 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Steering Estimation with Semantic-Aware GNNs
Mar 21, 2025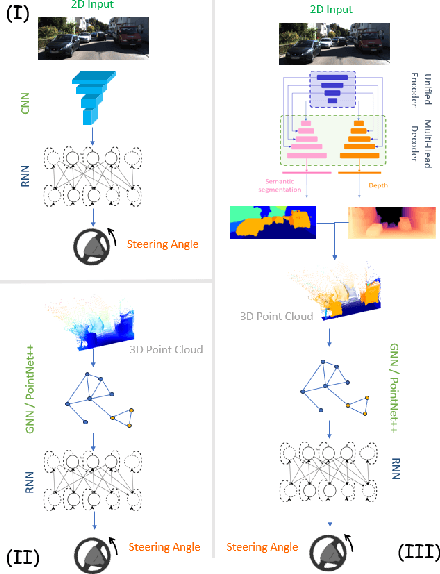
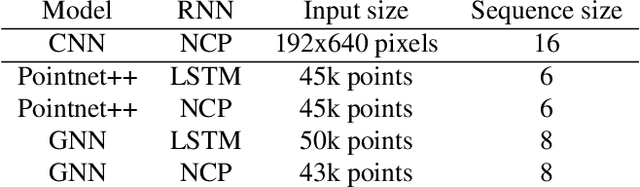

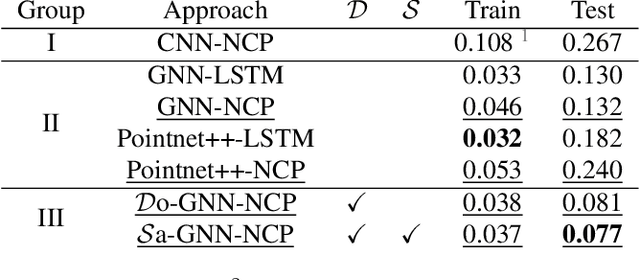
Steering estimation is a critical task in autonomous driving, traditionally relying on 2D image-based models. In this work, we explore the advantages of incorporating 3D spatial information through hybrid architectures that combine 3D neural network models with recurrent neural networks (RNNs) for temporal modeling, using LiDAR-based point clouds as input. We systematically evaluate four hybrid 3D models, all of which outperform the 2D-only baseline, with the Graph Neural Network (GNN) - RNN model yielding the best results. To reduce reliance on LiDAR, we leverage a pretrained unified model to estimate depth from monocular images, reconstructing pseudo-3D point clouds. We then adapt the GNN-RNN model, originally designed for LiDAR-based point clouds, to work with these pseudo-3D representations, achieving comparable or even superior performance compared to the LiDAR-based model. Additionally, the unified model provides semantic labels for each point, enabling a more structured scene representation. To further optimize graph construction, we introduce an efficient connectivity strategy where connections are predominantly formed between points of the same semantic class, with only 20\% of inter-class connections retained. This targeted approach reduces graph complexity and computational cost while preserving critical spatial relationships. Finally, we validate our approach on the KITTI dataset, achieving a 71% improvement over 2D-only models. Our findings highlight the advantages of 3D spatial information and efficient graph construction for steering estimation, while maintaining the cost-effectiveness of monocular images and avoiding the expense of LiDAR-based systems.
Human Insights Driven Latent Space for Different Driving Perspectives: A Unified Encoder for Efficient Multi-Task Inference
Sep 16, 2024



Autonomous driving holds great potential to transform road safety and traffic efficiency by minimizing human error and reducing congestion. A key challenge in realizing this potential is the accurate estimation of steering angles, which is essential for effective vehicle navigation and control. Recent breakthroughs in deep learning have made it possible to estimate steering angles directly from raw camera inputs. However, the limited available navigation data can hinder optimal feature learning, impacting the system's performance in complex driving scenarios. In this paper, we propose a shared encoder trained on multiple computer vision tasks critical for urban navigation, such as depth, pose, and 3D scene flow estimation, as well as semantic, instance, panoptic, and motion segmentation. By incorporating diverse visual information used by humans during navigation, this unified encoder might enhance steering angle estimation. To achieve effective multi-task learning within a single encoder, we introduce a multi-scale feature network for pose estimation to improve depth learning. Additionally, we employ knowledge distillation from a multi-backbone model pretrained on these navigation tasks to stabilize training and boost performance. Our findings demonstrate that a shared backbone trained on diverse visual tasks is capable of providing overall perception capabilities. While our performance in steering angle estimation is comparable to existing methods, the integration of human-like perception through multi-task learning holds significant potential for advancing autonomous driving systems. More details and the pretrained model are available at https://hi-computervision.github.io/uni-encoder/.
Toward Efficient Visual Gyroscopes: Spherical Moments, Harmonics Filtering, and Masking Techniques for Spherical Camera Applications
Apr 02, 2024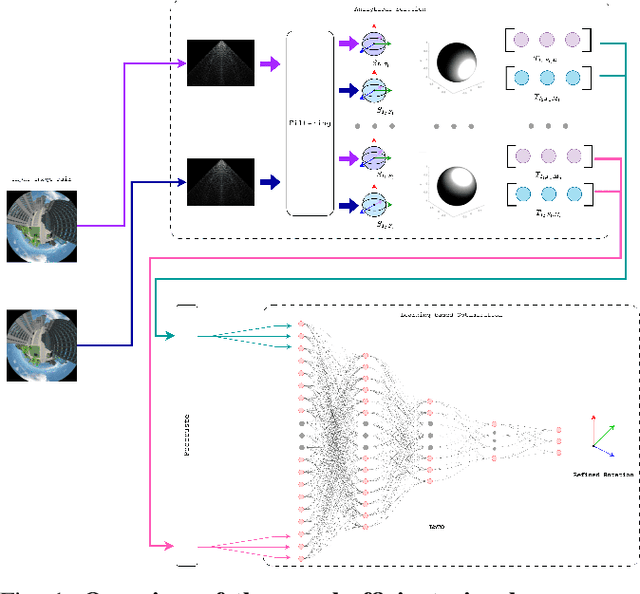



Unlike a traditional gyroscope, a visual gyroscope estimates camera rotation through images. The integration of omnidirectional cameras, offering a larger field of view compared to traditional RGB cameras, has proven to yield more accurate and robust results. However, challenges arise in situations that lack features, have substantial noise causing significant errors, and where certain features in the images lack sufficient strength, leading to less precise prediction results. Here, we address these challenges by introducing a novel visual gyroscope, which combines an analytical method with a neural network approach to provide a more efficient and accurate rotation estimation from spherical images. The presented method relies on three key contributions: an adapted analytical approach to compute the spherical moments coefficients, introduction of masks for better global feature representation, and the use of a multilayer perceptron to adaptively choose the best combination of masks and filters. Experimental results demonstrate superior performance of the proposed approach in terms of accuracy. The paper emphasizes the advantages of integrating machine learning to optimize analytical solutions, discusses limitations, and suggests directions for future research.
Exploring Latent Pathways: Enhancing the Interpretability of Autonomous Driving with a Variational Autoencoder
Apr 02, 2024Autonomous driving presents a complex challenge, which is usually addressed with artificial intelligence models that are end-to-end or modular in nature. Within the landscape of modular approaches, a bio-inspired neural circuit policy model has emerged as an innovative control module, offering a compact and inherently interpretable system to infer a steering wheel command from abstract visual features. Here, we take a leap forward by integrating a variational autoencoder with the neural circuit policy controller, forming a solution that directly generates steering commands from input camera images. By substituting the traditional convolutional neural network approach to feature extraction with a variational autoencoder, we enhance the system's interpretability, enabling a more transparent and understandable decision-making process. In addition to the architectural shift toward a variational autoencoder, this study introduces the automatic latent perturbation tool, a novel contribution designed to probe and elucidate the latent features within the variational autoencoder. The automatic latent perturbation tool automates the interpretability process, offering granular insights into how specific latent variables influence the overall model's behavior. Through a series of numerical experiments, we demonstrate the interpretative power of the variational autoencoder-neural circuit policy model and the utility of the automatic latent perturbation tool in making the inner workings of autonomous driving systems more transparent.
Towards urban scenes understanding through polarization cues
Jun 03, 2021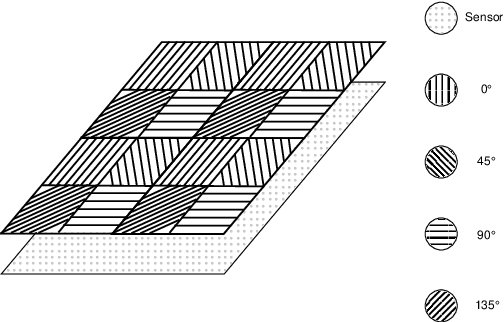

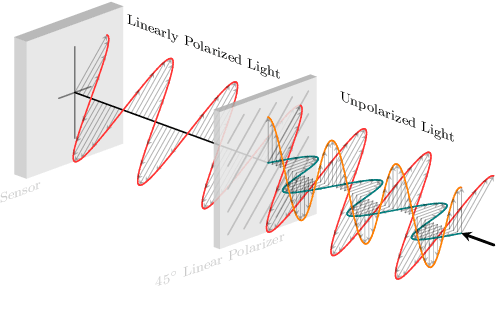
Autonomous robotics is critically affected by the robustness of its scene understanding algorithms. We propose a two-axis pipeline based on polarization indices to analyze dynamic urban scenes. As robots evolve in unknown environments, they are prone to encountering specular obstacles. Usually, specular phenomena are rarely taken into account by algorithms which causes misinterpretations and erroneous estimates. By exploiting all the light properties, systems can greatly increase their robustness to events. In addition to the conventional photometric characteristics, we propose to include polarization sensing. We demonstrate in this paper that the contribution of polarization measurement increases both the performances of segmentation and the quality of depth estimation. Our polarimetry-based approaches are compared here with other state-of-the-art RGB-centric methods showing interest of using polarization imaging.
P2D: a self-supervised method for depth estimation from polarimetry
Jul 15, 2020

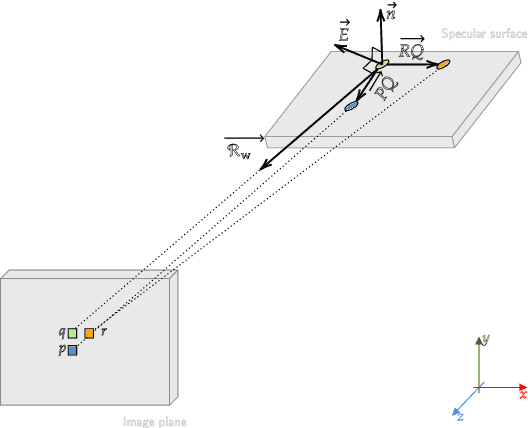
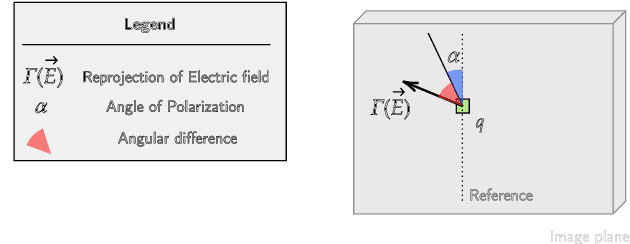
Monocular depth estimation is a recurring subject in the field of computer vision. Its ability to describe scenes via a depth map while reducing the constraints related to the formulation of perspective geometry tends to favor its use. However, despite the constant improvement of algorithms, most methods exploit only colorimetric information. Consequently, robustness to events to which the modality is not sensitive to, like specularity or transparency, is neglected. In response to this phenomenon, we propose using polarimetry as an input for a self-supervised monodepth network. Therefore, we propose exploiting polarization cues to encourage accurate reconstruction of scenes. Furthermore, we include a term of polarimetric regularization to state-of-the-art method to take specific advantage of the data. Our method is evaluated both qualitatively and quantitatively demonstrating that the contribution of this new information as well as an enhanced loss function improves depth estimation results, especially for specular areas.
Polarimetric image augmentation
May 22, 2020


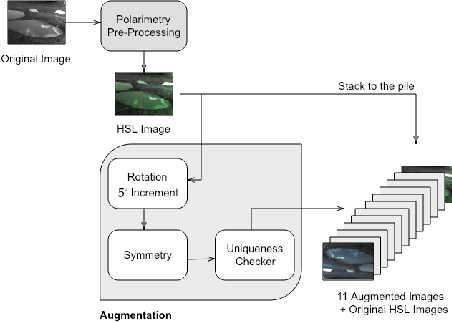
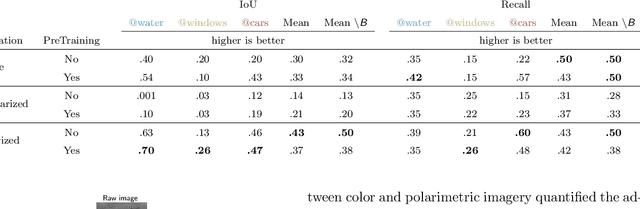
Robotics applications in urban environments are subject to obstacles that exhibit specular reflections hampering autonomous navigation. On the other hand, these reflections are highly polarized and this extra information can successfully be used to segment the specular areas. In nature, polarized light is obtained by reflection or scattering. Deep Convolutional Neural Networks (DCNNs) have shown excellent segmentation results, but require a significant amount of data to achieve best performances. The lack of data is usually overcomed by using augmentation methods. However, unlike RGB images, polarization images are not only scalar (intensity) images and standard augmentation techniques cannot be applied straightforwardly. We propose to enhance deep learning models through a regularized augmentation procedure applied to polarimetric data in order to characterize scenes more effectively under challenging conditions. We subsequently observe an average of 18.1% improvement in IoU between non augmented and regularized training procedures on real world data.