 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAR: Synthesis of Tailored Architectures
Nov 26, 2024Iterative improvement of model architectures is fundamental to deep learning: Transformers first enabled scaling, and recent advances in model hybridization have pushed the quality-efficiency frontier. However, optimizing architectures remains challenging and expensive. Current automated or manual approaches fall short, largely due to limited progress in the design of search spaces and due to the simplicity of resulting patterns and heuristics. In this work, we propose a new approach for the synthesis of tailored architectures (STAR). Our approach combines a novel search space based on the theory of linear input-varying systems, supporting a hierarchical numerical encoding into architecture genomes. STAR genomes are automatically refined and recombined with gradient-free, evolutionary algorithms to optimize for multiple model quality and efficiency metrics. Using STAR, we optimize large populations of new architectures, leveraging diverse computational units and interconnection patterns, improving over highly-optimized Transformers and striped hybrid models on the frontier of quality, parameter size, and inference cache for autoregressive language modeling.
ReIL: A Framework for Reinforced Intervention-based Imitation Learning
Mar 29, 2022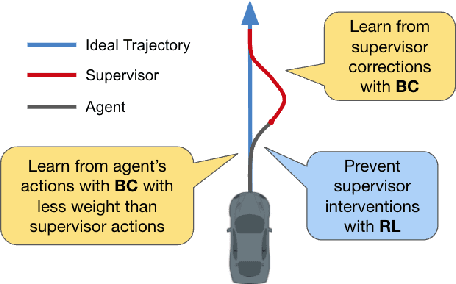
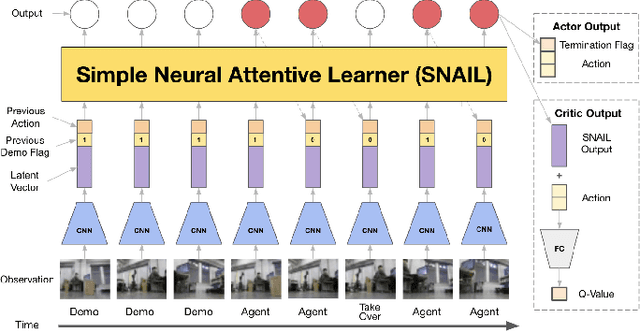


Compared to traditional imitation learning methods such as DAgger and DART, intervention-based imitation offers a more convenient and sample efficient data collection process to users. In this paper, we introduce Reinforced Intervention-based Learning (ReIL), a framework consisting of a general intervention-based learning algorithm and a multi-task imitation learning model aimed at enabling non-expert users to train agents in real environments with little supervision or fine tuning. ReIL achieves this with an algorithm that combines the advantages of imitation learning and reinforcement learning and a model capable of concurrently processing demonstrations, past experience, and current observations. Experimental results from real world mobile robot navigation challenges indicate that ReIL learns rapidly from sparse supervisor corrections without suffering deterioration in performance that is characteristic of supervised learning-based methods such as HG-Dagger and IWR. The results also demonstrate that in contrast to other intervention-based methods such as IARL and EGPO, ReIL can utilize an arbitrary reward function for training without any additional heuristics.