 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
TacSL: A Library for Visuotactile Sensor Simulation and Learning
Aug 12, 2024



For both humans and robots, the sense of touch, known as tactile sensing, is critical for performing contact-rich manipulation tasks. Three key challenges in robotic tactile sensing are 1) interpreting sensor signals, 2) generating sensor signals in novel scenarios, and 3) learning sensor-based policies. For visuotactile sensors, interpretation has been facilitated by their close relationship with vision sensors (e.g., RGB cameras). However, generation is still difficult, as visuotactile sensors typically involve contact, deformation, illumination, and imaging, all of which are expensive to simulate; in turn, policy learning has been challenging, as simulation cannot be leveraged for large-scale data collection. We present \textbf{TacSL} (\textit{taxel}), a library for GPU-based visuotactile sensor simulation and learning. \textbf{TacSL} can be used to simulate visuotactile images and extract contact-force distributions over $200\times$ faster than the prior state-of-the-art, all within the widely-used Isaac Gym simulator. Furthermore, \textbf{TacSL} provides a learning toolkit containing multiple sensor models, contact-intensive training environments, and online/offline algorithms that can facilitate policy learning for sim-to-real applications. On the algorithmic side, we introduce a novel online reinforcement-learning algorithm called asymmetric actor-critic distillation (\sysName), designed to effectively and efficiently learn tactile-based policies in simulation that can transfer to the real world. Finally, we demonstrate the utility of our library and algorithms by evaluating the benefits of distillation and multimodal sensing for contact-rich manip ulation tasks, and most critically, performing sim-to-real transfer. Supplementary videos and results are at \url{https://iakinola23.github.io/tacsl/}.
CERBERUS: Autonomous Legged and Aerial Robotic Exploration in the Tunnel and Urban Circuits of the DARPA Subterranean Challenge
Jan 18, 2022

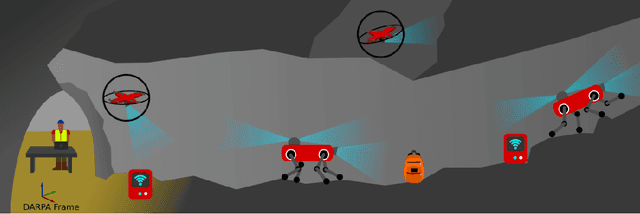

Autonomous exploration of subterranean environments constitutes a major frontier for robotic systems as underground settings present key challenges that can render robot autonomy hard to achieve. This has motivated the DARPA Subterranean Challenge, where teams of robots search for objects of interest in various underground environments. In response, the CERBERUS system-of-systems is presented as a unified strategy towards subterranean exploration using legged and flying robots. As primary robots, ANYmal quadruped systems are deployed considering their endurance and potential to traverse challenging terrain. For aerial robots, both conventional and collision-tolerant multirotors are utilized to explore spaces too narrow or otherwise unreachable by ground systems. Anticipating degraded sensing conditions, a complementary multi-modal sensor fusion approach utilizing camera, LiDAR, and inertial data for resilient robot pose estimation is proposed. Individual robot pose estimates are refined by a centralized multi-robot map optimization approach to improve the reported location accuracy of detected objects of interest in the DARPA-defined coordinate frame. Furthermore, a unified exploration path planning policy is presented to facilitate the autonomous operation of both legged and aerial robots in complex underground networks. Finally, to enable communication between the robots and the base station, CERBERUS utilizes a ground rover with a high-gain antenna and an optical fiber connection to the base station, alongside breadcrumbing of wireless nodes by our legged robots. We report results from the CERBERUS system-of-systems deployment at the DARPA Subterranean Challenge Tunnel and Urban Circuits, along with the current limitations and the lessons learned for the benefit of the community.
Imitation Learning from MPC for Quadrupedal Multi-Gait Control
Mar 26, 2021
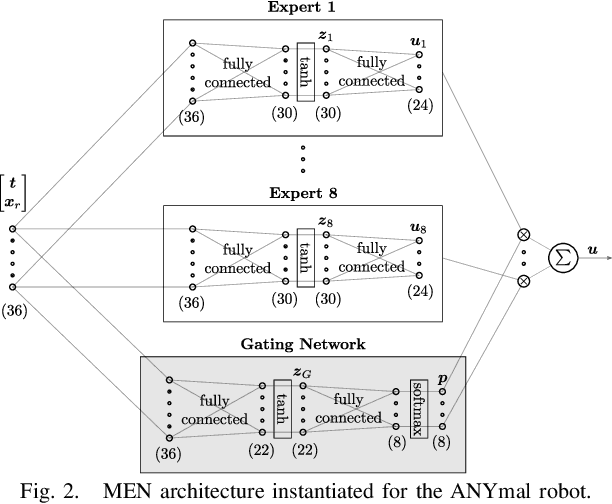
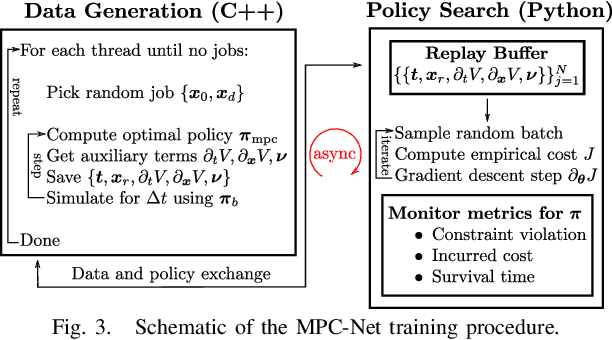
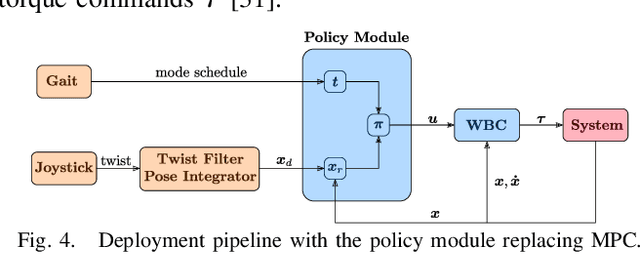
We present a learning algorithm for training a single policy that imitates multiple gaits of a walking robot. To achieve this, we use and extend MPC-Net, which is an Imitation Learning approach guided by Model Predictive Control (MPC). The strategy of MPC-Net differs from many other approaches since its objective is to minimize the control Hamiltonian, which derives from the principle of optimality. To represent the policies, we employ a mixture-of-experts network (MEN) and observe that the performance of a policy improves if each expert of a MEN specializes in controlling exactly one mode of a hybrid system, such as a walking robot. We introduce new loss functions for single- and multi-gait policies to achieve this kind of expert selection behavior. Moreover, we benchmark our algorithm against Behavioral Cloning and the original MPC implementation on various rough terrain scenarios. We validate our approach on hardware and show that a single learned policy can replace its teacher to control multiple gaits.
Contact-Implicit Trajectory Optimization for Dynamic Object Manipulation
Mar 01, 2021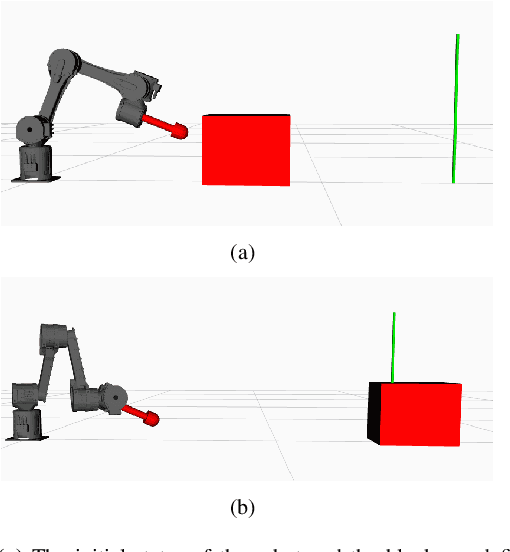

We present a reformulation of a contact-implicit optimization (CIO) approach that computes optimal trajectories for rigid-body systems in contact-rich settings. A hard-contact model is assumed, and the unilateral constraints are imposed in the form of complementarity conditions. Newton's impact law is adopted for enhanced physical correctness. The optimal control problem is formulated as a multi-staged program through a multiple-shooting scheme. This problem structure is exploited within the FORCES Pro framework to retrieve optimal motion plans, contact sequences and control inputs with increased computational efficiency. We investigate our method on a variety of dynamic object manipulation tasks, performed by a six degrees of freedom robot. The dynamic feasibility of the optimal trajectories, as well as the repeatability and accuracy of the task-satisfaction are verified through simulations and real hardware experiments on one of the manipulation problems.
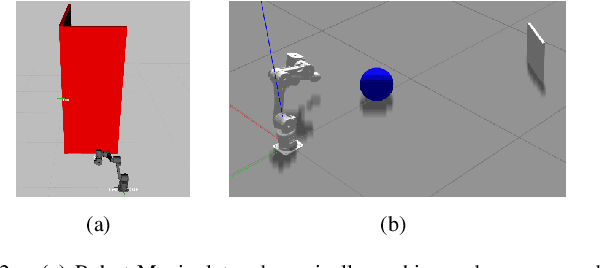
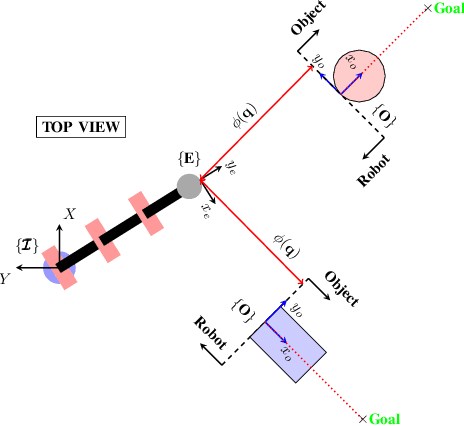
MPC-Net: A First Principles Guided Policy Search
Sep 11, 2019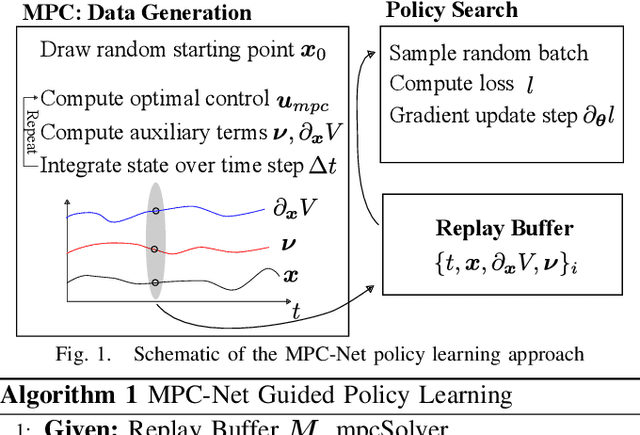
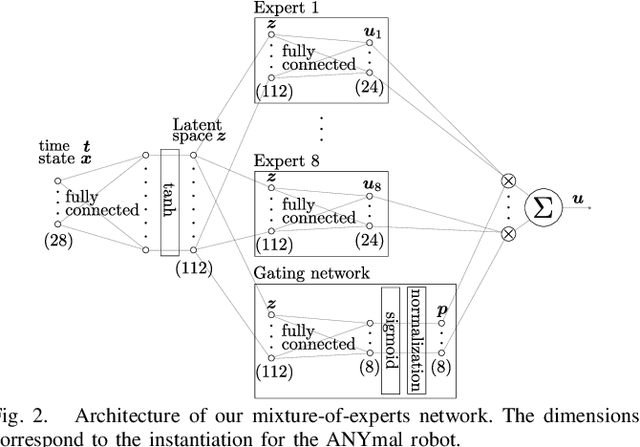

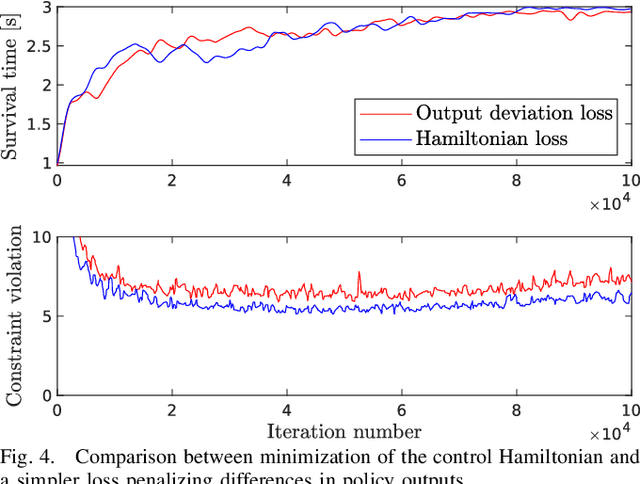
We present an Imitation Learning approach for the control of dynamical systems with a known model. Our policy search method is guided by solutions from Model Predictive Control (MPC). Contrary to approaches that minimize a distance metric between the guiding demonstrations and the learned policy, our loss function corresponds to the minimization of the control Hamiltonian, which derives from the principle of optimality. Our algorithm, therefore, directly attempts to solve the HJB optimality equation with a parameterized class of control laws. The loss function's explicit encoding of physical constraints manifests in an improved constraint satisfaction metric of the learned controller. We train a mixture-of-expert neural network architecture for controlling a quadrupedal robot and show that this policy structure is well suited for such multimodal systems. The learned policy can successfully stabilize different gaits on the real walking robot from less than 10 min of demonstration data.
Locomotion Planning through a Hybrid Bayesian Trajectory Optimization
Mar 09, 2019
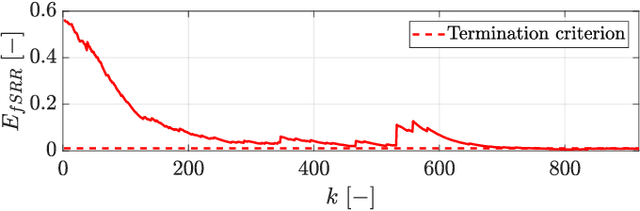
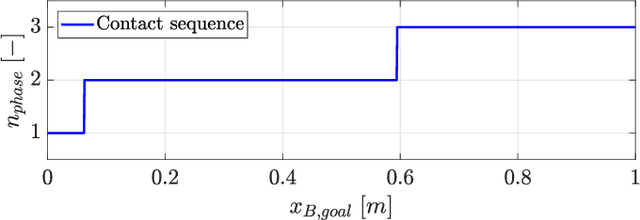
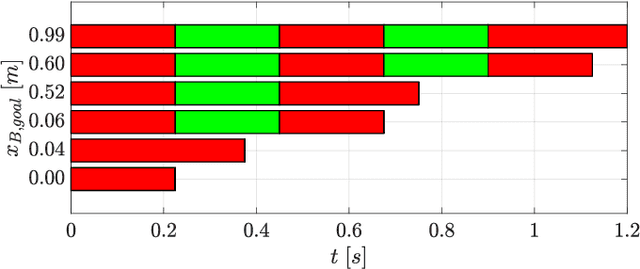
Locomotion planning for legged systems requires reasoning about suitable contact schedules. The contact sequence and timings constitute a hybrid dynamical system and prescribe a subset of achievable motions. State-of-the-art approaches cast motion planning as an optimal control problem. In order to decrease computational complexity, one common strategy separates footstep planning from motion optimization and plans contacts using heuristics. In this paper, we propose to learn contact schedule selection from high-level task descriptors using Bayesian optimization. A bi-level optimization is defined in which a Gaussian process model predicts the performance of trajectories generated by a motion planning nonlinear program. The agent, therefore, retains the ability to reason about suitable contact schedules, while explicit computation of the corresponding gradients is avoided. We delineate the algorithm in its general form and provide results for planning single-legged hopping. Our method is capable of learning contact schedule transitions that align with human intuition. It performs competitively against a heuristic baseline in predicting task appropriate contact schedules.
Whole-Body Nonlinear Model Predictive Control Through Contacts for Quadrupeds
Dec 07, 2017
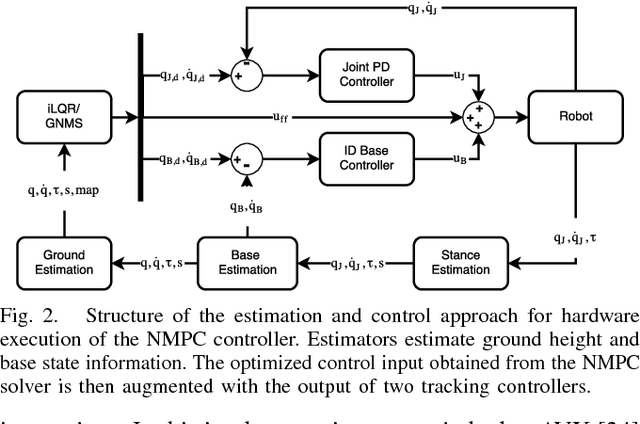
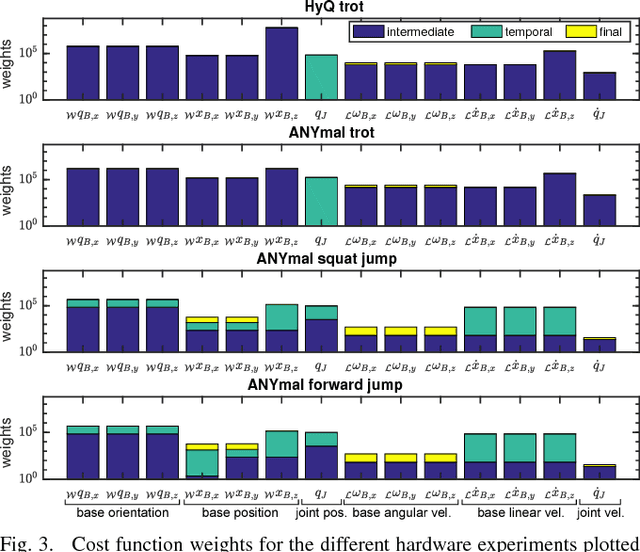
In this work we present a whole-body Nonlinear Model Predictive Control approach for Rigid Body Systems subject to contacts. We use a full dynamic system model which also includes explicit contact dynamics. Therefore, contact locations, sequences and timings are not prespecified but optimized by the solver. Yet, thorough numerical and software engineering allows for running the nonlinear Optimal Control solver at rates up to 190 Hz on a quadruped for a time horizon of half a second. This outperforms the state of the art by at least one order of magnitude. Hardware experiments in form of periodic and non-periodic tasks are applied to two quadrupeds with different actuation systems. The obtained results underline the performance, transferability and robustness of the approach.