 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Neural Networks Defenses and Attacks using NDCG and Reciprocal Rank Metrics
Jan 10, 2022
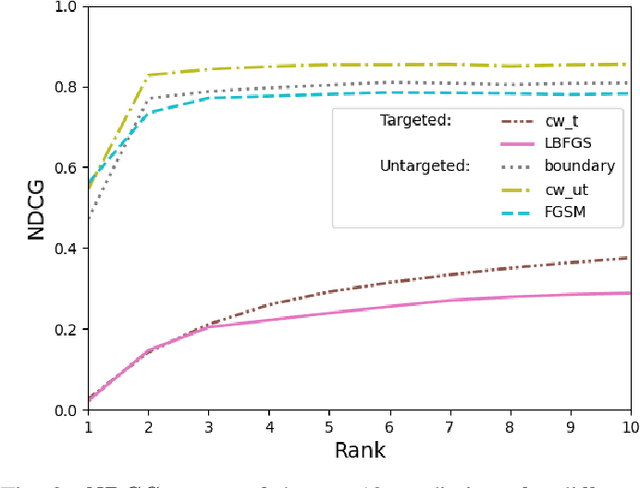
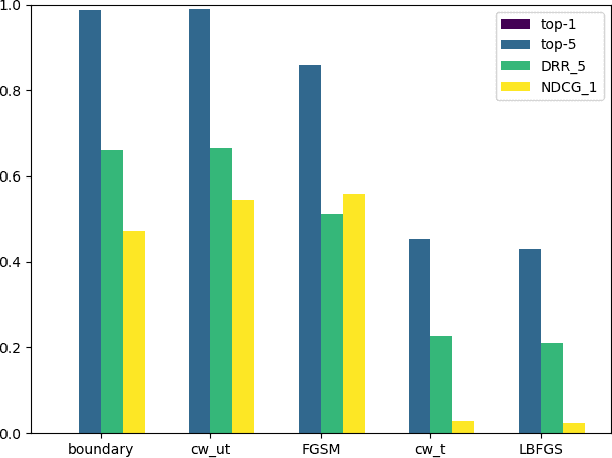
The problem of attacks on neural networks through input modification (i.e., adversarial examples) has attracted much attention recently. Being relatively easy to generate and hard to detect, these attacks pose a security breach that many suggested defenses try to mitigate. However, the evaluation of the effect of attacks and defenses commonly relies on traditional classification metrics, without adequate adaptation to adversarial scenarios. Most of these metrics are accuracy-based, and therefore may have a limited scope and low distinctive power. Other metrics do not consider the unique characteristics of neural networks functionality, or measure the effect of the attacks indirectly (e.g., through the complexity of their generation). In this paper, we present two metrics which are specifically designed to measure the effect of attacks, or the recovery effect of defenses, on the output of neural networks in multiclass classification tasks. Inspired by the normalized discounted cumulative gain and the reciprocal rank metrics used in information retrieval literature, we treat the neural network predictions as ranked lists of results. Using additional information about the probability of the rank enabled us to define novel metrics that are suited to the task at hand. We evaluate our metrics using various attacks and defenses on a pretrained VGG19 model and the ImageNet dataset. Compared to the common classification metrics, our proposed metrics demonstrate superior informativeness and distinctiveness.
Heat and Blur: An Effective and Fast Defense Against Adversarial Examples
Mar 17, 2020
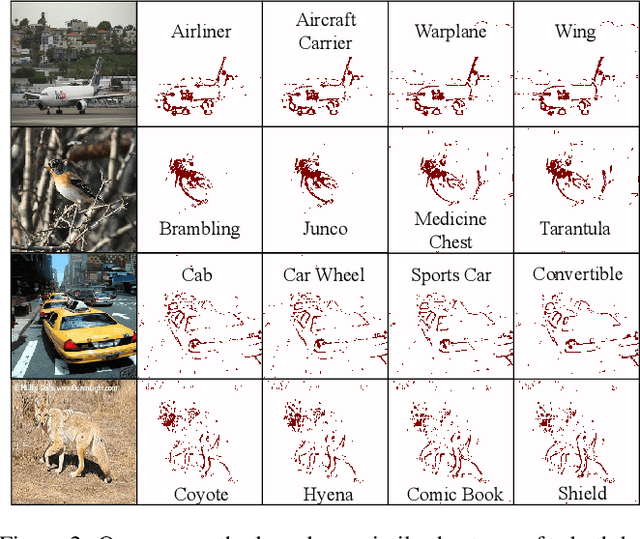

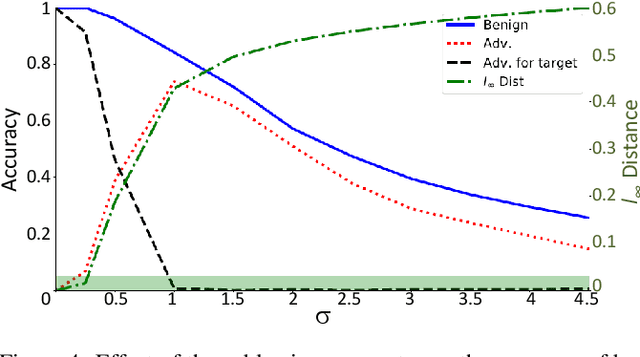
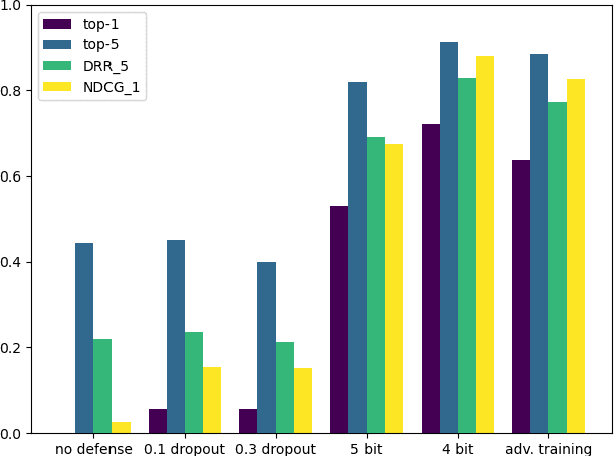
The growing incorporation of artificial neural networks (NNs) into many fields, and especially into life-critical systems, is restrained by their vulnerability to adversarial examples (AEs). Some existing defense methods can increase NNs' robustness, but they often require special architecture or training procedures and are irrelevant to already trained models. In this paper, we propose a simple defense that combines feature visualization with input modification, and can, therefore, be applicable to various pre-trained networks. By reviewing several interpretability methods, we gain new insights regarding the influence of AEs on NNs' computation. Based on that, we hypothesize that information about the "true" object is preserved within the NN's activity, even when the input is adversarial, and present a feature visualization version that can extract that information in the form of relevance heatmaps. We then use these heatmaps as a basis for our defense, in which the adversarial effects are corrupted by massive blurring. We also provide a new evaluation metric that can capture the effects of both attacks and defenses more thoroughly and descriptively, and demonstrate the effectiveness of the defense and the utility of the suggested evaluation measurement with VGG19 results on the ImageNet dataset.