 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Non-Parametric Subspace Analysis Approach with Application to Anomaly Detection Ensembles
Paper and Code
Jan 13, 2021
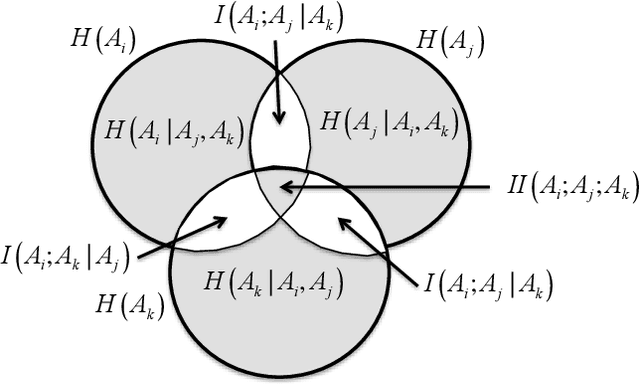

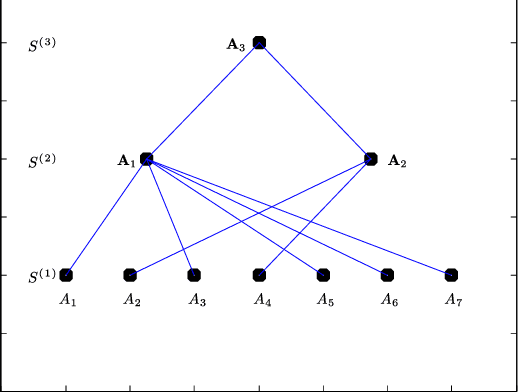
Identifying anomalies in multi-dimensional datasets is an important task in many real-world applications. A special case arises when anomalies are occluded in a small set of attributes, typically referred to as a subspace, and not necessarily over the entire data space. In this paper, we propose a new subspace analysis approach named Agglomerative Attribute Grouping (AAG) that aims to address this challenge by searching for subspaces that are comprised of highly correlative attributes. Such correlations among attributes represent a systematic interaction among the attributes that can better reflect the behavior of normal observations and hence can be used to improve the identification of two particularly interesting types of abnormal data samples: anomalies that are occluded in relatively small subsets of the attributes and anomalies that represent a new data class. AAG relies on a novel multi-attribute measure, which is derived from information theory measures of partitions, for evaluating the "information distance" between groups of data attributes. To determine the set of subspaces to use, AAG applies a variation of the well-known agglomerative clustering algorithm with the proposed multi-attribute measure as the underlying distance function. Finally, the set of subspaces is used in an ensemble for anomaly detection. Extensive evaluation demonstrates that, in the vast majority of cases, the proposed AAG method (i) outperforms classical and state-of-the-art subspace analysis methods when used in anomaly detection ensembles, and (ii) generates fewer subspaces with a fewer number of attributes each (on average), thus resulting in a faster training time for the anomaly detection ensemble. Furthermore, in contrast to existing methods, the proposed AAG method does not require any tuning of parameters.