 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Algorithm Hyperparameters for Fast Parametric Convex Optimization
Nov 24, 2024



We introduce a machine-learning framework to learn the hyperparameter sequence of first-order methods (e.g., the step sizes in gradient descent) to quickly solve parametric convex optimization problems. Our computational architecture amounts to running fixed-point iterations where the hyperparameters are the same across all parametric instances and consists of two phases. In the first step-varying phase the hyperparameters vary across iterations, while in the second steady-state phase the hyperparameters are constant across iterations. Our learned optimizer is flexible in that it can be evaluated on any number of iterations and is guaranteed to converge to an optimal solution. To train, we minimize the mean square error to a ground truth solution. In the case of gradient descent, the one-step optimal step size is the solution to a least squares problem, and in the case of unconstrained quadratic minimization, we can compute the two and three-step optimal solutions in closed-form. In other cases, we backpropagate through the algorithm steps to minimize the training objective after a given number of steps. We show how to learn hyperparameters for several popular algorithms: gradient descent, proximal gradient descent, and two ADMM-based solvers: OSQP and SCS. We use a sample convergence bound to obtain generalization guarantees for the performance of our learned algorithm for unseen data, providing both lower and upper bounds. We showcase the effectiveness of our method with many examples, including ones from control, signal processing, and machine learning. Remarkably, our approach is highly data-efficient in that we only use $10$ problem instances to train the hyperparameters in all of our examples.
Data-Driven Performance Guarantees for Classical and Learned Optimizers
Apr 22, 2024



We introduce a data-driven approach to analyze the performance of continuous optimization algorithms using generalization guarantees from statistical learning theory. We study classical and learned optimizers to solve families of parametric optimization problems. We build generalization guarantees for classical optimizers, using a sample convergence bound, and for learned optimizers, using the Probably Approximately Correct (PAC)-Bayes framework. To train learned optimizers, we use a gradient-based algorithm to directly minimize the PAC-Bayes upper bound. Numerical experiments in signal processing, control, and meta-learning showcase the ability of our framework to provide strong generalization guarantees for both classical and learned optimizers given a fixed budget of iterations. For classical optimizers, our bounds are much tighter than those that worst-case guarantees provide. For learned optimizers, our bounds outperform the empirical outcomes observed in their non-learned counterparts.
Learning to Warm-Start Fixed-Point Optimization Algorithms
Sep 14, 2023



We introduce a machine-learning framework to warm-start fixed-point optimization algorithms. Our architecture consists of a neural network mapping problem parameters to warm starts, followed by a predefined number of fixed-point iterations. We propose two loss functions designed to either minimize the fixed-point residual or the distance to a ground truth solution. In this way, the neural network predicts warm starts with the end-to-end goal of minimizing the downstream loss. An important feature of our architecture is its flexibility, in that it can predict a warm start for fixed-point algorithms run for any number of steps, without being limited to the number of steps it has been trained on. We provide PAC-Bayes generalization bounds on unseen data for common classes of fixed-point operators: contractive, linearly convergent, and averaged. Applying this framework to well-known applications in control, statistics, and signal processing, we observe a significant reduction in the number of iterations and solution time required to solve these problems, through learned warm starts.
Lifted Neural Networks
Jun 21, 2018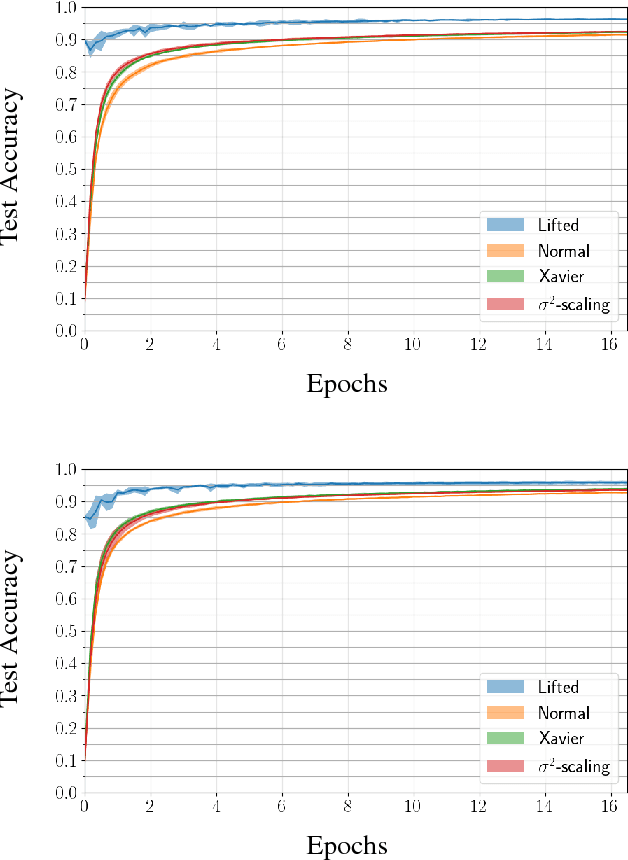
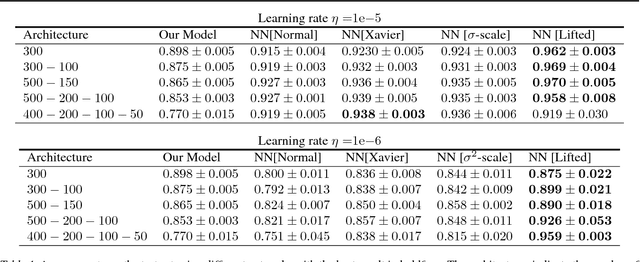
We describe a novel family of models of multi- layer feedforward neural networks in which the activation functions are encoded via penalties in the training problem. Our approach is based on representing a non-decreasing activation function as the argmin of an appropriate convex optimiza- tion problem. The new framework allows for algo- rithms such as block-coordinate descent methods to be applied, in which each step is composed of a simple (no hidden layer) supervised learning problem that is parallelizable across data points and/or layers. Experiments indicate that the pro- posed models provide excellent initial guesses for weights for standard neural networks. In addi- tion, the model provides avenues for interesting extensions, such as robustness against noisy in- puts and optimizing over parameters in activation functions.