 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelegation and Verification Under AI
Mar 03, 2026As AI systems enter institutional workflows, workers must decide whether to delegate task execution to AI and how much effort to invest in verifying AI outputs, while institutions evaluate workers using outcome-based standards that may misalign with workers' private costs. We model delegation and verification as the solution to a rational worker's optimization problem, and define worker quality by evaluating an institution-centered utility (distinct from the worker's objective) at the resulting optimal action. We formally characterize optimal worker workflows and show that AI induces *phase transitions*, where arbitrarily small differences in verification ability lead to sharply different behaviors. As a result, AI can amplify workers with strong verification reliability while degrading institutional worker quality for others who rationally over-delegate and reduce oversight, even when baseline task success improves and no behavioral biases are present. These results identify a structural mechanism by which AI reshapes institutional worker quality and amplifies quality disparities between workers with different verification reliability.
The Geometry of Learning Under AI Delegation
Mar 03, 2026As AI systems shift from tools to collaborators, a central question is how the skills of humans relying on them change over time. We study this question mathematically by modeling the joint evolution of human skill and AI delegation as a coupled dynamical system. In our model, delegation adapts to relative performance, while skill improves through use and decays under non-use; crucially, both updates arise from optimizing a single performance metric measuring expected task error. Despite this local alignment, adaptive AI use fundamentally alters the global stability structure of human skill acquisition. Beyond the high-skill equilibrium of human-only learning, the system admits a *stable* low-skill equilibrium corresponding to persistent reliance, separated by a sharp basin boundary that makes early decisions effectively irreversible under the induced dynamics. We further show that AI assistance can strictly improve short-run performance while inducing persistent long-run performance loss relative to the no-AI baseline, driven by a negative feedback between delegation and practice. We characterize how AI quality deforms the basin boundary and show that these effects are robust to noise and asymmetric trust updates. Our results identify stability, not incentives or misalignment, as the central mechanism by which AI assistance can undermine long-run human performance and skill.
Strategic Costs of Perceived Bias in Fair Selection
Oct 23, 2025Meritocratic systems, from admissions to hiring, aim to impartially reward skill and effort. Yet persistent disparities across race, gender, and class challenge this ideal. Some attribute these gaps to structural inequality; others to individual choice. We develop a game-theoretic model in which candidates from different socioeconomic groups differ in their perceived post-selection value--shaped by social context and, increasingly, by AI-powered tools offering personalized career or salary guidance. Each candidate strategically chooses effort, balancing its cost against expected reward; effort translates into observable merit, and selection is based solely on merit. We characterize the unique Nash equilibrium in the large-agent limit and derive explicit formulas showing how valuation disparities and institutional selectivity jointly determine effort, representation, social welfare, and utility. We further propose a cost-sensitive optimization framework that quantifies how modifying selectivity or perceived value can reduce disparities without compromising institutional goals. Our analysis reveals a perception-driven bias: when perceptions of post-selection value differ across groups, these differences translate into rational differences in effort, propagating disparities backward through otherwise "fair" selection processes. While the model is static, it captures one stage of a broader feedback cycle linking perceptions, incentives, and outcome--bridging rational-choice and structural explanations of inequality by showing how techno-social environments shape individual incentives in meritocratic systems.
A Mathematical Framework for AI-Human Integration in Work
May 29, 2025



The rapid rise of Generative AI (GenAI) tools has sparked debate over their role in complementing or replacing human workers across job contexts. We present a mathematical framework that models jobs, workers, and worker-job fit, introducing a novel decomposition of skills into decision-level and action-level subskills to reflect the complementary strengths of humans and GenAI. We analyze how changes in subskill abilities affect job success, identifying conditions for sharp transitions in success probability. We also establish sufficient conditions under which combining workers with complementary subskills significantly outperforms relying on a single worker. This explains phenomena such as productivity compression, where GenAI assistance yields larger gains for lower-skilled workers. We demonstrate the framework' s practicality using data from O*NET and Big-Bench Lite, aligning real-world data with our model via subskill-division methods. Our results highlight when and how GenAI complements human skills, rather than replacing them.
Efficient Diffusion Models for Symmetric Manifolds
May 27, 2025We introduce a framework for designing efficient diffusion models for $d$-dimensional symmetric-space Riemannian manifolds, including the torus, sphere, special orthogonal group and unitary group. Existing manifold diffusion models often depend on heat kernels, which lack closed-form expressions and require either $d$ gradient evaluations or exponential-in-$d$ arithmetic operations per training step. We introduce a new diffusion model for symmetric manifolds with a spatially-varying covariance, allowing us to leverage a projection of Euclidean Brownian motion to bypass heat kernel computations. Our training algorithm minimizes a novel efficient objective derived via Ito's Lemma, allowing each step to run in $O(1)$ gradient evaluations and nearly-linear-in-$d$ ($O(d^{1.19})$) arithmetic operations, reducing the gap between diffusions on symmetric manifolds and Euclidean space. Manifold symmetries ensure the diffusion satisfies an "average-case" Lipschitz condition, enabling accurate and efficient sample generation. Empirically, our model outperforms prior methods in training speed and improves sample quality on synthetic datasets on the torus, special orthogonal group, and unitary group.
Private Low-Rank Approximation for Covariance Matrices, Dyson Brownian Motion, and Eigenvalue-Gap Bounds for Gaussian Perturbations
Feb 11, 2025


We consider the problem of approximating a $d \times d$ covariance matrix $M$ with a rank-$k$ matrix under $(\varepsilon,\delta)$-differential privacy. We present and analyze a complex variant of the Gaussian mechanism and obtain upper bounds on the Frobenius norm of the difference between the matrix output by this mechanism and the best rank-$k$ approximation to $M$. Our analysis provides improvements over previous bounds, particularly when the spectrum of $M$ satisfies natural structural assumptions. The novel insight is to view the addition of Gaussian noise to a matrix as a continuous-time matrix Brownian motion. This viewpoint allows us to track the evolution of eigenvalues and eigenvectors of the matrix, which are governed by stochastic differential equations discovered by Dyson. These equations enable us to upper bound the Frobenius distance between the best rank-$k$ approximation of $M$ and that of a Gaussian perturbation of $M$ as an integral that involves inverse eigenvalue gaps of the stochastically evolving matrix, as opposed to a sum of perturbation bounds obtained via Davis-Kahan-type theorems. Subsequently, again using the Dyson Brownian motion viewpoint, we show that the eigenvalues of the matrix $M$ perturbed by Gaussian noise have large gaps with high probability. These results also contribute to the analysis of low-rank approximations under average-case perturbations, and to an understanding of eigenvalue gaps for random matrices, both of which may be of independent interest.
Centralized Selection with Preferences in the Presence of Biases
Sep 07, 2024
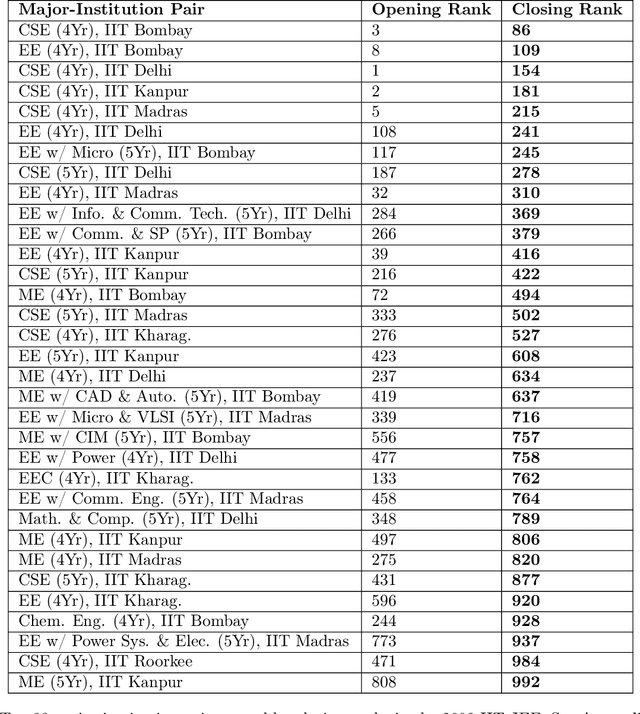
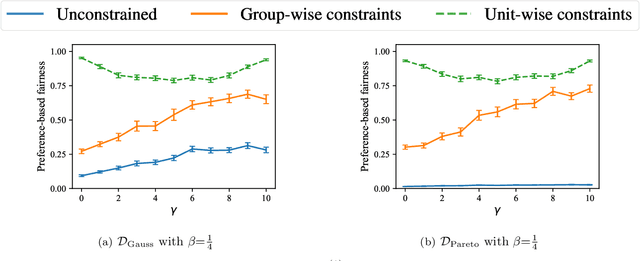

This paper considers the scenario in which there are multiple institutions, each with a limited capacity for candidates, and candidates, each with preferences over the institutions. A central entity evaluates the utility of each candidate to the institutions, and the goal is to select candidates for each institution in a way that maximizes utility while also considering the candidates' preferences. The paper focuses on the setting in which candidates are divided into multiple groups and the observed utilities of candidates in some groups are biased--systematically lower than their true utilities. The first result is that, in these biased settings, prior algorithms can lead to selections with sub-optimal true utility and significant discrepancies in the fraction of candidates from each group that get their preferred choices. Subsequently, an algorithm is presented along with proof that it produces selections that achieve near-optimal group fairness with respect to preferences while also nearly maximizing the true utility under distributional assumptions. Further, extensive empirical validation of these results in real-world and synthetic settings, in which the distributional assumptions may not hold, are presented.
Faster Sampling from Log-Concave Densities over Polytopes via Efficient Linear Solvers
Sep 06, 2024
We consider the problem of sampling from a log-concave distribution $\pi(\theta) \propto e^{-f(\theta)}$ constrained to a polytope $K:=\{\theta \in \mathbb{R}^d: A\theta \leq b\}$, where $A\in \mathbb{R}^{m\times d}$ and $b \in \mathbb{R}^m$.The fastest-known algorithm \cite{mangoubi2022faster} for the setting when $f$ is $O(1)$-Lipschitz or $O(1)$-smooth runs in roughly $O(md \times md^{\omega -1})$ arithmetic operations, where the $md^{\omega -1}$ term arises because each Markov chain step requires computing a matrix inversion and determinant (here $\omega \approx 2.37$ is the matrix multiplication constant). We present a nearly-optimal implementation of this Markov chain with per-step complexity which is roughly the number of non-zero entries of $A$ while the number of Markov chain steps remains the same. The key technical ingredients are 1) to show that the matrices that arise in this Dikin walk change slowly, 2) to deploy efficient linear solvers that can leverage this slow change to speed up matrix inversion by using information computed in previous steps, and 3) to speed up the computation of the determinantal term in the Metropolis filter step via a randomized Taylor series-based estimator.
Bias in Evaluation Processes: An Optimization-Based Model
Oct 26, 2023

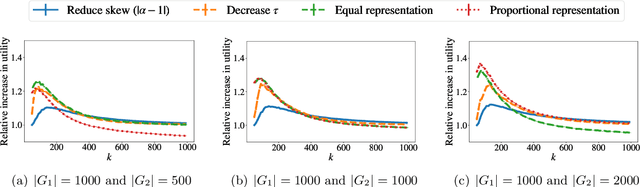

Biases with respect to socially-salient attributes of individuals have been well documented in evaluation processes used in settings such as admissions and hiring. We view such an evaluation process as a transformation of a distribution of the true utility of an individual for a task to an observed distribution and model it as a solution to a loss minimization problem subject to an information constraint. Our model has two parameters that have been identified as factors leading to biases: the resource-information trade-off parameter in the information constraint and the risk-averseness parameter in the loss function. We characterize the distributions that arise from our model and study the effect of the parameters on the observed distribution. The outputs of our model enrich the class of distributions that can be used to capture variation across groups in the observed evaluations. We empirically validate our model by fitting real-world datasets and use it to study the effect of interventions in a downstream selection task. These results contribute to an understanding of the emergence of bias in evaluation processes and provide tools to guide the deployment of interventions to mitigate biases.
Private Covariance Approximation and Eigenvalue-Gap Bounds for Complex Gaussian Perturbations
Jun 29, 2023
We consider the problem of approximating a $d \times d$ covariance matrix $M$ with a rank-$k$ matrix under $(\varepsilon,\delta)$-differential privacy. We present and analyze a complex variant of the Gaussian mechanism and show that the Frobenius norm of the difference between the matrix output by this mechanism and the best rank-$k$ approximation to $M$ is bounded by roughly $\tilde{O}(\sqrt{kd})$, whenever there is an appropriately large gap between the $k$'th and the $k+1$'th eigenvalues of $M$. This improves on previous work that requires that the gap between every pair of top-$k$ eigenvalues of $M$ is at least $\sqrt{d}$ for a similar bound. Our analysis leverages the fact that the eigenvalues of complex matrix Brownian motion repel more than in the real case, and uses Dyson's stochastic differential equations governing the evolution of its eigenvalues to show that the eigenvalues of the matrix $M$ perturbed by complex Gaussian noise have large gaps with high probability. Our results contribute to the analysis of low-rank approximations under average-case perturbations and to an understanding of eigenvalue gaps for random matrices, which may be of independent interest.