 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLENS: Global Search via Learning from Solver Iterates with Diffusion Models
May 29, 2026We consider the problem of generating a large collection of initial guesses for local minima of multimodal non-convex continuous optimization problems. The goal is for these initial guesses to be high-quality (i.e., a numerical solver converges quickly) and diverse (i.e., represent many different local minima). Identifying multiple locally optimal solutions enables flexible downstream decision-making, but typically requires expensive global search. Existing data-driven methods predict initial guesses using only the final converged optima from offline solver runs, which discards information about the local neighborhoods of solutions and limits the available training data. We propose GLENS (Global Search via Learning from Solver Iterates), a data-efficient global search method that leverages intermediate solver iterates as free data augmentation. GLENS consists of two components: a neighborhood structure model that uses diffusion models to learn the local geometry around optima conditioned on problem parameters, and a solver behavior model that learns refinement directions to further guide samples towards nearby optima during diffusion sampling. Experiments on modified non-convex benchmark problems and a two-robot obstacle-avoidance navigation problem show that GLENS generates high-quality initial guesses while preserving the multimodal distribution of diverse local optima. The resulting initial guesses lead to faster solver convergence across different problem settings and solvers. We also analyze how key hyperparameter choices affect the performance.
Distributionally-Robust Learning to Optimize
May 07, 2026We propose a distributionally robust approach to learning hyperparameters for first-order methods in convex optimization. Given a dataset of problem instances, we minimize a Wasserstein distributionally robust version of the performance estimation problem (PEP) over algorithm parameters such as step sizes. Our framework unifies two extremes: as the robustness radius vanishes, we recover classical learning to optimize (L2O); as it grows, we recover worst-case optimal algorithm design via PEP. We solve the resulting problem with stochastic gradient descent, differentiating through the solution of an inner semidefinite program at each step. We prove high-probability bounds showing that the true risk of the learned algorithm is at most the in-sample L2O optimum plus a slack that shrinks with the sample size, and is no worse than the worst-case PEP bound. On unconstrained quadratic minimization, LASSO, and linear programming benchmarks, our learned algorithms achieve strong out-of-sample performance with certifiable robustness, outperforming both worst-case optimal and vanilla L2O baselines.
Batched First-Order Methods for Parallel LP Solving in MIP
Jan 29, 2026We present a batched first-order method for solving multiple linear programs in parallel on GPUs. Our approach extends the primal-dual hybrid gradient algorithm to efficiently solve batches of related linear programming problems that arise in mixed-integer programming techniques such as strong branching and bound tightening. By leveraging matrix-matrix operations instead of repeated matrix-vector operations, we obtain significant computational advantages on GPU architectures. We demonstrate the effectiveness of our approach on various case studies and identify the problem sizes where first-order methods outperform traditional simplex-based solvers depending on the computational environment one can use. This is a significant step for the design and development of integer programming algorithms tightly exploiting GPU capabilities where we argue that some specific operations should be allocated to GPUs and performed in full instead of using light-weight heuristic approaches on CPUs.
Learning Algorithm Hyperparameters for Fast Parametric Convex Optimization
Nov 24, 2024



We introduce a machine-learning framework to learn the hyperparameter sequence of first-order methods (e.g., the step sizes in gradient descent) to quickly solve parametric convex optimization problems. Our computational architecture amounts to running fixed-point iterations where the hyperparameters are the same across all parametric instances and consists of two phases. In the first step-varying phase the hyperparameters vary across iterations, while in the second steady-state phase the hyperparameters are constant across iterations. Our learned optimizer is flexible in that it can be evaluated on any number of iterations and is guaranteed to converge to an optimal solution. To train, we minimize the mean square error to a ground truth solution. In the case of gradient descent, the one-step optimal step size is the solution to a least squares problem, and in the case of unconstrained quadratic minimization, we can compute the two and three-step optimal solutions in closed-form. In other cases, we backpropagate through the algorithm steps to minimize the training objective after a given number of steps. We show how to learn hyperparameters for several popular algorithms: gradient descent, proximal gradient descent, and two ADMM-based solvers: OSQP and SCS. We use a sample convergence bound to obtain generalization guarantees for the performance of our learned algorithm for unseen data, providing both lower and upper bounds. We showcase the effectiveness of our method with many examples, including ones from control, signal processing, and machine learning. Remarkably, our approach is highly data-efficient in that we only use $10$ problem instances to train the hyperparameters in all of our examples.
Data-Driven Performance Guarantees for Classical and Learned Optimizers
Apr 22, 2024



We introduce a data-driven approach to analyze the performance of continuous optimization algorithms using generalization guarantees from statistical learning theory. We study classical and learned optimizers to solve families of parametric optimization problems. We build generalization guarantees for classical optimizers, using a sample convergence bound, and for learned optimizers, using the Probably Approximately Correct (PAC)-Bayes framework. To train learned optimizers, we use a gradient-based algorithm to directly minimize the PAC-Bayes upper bound. Numerical experiments in signal processing, control, and meta-learning showcase the ability of our framework to provide strong generalization guarantees for both classical and learned optimizers given a fixed budget of iterations. For classical optimizers, our bounds are much tighter than those that worst-case guarantees provide. For learned optimizers, our bounds outperform the empirical outcomes observed in their non-learned counterparts.
A neural network-based approach to hybrid systems identification for control
Apr 02, 2024We consider the problem of designing a machine learning-based model of an unknown dynamical system from a finite number of (state-input)-successor state data points, such that the model obtained is also suitable for optimal control design. We propose a specific neural network (NN) architecture that yields a hybrid system with piecewise-affine dynamics that is differentiable with respect to the network's parameters, thereby enabling the use of derivative-based training procedures. We show that a careful choice of our NN's weights produces a hybrid system model with structural properties that are highly favourable when used as part of a finite horizon optimal control problem (OCP). Specifically, we show that optimal solutions with strong local optimality guarantees can be computed via nonlinear programming, in contrast to classical OCPs for general hybrid systems which typically require mixed-integer optimization. In addition to being well-suited for optimal control design, numerical simulations illustrate that our NN-based technique enjoys very similar performance to state-of-the-art system identification methodologies for hybrid systems and it is competitive on nonlinear benchmarks.
Learning Hierarchical Control For Multi-Agent Capacity-Constrained Systems
Mar 22, 2024
This paper introduces a novel data-driven hierarchical control scheme for managing a fleet of nonlinear, capacity-constrained autonomous agents in an iterative environment. We propose a control framework consisting of a high-level dynamic task assignment and routing layer and low-level motion planning and tracking layer. Each layer of the control hierarchy uses a data-driven Model Predictive Control (MPC) policy, maintaining bounded computational complexity at each calculation of a new task assignment or actuation input. We utilize collected data to iteratively refine estimates of agent capacity usage, and update MPC policy parameters accordingly. Our approach leverages tools from iterative learning control to integrate learning at both levels of the hierarchy, and coordinates learning between levels in order to maintain closed-loop feasibility and performance improvement of the connected architecture.
Who Plays First? Optimizing the Order of Play in Stackelberg Games with Many Robots
Feb 14, 2024



We consider the multi-agent spatial navigation problem of computing the socially optimal order of play, i.e., the sequence in which the agents commit to their decisions, and its associated equilibrium in an N-player Stackelberg trajectory game. We model this problem as a mixed-integer optimization problem over the space of all possible Stackelberg games associated with the order of play's permutations. To solve the problem, we introduce Branch and Play (B&P), an efficient and exact algorithm that provably converges to a socially optimal order of play and its Stackelberg equilibrium. As a subroutine for B&P, we employ and extend sequential trajectory planning, i.e., a popular multi-agent control approach, to scalably compute valid local Stackelberg equilibria for any given order of play. We demonstrate the practical utility of B&P to coordinate air traffic control, swarm formation, and delivery vehicle fleets. We find that B&P consistently outperforms various baselines, and computes the socially optimal equilibrium.
Differentiable Cutting-plane Layers for Mixed-integer Linear Optimization
Nov 09, 2023
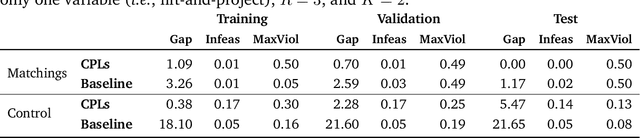


We consider the problem of solving a family of parametric mixed-integer linear optimization problems where some entries in the input data change. We introduce the concept of cutting-plane layer (CPL), i.e., a differentiable cutting-plane generator mapping the problem data and previous iterates to cutting planes. We propose a CPL implementation to generate split cuts, and by combining several CPLs, we devise a differentiable cutting-plane algorithm that exploits the repeated nature of parametric instances. In an offline phase, we train our algorithm by updating the internal parameters controlling the CPLs, thus altering cut generation. Once trained, our algorithm computes, with predictable execution times and a fixed number of cuts, solutions with low integrality gaps. Preliminary computational tests show that our algorithm generalizes on unseen instances and captures underlying parametric structures.
Learning to Warm-Start Fixed-Point Optimization Algorithms
Sep 14, 2023



We introduce a machine-learning framework to warm-start fixed-point optimization algorithms. Our architecture consists of a neural network mapping problem parameters to warm starts, followed by a predefined number of fixed-point iterations. We propose two loss functions designed to either minimize the fixed-point residual or the distance to a ground truth solution. In this way, the neural network predicts warm starts with the end-to-end goal of minimizing the downstream loss. An important feature of our architecture is its flexibility, in that it can predict a warm start for fixed-point algorithms run for any number of steps, without being limited to the number of steps it has been trained on. We provide PAC-Bayes generalization bounds on unseen data for common classes of fixed-point operators: contractive, linearly convergent, and averaged. Applying this framework to well-known applications in control, statistics, and signal processing, we observe a significant reduction in the number of iterations and solution time required to solve these problems, through learned warm starts.