations in challenging circumstances. Here, we propose an air-guardian concept that facilitates cooperation between an artificial pilot agent and a parallel end-to-end neural control system. Our vision-based air-guardian system combines a causal continuous-depth neural network model with a cooperation layer to enable parallel autonomy between a pilot agent and a control system based on perceived differences in their attention profile. The attention profiles are obtained by computing the networks' saliency maps (feature importance) through the VisualBackProp algorithm. The guardian agent is trained via reinforcement learning in a fixed-wing aircraft simulated environment. When the attention profile of the pilot and guardian agents align, the pilot makes control decisions. If the attention map of the pilot and the guardian do not align, the air-guardian makes interventions and takes over the control of the aircraft. We show that our attention-based air-guardian system can balance the trade-off between its level of involvement in the flight and the pilot's expertise and attention. We demonstrate the effectivness of our methods in simulated flight scenarios with a fixed-wing aircraft and on a real drone platform.
Solving Continuous Control via Q-learning
Oct 22, 2022While there has been substantial success in applying actor-critic methods to continuous control, simpler critic-only methods such as Q-learning often remain intractable in the associated high-dimensional action spaces. However, most actor-critic methods come at the cost of added complexity: heuristics for stabilization, compute requirements as well as wider hyperparameter search spaces. We show that these issues can be largely alleviated via Q-learning by combining action discretization with value decomposition, framing single-agent control as cooperative multi-agent reinforcement learning (MARL). With bang-bang actions, performance of this critic-only approach matches state-of-the-art continuous actor-critic methods when learning from features or pixels. We extend classical bandit examples from cooperative MARL to provide intuition for how decoupled critics leverage state information to coordinate joint optimization, and demonstrate surprisingly strong performance across a wide variety of continuous control tasks.
Interpreting Neural Policies with Disentangled Tree Representations
Oct 13, 2022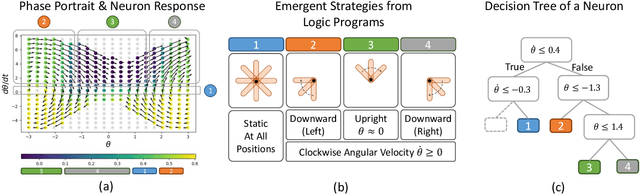
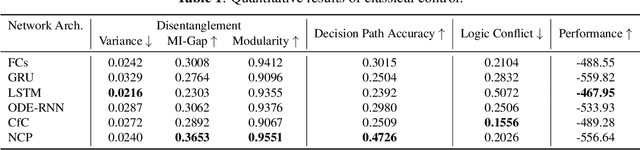
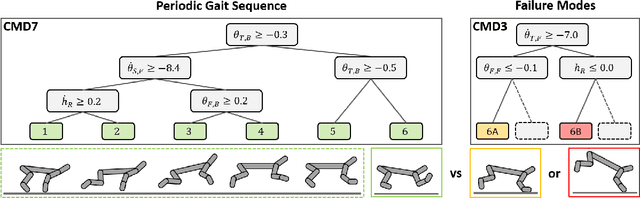
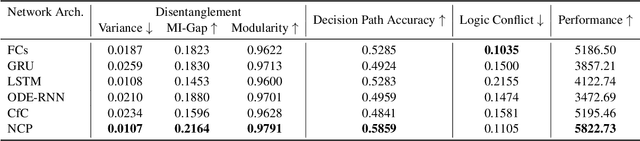
Compact neural networks used in policy learning and closed-loop end-to-end control learn representations from data that encapsulate agent dynamics and potentially the agent-environment's factors of variation. A formal and quantitative understanding and interpretation of these explanatory factors in neural representations is difficult to achieve due to the complex and intertwined correspondence of neural activities with emergent behaviors. In this paper, we design a new algorithm that programmatically extracts tree representations from compact neural policies, in the form of a set of logic programs grounded by the world state. To assess how well networks uncover the dynamics of the task and their factors of variation, we introduce interpretability metrics that measure the disentanglement of learned neural dynamics from a concentration of decisions, mutual information, and modularity perspectives. Moreover, our method allows us to quantify how accurate the extracted decision paths (explanations) are and computes cross-neuron logic conflict. We demonstrate the effectiveness of our approach with several types of compact network architectures on a series of end-to-end learning to control tasks.
Neighborhood Mixup Experience Replay: Local Convex Interpolation for Improved Sample Efficiency in Continuous Control Tasks
May 18, 2022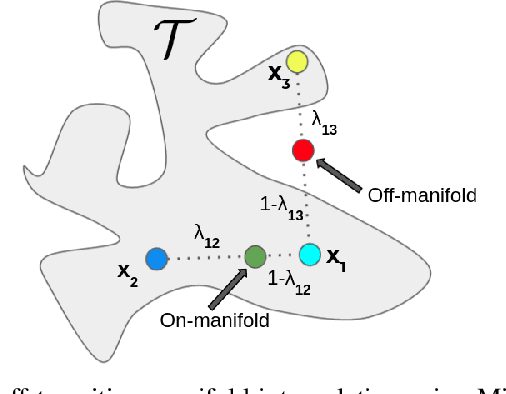
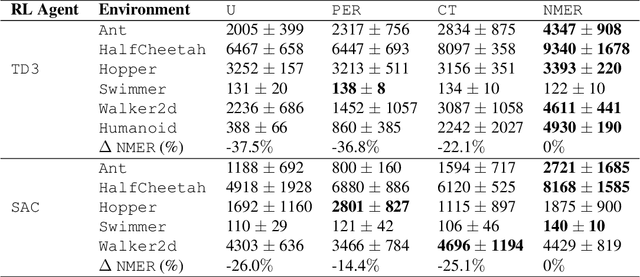
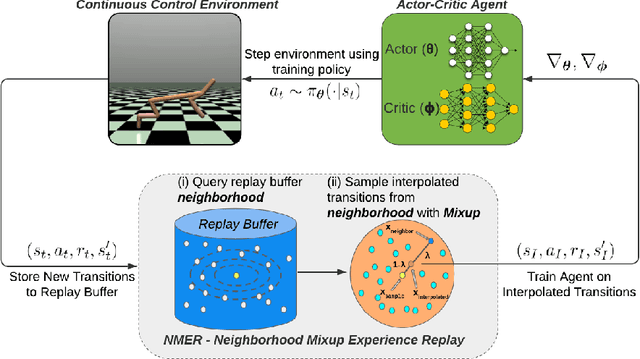

Experience replay plays a crucial role in improving the sample efficiency of deep reinforcement learning agents. Recent advances in experience replay propose using Mixup (Zhang et al., 2018) to further improve sample efficiency via synthetic sample generation. We build upon this technique with Neighborhood Mixup Experience Replay (NMER), a geometrically-grounded replay buffer that interpolates transitions with their closest neighbors in state-action space. NMER preserves a locally linear approximation of the transition manifold by only applying Mixup between transitions with vicinal state-action features. Under NMER, a given transition's set of state action neighbors is dynamic and episode agnostic, in turn encouraging greater policy generalizability via inter-episode interpolation. We combine our approach with recent off-policy deep reinforcement learning algorithms and evaluate on continuous control environments. We observe that NMER improves sample efficiency by an average 94% (TD3) and 29% (SAC) over baseline replay buffers, enabling agents to effectively recombine previous experiences and learn from limited data.
Is Bang-Bang Control All You Need? Solving Continuous Control with Bernoulli Policies
Nov 03, 2021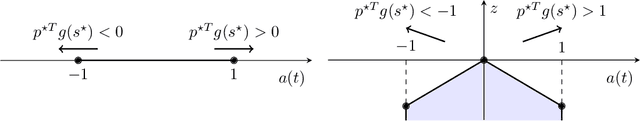


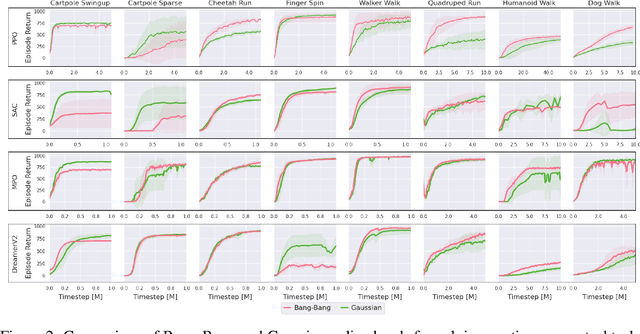
Reinforcement learning (RL) for continuous control typically employs distributions whose support covers the entire action space. In this work, we investigate the colloquially known phenomenon that trained agents often prefer actions at the boundaries of that space. We draw theoretical connections to the emergence of bang-bang behavior in optimal control, and provide extensive empirical evaluation across a variety of recent RL algorithms. We replace the normal Gaussian by a Bernoulli distribution that solely considers the extremes along each action dimension - a bang-bang controller. Surprisingly, this achieves state-of-the-art performance on several continuous control benchmarks - in contrast to robotic hardware, where energy and maintenance cost affect controller choices. Since exploration, learning,and the final solution are entangled in RL, we provide additional imitation learning experiments to reduce the impact of exploration on our analysis. Finally, we show that our observations generalize to environments that aim to model real-world challenges and evaluate factors to mitigate the emergence of bang-bang solutions. Our findings emphasize challenges for benchmarking continuous control algorithms, particularly in light of potential real-world applications.
Deep Latent Competition: Learning to Race Using Visual Control Policies in Latent Space
Feb 19, 2021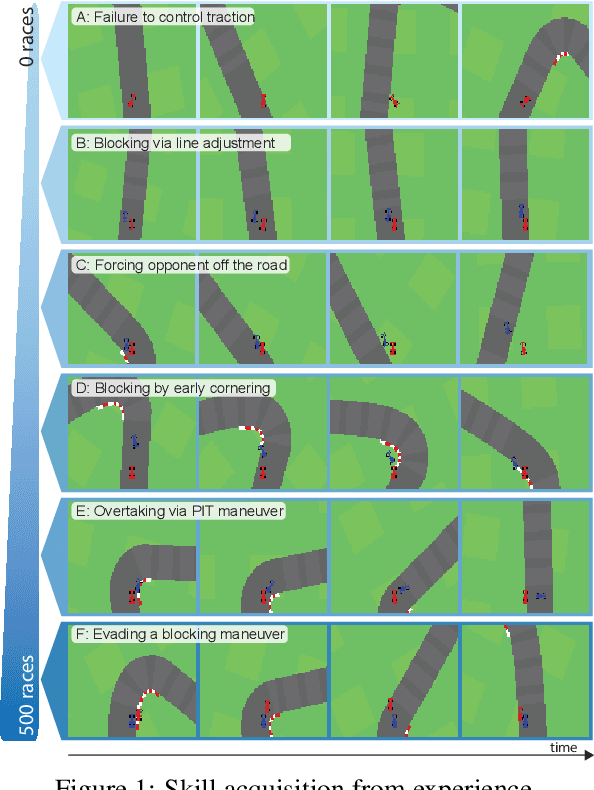
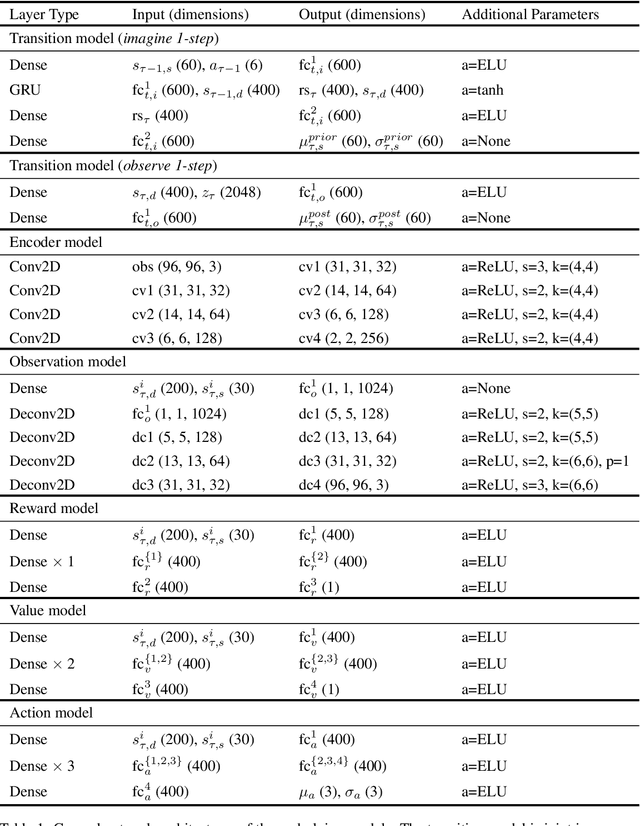
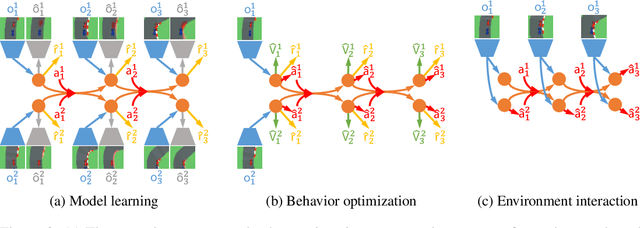
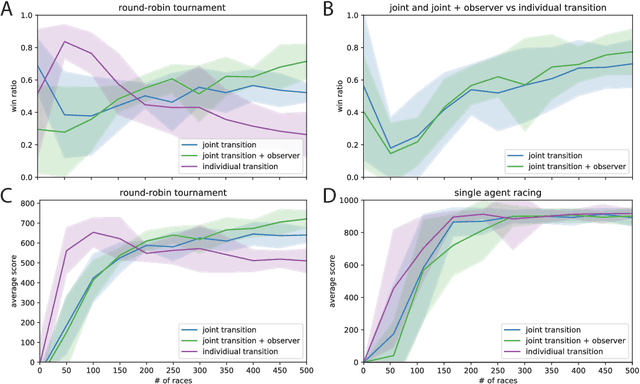
Learning competitive behaviors in multi-agent settings such as racing requires long-term reasoning about potential adversarial interactions. This paper presents Deep Latent Competition (DLC), a novel reinforcement learning algorithm that learns competitive visual control policies through self-play in imagination. The DLC agent imagines multi-agent interaction sequences in the compact latent space of a learned world model that combines a joint transition function with opponent viewpoint prediction. Imagined self-play reduces costly sample generation in the real world, while the latent representation enables planning to scale gracefully with observation dimensionality. We demonstrate the effectiveness of our algorithm in learning competitive behaviors on a novel multi-agent racing benchmark that requires planning from image observations. Code and videos available at https://sites.google.com/view/deep-latent-competition.
Learning to Plan Optimistically: Uncertainty-Guided Deep Exploration via Latent Model Ensembles
Oct 27, 2020
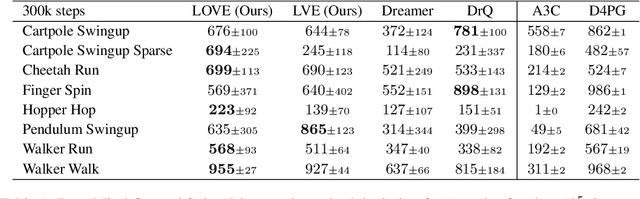
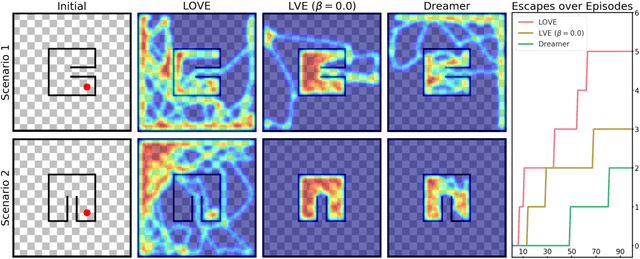

Learning complex behaviors through interaction requires coordinated long-term planning. Random exploration and novelty search lack task-centric guidance and waste effort on non-informative interactions. Instead, decision making should target samples with the potential to optimize performance far into the future, while only reducing uncertainty where conducive to this objective. This paper presents latent optimistic value exploration (LOVE), a strategy that enables deep exploration through optimism in the face of uncertain long-term rewards. We combine finite horizon rollouts from a latent model with value function estimates to predict infinite horizon returns and recover associated uncertainty through ensembling. Policy training then proceeds on an upper confidence bound (UCB) objective to identify and select the interactions most promising to improve long-term performance. We apply LOVE to visual control tasks in continuous state-action spaces and demonstrate improved sample complexity on a selection of benchmarking tasks.
Locomotion Planning through a Hybrid Bayesian Trajectory Optimization
Mar 09, 2019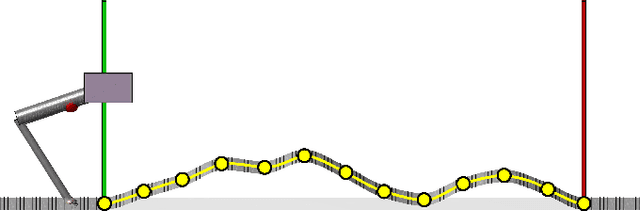
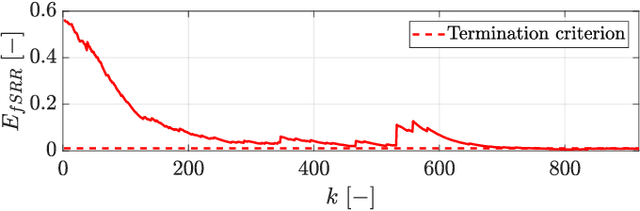
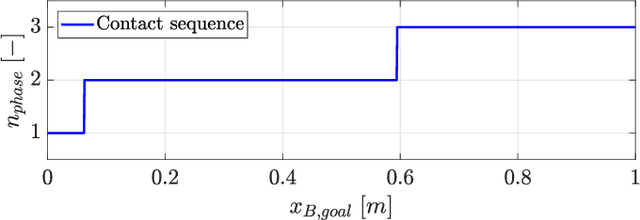
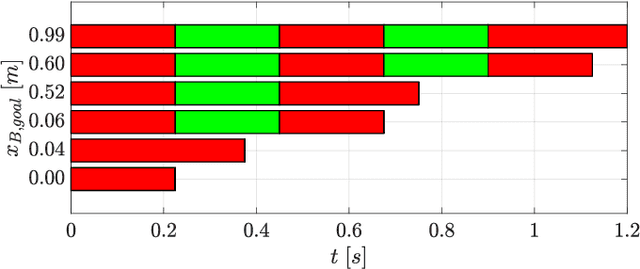
Locomotion planning for legged systems requires reasoning about suitable contact schedules. The contact sequence and timings constitute a hybrid dynamical system and prescribe a subset of achievable motions. State-of-the-art approaches cast motion planning as an optimal control problem. In order to decrease computational complexity, one common strategy separates footstep planning from motion optimization and plans contacts using heuristics. In this paper, we propose to learn contact schedule selection from high-level task descriptors using Bayesian optimization. A bi-level optimization is defined in which a Gaussian process model predicts the performance of trajectories generated by a motion planning nonlinear program. The agent, therefore, retains the ability to reason about suitable contact schedules, while explicit computation of the corresponding gradients is avoided. We delineate the algorithm in its general form and provide results for planning single-legged hopping. Our method is capable of learning contact schedule transitions that align with human intuition. It performs competitively against a heuristic baseline in predicting task appropriate contact schedules.