 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Verification of Controllers under State Uncertainty via Hamilton-Jacobi Reachability Analysis
Nov 18, 2025As perception-based controllers for autonomous systems become increasingly popular in the real world, it is important that we can formally verify their safety and performance despite perceptual uncertainty. Unfortunately, the verification of such systems remains challenging, largely due to the complexity of the controllers, which are often nonlinear, nonconvex, learning-based, and/or black-box. Prior works propose verification algorithms that are based on approximate reachability methods, but they often restrict the class of controllers and systems that can be handled or result in overly conservative analyses. Hamilton-Jacobi (HJ) reachability analysis is a popular formal verification tool for general nonlinear systems that can compute optimal reachable sets under worst-case system uncertainties; however, its application to perception-based systems is currently underexplored. In this work, we propose RoVer-CoRe, a framework for the Robust Verification of Controllers via HJ Reachability. To the best of our knowledge, RoVer-CoRe is the first HJ reachability-based framework for the verification of perception-based systems under perceptual uncertainty. Our key insight is to concatenate the system controller, observation function, and the state estimation modules to obtain an equivalent closed-loop system that is readily compatible with existing reachability frameworks. Within RoVer-CoRe, we propose novel methods for formal safety verification and robust controller design. We demonstrate the efficacy of the framework in case studies involving aircraft taxiing and NN-based rover navigation. Code is available at the link in the footnote.
Learning Hierarchical Control For Multi-Agent Capacity-Constrained Systems
Mar 22, 2024
This paper introduces a novel data-driven hierarchical control scheme for managing a fleet of nonlinear, capacity-constrained autonomous agents in an iterative environment. We propose a control framework consisting of a high-level dynamic task assignment and routing layer and low-level motion planning and tracking layer. Each layer of the control hierarchy uses a data-driven Model Predictive Control (MPC) policy, maintaining bounded computational complexity at each calculation of a new task assignment or actuation input. We utilize collected data to iteratively refine estimates of agent capacity usage, and update MPC policy parameters accordingly. Our approach leverages tools from iterative learning control to integrate learning at both levels of the hierarchy, and coordinates learning between levels in order to maintain closed-loop feasibility and performance improvement of the connected architecture.
Assurance for Autonomy -- JPL's past research, lessons learned, and future directions
May 16, 2023Robotic space missions have long depended on automation, defined in the 2015 NASA Technology Roadmaps as "the automatically-controlled operation of an apparatus, process, or system using a pre-planned set of instructions (e.g., a command sequence)," to react to events when a rapid response is required. Autonomy, defined there as "the capacity of a system to achieve goals while operating independently from external control," is required when a wide variation in circumstances precludes responses being pre-planned, instead autonomy follows an on-board deliberative process to determine the situation, decide the response, and manage its execution. Autonomy is increasingly called for to support adventurous space mission concepts, as an enabling capability or as a significant enhancer of the science value that those missions can return. But if autonomy is to be allowed to control these missions' expensive assets, all parties in the lifetime of a mission, from proposers through ground control, must have high confidence that autonomy will perform as intended to keep the asset safe to (if possible) accomplish the mission objectives. The role of mission assurance is a key contributor to providing this confidence, yet assurance practices honed over decades of spaceflight have relatively little experience with autonomy. To remedy this situation, researchers in JPL's software assurance group have been involved in the development of techniques specific to the assurance of autonomy. This paper summarizes over two decades of this research, and offers a vision of where further work is needed to address open issues.
An ROS-based Shared Communication Middleware for Plug & Play Modular Intelligent Design of Smart Systems
Jun 04, 2017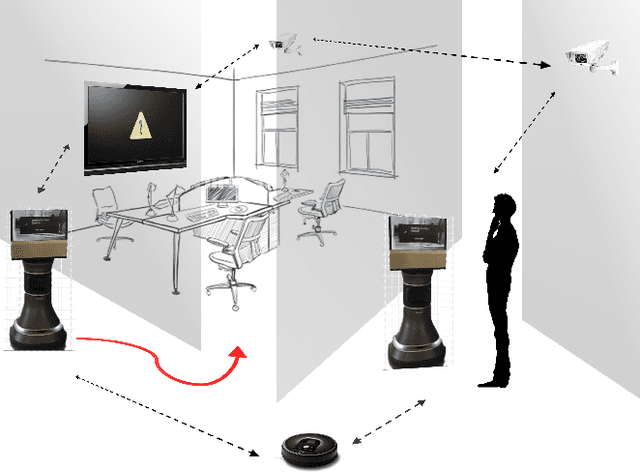

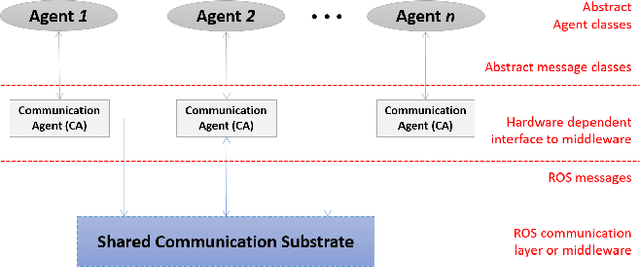
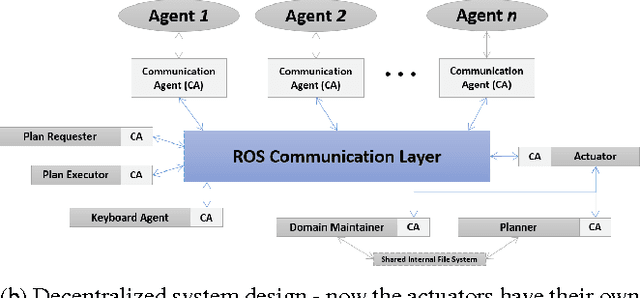
Centralized architectures for systems such as smart offices and homes are rapidly becoming obsolete due to inherent inflexibility in their design and management. This is because such systems should not only be easily re-configurable with the addition of newer capabilities over time but should also have the ability to adapt to multiple points of failure. Fully harnessing the capabilities of these massively integrated systems requires higher level reasoning engines that allow them to plan for and achieve diverse long-term goals, rather than being limited to a few predefined tasks. In this paper, we propose a set of properties that will accommodate such capabilities, and develop a general architecture for integrating automated planning components into smart systems. We show how the reasoning capabilities are embedded in the design and operation of the system and demonstrate the same on a real-world implementation of a smart office.
Probabilistically Safe Vehicle Control in a Hostile Environment
Mar 24, 2011
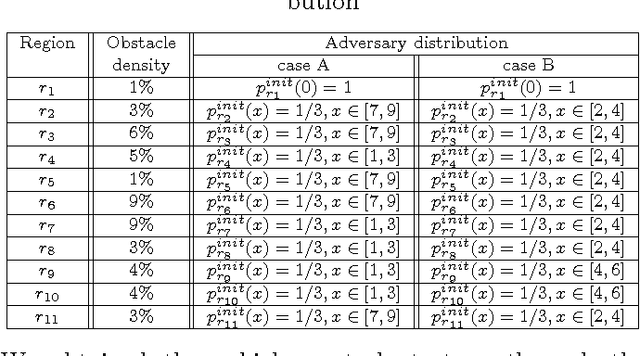

In this paper we present an approach to control a vehicle in a hostile environment with static obstacles and moving adversaries. The vehicle is required to satisfy a mission objective expressed as a temporal logic specification over a set of properties satisfied at regions of a partitioned environment. We model the movements of adversaries in between regions of the environment as Poisson processes. Furthermore, we assume that the time it takes for the vehicle to traverse in between two facets of each region is exponentially distributed, and we obtain the rate of this exponential distribution from a simulator of the environment. We capture the motion of the vehicle and the vehicle updates of adversaries distributions as a Markov Decision Process. Using tools in Probabilistic Computational Tree Logic, we find a control strategy for the vehicle that maximizes the probability of accomplishing the mission objective. We demonstrate our approach with illustrative case studies.