 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Insights Driven Latent Space for Different Driving Perspectives: A Unified Encoder for Efficient Multi-Task Inference
Sep 16, 2024



Autonomous driving holds great potential to transform road safety and traffic efficiency by minimizing human error and reducing congestion. A key challenge in realizing this potential is the accurate estimation of steering angles, which is essential for effective vehicle navigation and control. Recent breakthroughs in deep learning have made it possible to estimate steering angles directly from raw camera inputs. However, the limited available navigation data can hinder optimal feature learning, impacting the system's performance in complex driving scenarios. In this paper, we propose a shared encoder trained on multiple computer vision tasks critical for urban navigation, such as depth, pose, and 3D scene flow estimation, as well as semantic, instance, panoptic, and motion segmentation. By incorporating diverse visual information used by humans during navigation, this unified encoder might enhance steering angle estimation. To achieve effective multi-task learning within a single encoder, we introduce a multi-scale feature network for pose estimation to improve depth learning. Additionally, we employ knowledge distillation from a multi-backbone model pretrained on these navigation tasks to stabilize training and boost performance. Our findings demonstrate that a shared backbone trained on diverse visual tasks is capable of providing overall perception capabilities. While our performance in steering angle estimation is comparable to existing methods, the integration of human-like perception through multi-task learning holds significant potential for advancing autonomous driving systems. More details and the pretrained model are available at https://hi-computervision.github.io/uni-encoder/.
Exploring Latent Pathways: Enhancing the Interpretability of Autonomous Driving with a Variational Autoencoder
Apr 02, 2024Autonomous driving presents a complex challenge, which is usually addressed with artificial intelligence models that are end-to-end or modular in nature. Within the landscape of modular approaches, a bio-inspired neural circuit policy model has emerged as an innovative control module, offering a compact and inherently interpretable system to infer a steering wheel command from abstract visual features. Here, we take a leap forward by integrating a variational autoencoder with the neural circuit policy controller, forming a solution that directly generates steering commands from input camera images. By substituting the traditional convolutional neural network approach to feature extraction with a variational autoencoder, we enhance the system's interpretability, enabling a more transparent and understandable decision-making process. In addition to the architectural shift toward a variational autoencoder, this study introduces the automatic latent perturbation tool, a novel contribution designed to probe and elucidate the latent features within the variational autoencoder. The automatic latent perturbation tool automates the interpretability process, offering granular insights into how specific latent variables influence the overall model's behavior. Through a series of numerical experiments, we demonstrate the interpretative power of the variational autoencoder-neural circuit policy model and the utility of the automatic latent perturbation tool in making the inner workings of autonomous driving systems more transparent.
Astronomical image time series classification using CONVolutional attENTION (ConvEntion)
Apr 03, 2023
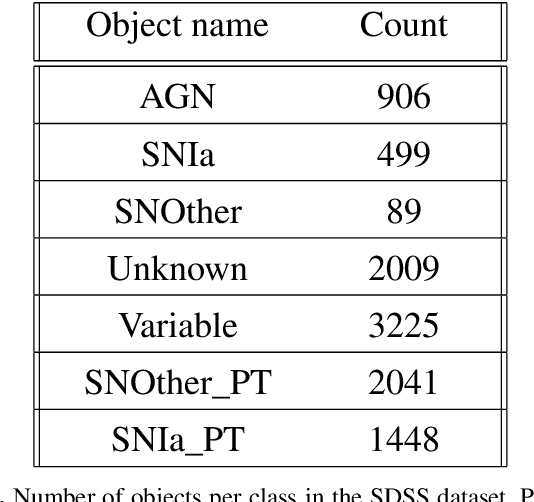
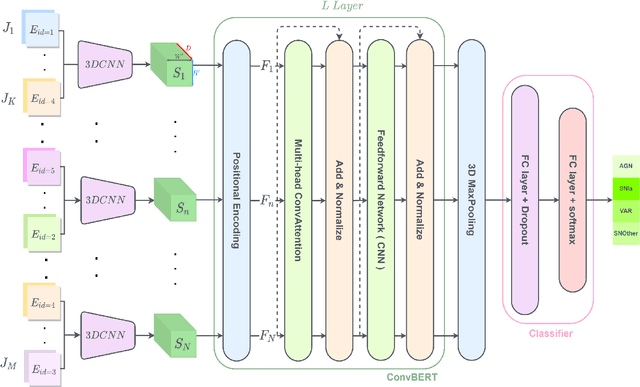
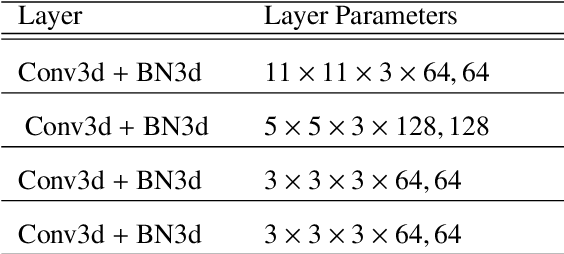
Aims. The treatment of astronomical image time series has won increasing attention in recent years. Indeed, numerous surveys following up on transient objects are in progress or under construction, such as the Vera Rubin Observatory Legacy Survey for Space and Time (LSST), which is poised to produce huge amounts of these time series. The associated scientific topics are extensive, ranging from the study of objects in our galaxy to the observation of the most distant supernovae for measuring the expansion of the universe. With such a large amount of data available, the need for robust automatic tools to detect and classify celestial objects is growing steadily. Methods. This study is based on the assumption that astronomical images contain more information than light curves. In this paper, we propose a novel approach based on deep learning for classifying different types of space objects directly using images. We named our approach ConvEntion, which stands for CONVolutional attENTION. It is based on convolutions and transformers, which are new approaches for the treatment of astronomical image time series. Our solution integrates spatio-temporal features and can be applied to various types of image datasets with any number of bands. Results. In this work, we solved various problems the datasets tend to suffer from and we present new results for classifications using astronomical image time series with an increase in accuracy of 13%, compared to state-of-the-art approaches that use image time series, and a 12% increase, compared to approaches that use light curves.