 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMP: One-step Meanflow Policy with Directional Alignment
Dec 22, 2025Robot manipulation, a key capability of embodied AI, has turned to data-driven generative policy frameworks, but mainstream approaches like Diffusion Models suffer from high inference latency and Flow-based Methods from increased architectural complexity. While simply applying meanFlow on robotic tasks achieves single-step inference and outperforms FlowPolicy, it lacks few-shot generalization due to fixed temperature hyperparameters in its Dispersive Loss and misaligned predicted-true mean velocities. To solve these issues, this study proposes an improved MeanFlow-based Policies: we introduce a lightweight Cosine Loss to align velocity directions and use the Differential Derivation Equation (DDE) to optimize the Jacobian-Vector Product (JVP) operator. Experiments on Adroit and Meta-World tasks show the proposed method outperforms MP1 and FlowPolicy in average success rate, especially in challenging Meta-World tasks, effectively enhancing few-shot generalization and trajectory accuracy of robot manipulation policies while maintaining real-time performance, offering a more robust solution for high-precision robotic manipulation.
Holistic Surgical Phase Recognition with Hierarchical Input Dependent State Space Models
Jun 26, 2025Surgical workflow analysis is essential in robot-assisted surgeries, yet the long duration of such procedures poses significant challenges for comprehensive video analysis. Recent approaches have predominantly relied on transformer models; however, their quadratic attention mechanism restricts efficient processing of lengthy surgical videos. In this paper, we propose a novel hierarchical input-dependent state space model that leverages the linear scaling property of state space models to enable decision making on full-length videos while capturing both local and global dynamics. Our framework incorporates a temporally consistent visual feature extractor, which appends a state space model head to a visual feature extractor to propagate temporal information. The proposed model consists of two key modules: a local-aggregation state space model block that effectively captures intricate local dynamics, and a global-relation state space model block that models temporal dependencies across the entire video. The model is trained using a hybrid discrete-continuous supervision strategy, where both signals of discrete phase labels and continuous phase progresses are propagated through the network. Experiments have shown that our method outperforms the current state-of-the-art methods by a large margin (+2.8% on Cholec80, +4.3% on MICCAI2016, and +12.9% on Heichole datasets). Code will be publicly available after paper acceptance.
GenHOI: Generalizing Text-driven 4D Human-Object Interaction Synthesis for Unseen Objects
Jun 18, 2025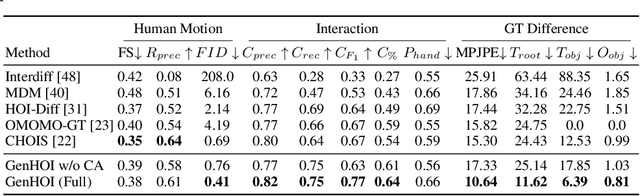
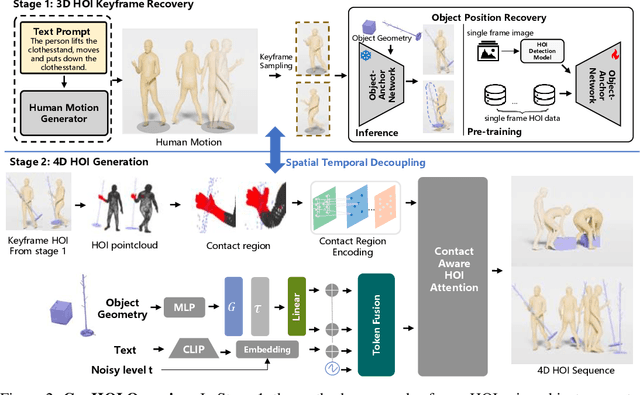
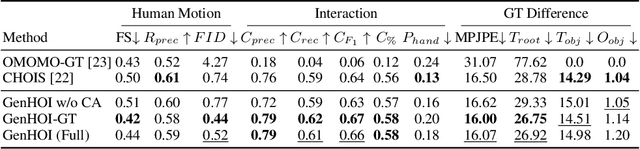
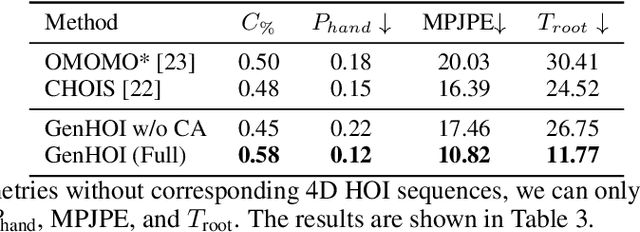
While diffusion models and large-scale motion datasets have advanced text-driven human motion synthesis, extending these advances to 4D human-object interaction (HOI) remains challenging, mainly due to the limited availability of large-scale 4D HOI datasets. In our study, we introduce GenHOI, a novel two-stage framework aimed at achieving two key objectives: 1) generalization to unseen objects and 2) the synthesis of high-fidelity 4D HOI sequences. In the initial stage of our framework, we employ an Object-AnchorNet to reconstruct sparse 3D HOI keyframes for unseen objects, learning solely from 3D HOI datasets, thereby mitigating the dependence on large-scale 4D HOI datasets. Subsequently, we introduce a Contact-Aware Diffusion Model (ContactDM) in the second stage to seamlessly interpolate sparse 3D HOI keyframes into densely temporally coherent 4D HOI sequences. To enhance the quality of generated 4D HOI sequences, we propose a novel Contact-Aware Encoder within ContactDM to extract human-object contact patterns and a novel Contact-Aware HOI Attention to effectively integrate the contact signals into diffusion models. Experimental results show that we achieve state-of-the-art results on the publicly available OMOMO and 3D-FUTURE datasets, demonstrating strong generalization abilities to unseen objects, while enabling high-fidelity 4D HOI generation.
Time Reversal Symmetry for Efficient Robotic Manipulations in Deep Reinforcement Learning
May 20, 2025Symmetry is pervasive in robotics and has been widely exploited to improve sample efficiency in deep reinforcement learning (DRL). However, existing approaches primarily focus on spatial symmetries, such as reflection, rotation, and translation, while largely neglecting temporal symmetries. To address this gap, we explore time reversal symmetry, a form of temporal symmetry commonly found in robotics tasks such as door opening and closing. We propose Time Reversal symmetry enhanced Deep Reinforcement Learning (TR-DRL), a framework that combines trajectory reversal augmentation and time reversal guided reward shaping to efficiently solve temporally symmetric tasks. Our method generates reversed transitions from fully reversible transitions, identified by a proposed dynamics-consistent filter, to augment the training data. For partially reversible transitions, we apply reward shaping to guide learning, according to successful trajectories from the reversed task. Extensive experiments on the Robosuite and MetaWorld benchmarks demonstrate that TR-DRL is effective in both single-task and multi-task settings, achieving higher sample efficiency and stronger final performance compared to baseline methods.
Temporal Propagation of Asymmetric Feature Pyramid for Surgical Scene Segmentation
Apr 18, 2025Surgical scene segmentation is crucial for robot-assisted laparoscopic surgery understanding. Current approaches face two challenges: (i) static image limitations including ambiguous local feature similarities and fine-grained structural details, and (ii) dynamic video complexities arising from rapid instrument motion and persistent visual occlusions. While existing methods mainly focus on spatial feature extraction, they fundamentally overlook temporal dependencies in surgical video streams. To address this, we present temporal asymmetric feature propagation network, a bidirectional attention architecture enabling cross-frame feature propagation. The proposed method contains a temporal query propagator that integrates multi-directional consistency constraints to enhance frame-specific feature representation, and an aggregated asymmetric feature pyramid module that preserves discriminative features for anatomical structures and surgical instruments. Our framework uniquely enables both temporal guidance and contextual reasoning for surgical scene understanding. Comprehensive evaluations on two public benchmarks show the proposed method outperforms the current SOTA methods by a large margin, with +16.4\% mIoU on EndoVis2018 and +3.3\% mAP on Endoscapes2023. The code will be publicly available after paper acceptance.
Tracking-Aware Deformation Field Estimation for Non-rigid 3D Reconstruction in Robotic Surgeries
Mar 04, 2025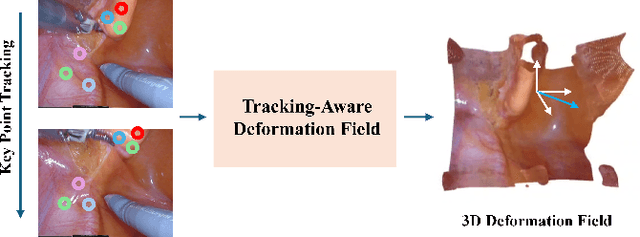



Minimally invasive procedures have been advanced rapidly by the robotic laparoscopic surgery. The latter greatly assists surgeons in sophisticated and precise operations with reduced invasiveness. Nevertheless, it is still safety critical to be aware of even the least tissue deformation during instrument-tissue interactions, especially in 3D space. To address this, recent works rely on NeRF to render 2D videos from different perspectives and eliminate occlusions. However, most of the methods fail to predict the accurate 3D shapes and associated deformation estimates robustly. Differently, we propose Tracking-Aware Deformation Field (TADF), a novel framework which reconstructs the 3D mesh along with the 3D tissue deformation simultaneously. It first tracks the key points of soft tissue by a foundation vision model, providing an accurate 2D deformation field. Then, the 2D deformation field is smoothly incorporated with a neural implicit reconstruction network to obtain tissue deformation in the 3D space. Finally, we experimentally demonstrate that the proposed method provides more accurate deformation estimation compared with other 3D neural reconstruction methods in two public datasets.
Diffusion Stabilizer Policy for Automated Surgical Robot Manipulations
Mar 03, 2025


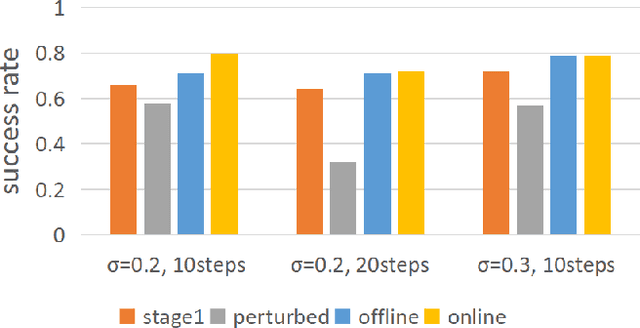
Intelligent surgical robots have the potential to revolutionize clinical practice by enabling more precise and automated surgical procedures. However, the automation of such robot for surgical tasks remains under-explored compared to recent advancements in solving household manipulation tasks. These successes have been largely driven by (1) advanced models, such as transformers and diffusion models, and (2) large-scale data utilization. Aiming to extend these successes to the domain of surgical robotics, we propose a diffusion-based policy learning framework, called Diffusion Stabilizer Policy (DSP), which enables training with imperfect or even failed trajectories. Our approach consists of two stages: first, we train the diffusion stabilizer policy using only clean data. Then, the policy is continuously updated using a mixture of clean and perturbed data, with filtering based on the prediction error on actions. Comprehensive experiments conducted in various surgical environments demonstrate the superior performance of our method in perturbation-free settings and its robustness when handling perturbed demonstrations.
ASAP: Learning Generalizable Online Bin Packing via Adaptive Selection After Pruning
Jan 29, 2025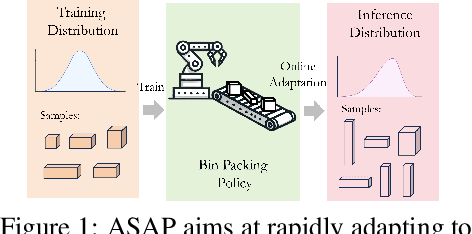

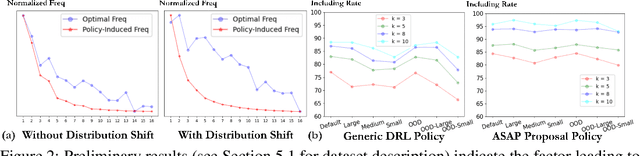

Recently, deep reinforcement learning (DRL) has achieved promising results in solving online 3D Bin Packing Problems (3D-BPP). However, these DRL-based policies may perform poorly on new instances due to distribution shift. Besides generalization, we also consider adaptation, completely overlooked by previous work, which aims at rapidly finetuning these policies to a new test distribution. To tackle both generalization and adaptation issues, we propose Adaptive Selection After Pruning (ASAP), which decomposes a solver's decision-making into two policies, one for pruning and one for selection. The role of the pruning policy is to remove inherently bad actions, which allows the selection policy to choose among the remaining most valuable actions. To learn these policies, we propose a training scheme based on a meta-learning phase of both policies followed by a finetuning phase of the sole selection policy to rapidly adapt it to a test distribution. Our experiments demonstrate that ASAP exhibits excellent generalization and adaptation capabilities on in-distribution and out-of-distribution instances under both discrete and continuous setup.
Is Segment Anything Model 2 All You Need for Surgery Video Segmentation? A Systematic Evaluation
Dec 31, 2024



Surgery video segmentation is an important topic in the surgical AI field. It allows the AI model to understand the spatial information of a surgical scene. Meanwhile, due to the lack of annotated surgical data, surgery segmentation models suffer from limited performance. With the emergence of SAM2 model, a large foundation model for video segmentation trained on natural videos, zero-shot surgical video segmentation became more realistic but meanwhile remains to be explored. In this paper, we systematically evaluate the performance of SAM2 model in zero-shot surgery video segmentation task. We conducted experiments under different configurations, including different prompting strategies, robustness, etc. Moreover, we conducted an empirical evaluation over the performance, including 9 datasets with 17 different types of surgeries.
Surgical Scene Segmentation by Transformer With Asymmetric Feature Enhancement
Oct 23, 2024



Surgical scene segmentation is a fundamental task for robotic-assisted laparoscopic surgery understanding. It often contains various anatomical structures and surgical instruments, where similar local textures and fine-grained structures make the segmentation a difficult task. Vision-specific transformer method is a promising way for surgical scene understanding. However, there are still two main challenges. Firstly, the absence of inner-patch information fusion leads to poor segmentation performance. Secondly, the specific characteristics of anatomy and instruments are not specifically modeled. To tackle the above challenges, we propose a novel Transformer-based framework with an Asymmetric Feature Enhancement module (TAFE), which enhances local information and then actively fuses the improved feature pyramid into the embeddings from transformer encoders by a multi-scale interaction attention strategy. The proposed method outperforms the SOTA methods in several different surgical segmentation tasks and additionally proves its ability of fine-grained structure recognition. Code is available at https://github.com/cyuan-sjtu/ViT-asym.