 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning While Staying Curious: Entropy-Preserving Supervised Fine-Tuning via Adaptive Self-Distillation for Large Reasoning Models
Feb 02, 2026The standard post-training recipe for large reasoning models, supervised fine-tuning followed by reinforcement learning (SFT-then-RL), may limit the benefits of the RL stage: while SFT imitates expert demonstrations, it often causes overconfidence and reduces generation diversity, leaving RL with a narrowed solution space to explore. Adding entropy regularization during SFT is not a cure-all; it tends to flatten token distributions toward uniformity, increasing entropy without improving meaningful exploration capability. In this paper, we propose CurioSFT, an entropy-preserving SFT method designed to enhance exploration capabilities through intrinsic curiosity. It consists of (a) Self-Exploratory Distillation, which distills the model toward a self-generated, temperature-scaled teacher to encourage exploration within its capability; and (b) Entropy-Guided Temperature Selection, which adaptively adjusts distillation strength to mitigate knowledge forgetting by amplifying exploration at reasoning tokens while stabilizing factual tokens. Extensive experiments on mathematical reasoning tasks demonstrate that, in SFT stage, CurioSFT outperforms the vanilla SFT by 2.5 points on in-distribution tasks and 2.9 points on out-of-distribution tasks. We also verify that exploration capabilities preserved during SFT successfully translate into concrete gains in RL stage, yielding an average improvement of 5.0 points.
LinguaGame: A Linguistically Grounded Game-Theoretic Paradigm for Multi-Agent Dialogue Generation
Jan 08, 2026Large Language Models (LLMs) have enabled Multi-Agent Systems (MASs) where agents interact through natural language to solve complex tasks or simulate multi-party dialogues. Recent work on LLM-based MASs has mainly focused on architecture design, such as role assignment and workflow orchestration. In contrast, this paper targets the interaction process itself, aiming to improve agents' communication efficiency by helping them convey their intended meaning more effectively through language. To this end, we propose LinguaGame, a linguistically-grounded game-theoretic paradigm for multi-agent dialogue generation. Our approach models dialogue as a signalling game over communicative intents and strategies, solved with a training-free equilibrium approximation algorithm for inference-time decision adjustment. Unlike prior game-theoretic MASs, whose game designs are often tightly coupled with task-specific objectives, our framework relies on linguistically informed reasoning with minimal task-specific coupling. Specifically, it treats dialogue as intentional and strategic communication, requiring agents to infer what others aim to achieve (intents) and how they pursue those goals (strategies). We evaluate our framework in simulated courtroom proceedings and debates, with human expert assessments showing significant gains in communication efficiency.
GARDO: Reinforcing Diffusion Models without Reward Hacking
Dec 30, 2025Fine-tuning diffusion models via online reinforcement learning (RL) has shown great potential for enhancing text-to-image alignment. However, since precisely specifying a ground-truth objective for visual tasks remains challenging, the models are often optimized using a proxy reward that only partially captures the true goal. This mismatch often leads to reward hacking, where proxy scores increase while real image quality deteriorates and generation diversity collapses. While common solutions add regularization against the reference policy to prevent reward hacking, they compromise sample efficiency and impede the exploration of novel, high-reward regions, as the reference policy is usually sub-optimal. To address the competing demands of sample efficiency, effective exploration, and mitigation of reward hacking, we propose Gated and Adaptive Regularization with Diversity-aware Optimization (GARDO), a versatile framework compatible with various RL algorithms. Our key insight is that regularization need not be applied universally; instead, it is highly effective to selectively penalize a subset of samples that exhibit high uncertainty. To address the exploration challenge, GARDO introduces an adaptive regularization mechanism wherein the reference model is periodically updated to match the capabilities of the online policy, ensuring a relevant regularization target. To address the mode collapse issue in RL, GARDO amplifies the rewards for high-quality samples that also exhibit high diversity, encouraging mode coverage without destabilizing the optimization process. Extensive experiments across diverse proxy rewards and hold-out unseen metrics consistently show that GARDO mitigates reward hacking and enhances generation diversity without sacrificing sample efficiency or exploration, highlighting its effectiveness and robustness.
LexRel: Benchmarking Legal Relation Extraction for Chinese Civil Cases
Dec 14, 2025Legal relations form a highly consequential analytical framework of civil law system, serving as a crucial foundation for resolving disputes and realizing values of the rule of law in judicial practice. However, legal relations in Chinese civil cases remain underexplored in the field of legal artificial intelligence (legal AI), largely due to the absence of comprehensive schemas. In this work, we firstly introduce a comprehensive schema, which contains a hierarchical taxonomy and definitions of arguments, for AI systems to capture legal relations in Chinese civil cases. Based on this schema, we then formulate legal relation extraction task and present LexRel, an expert-annotated benchmark for legal relation extraction in Chinese civil law. We use LexRel to evaluate state-of-the-art large language models (LLMs) on legal relation extractions, showing that current LLMs exhibit significant limitations in accurately identifying civil legal relations. Furthermore, we demonstrate that incorporating legal relations information leads to consistent performance gains on other downstream legal AI tasks.
OpenCUA: Open Foundations for Computer-Use Agents
Aug 12, 2025Vision-language models have demonstrated impressive capabilities as computer-use agents (CUAs) capable of automating diverse computer tasks. As their commercial potential grows, critical details of the most capable CUA systems remain closed. As these agents will increasingly mediate digital interactions and execute consequential decisions on our behalf, the research community needs access to open CUA frameworks to study their capabilities, limitations, and risks. To bridge this gap, we propose OpenCUA, a comprehensive open-source framework for scaling CUA data and foundation models. Our framework consists of: (1) an annotation infrastructure that seamlessly captures human computer-use demonstrations; (2) AgentNet, the first large-scale computer-use task dataset spanning 3 operating systems and 200+ applications and websites; (3) a scalable pipeline that transforms demonstrations into state-action pairs with reflective long Chain-of-Thought reasoning that sustain robust performance gains as data scales. Our end-to-end agent models demonstrate strong performance across CUA benchmarks. In particular, OpenCUA-32B achieves an average success rate of 34.8% on OSWorld-Verified, establishing a new state-of-the-art (SOTA) among open-source models and surpassing OpenAI CUA (GPT-4o). Further analysis confirms that our approach generalizes well across domains and benefits significantly from increased test-time computation. We release our annotation tool, datasets, code, and models to build open foundations for further CUA research.
Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows
Nov 12, 2024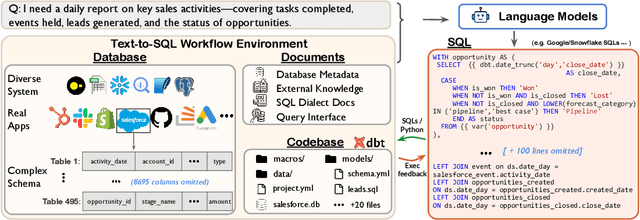


Real-world enterprise text-to-SQL workflows often involve complex cloud or local data across various database systems, multiple SQL queries in various dialects, and diverse operations from data transformation to analytics. We introduce Spider 2.0, an evaluation framework comprising 632 real-world text-to-SQL workflow problems derived from enterprise-level database use cases. The databases in Spider 2.0 are sourced from real data applications, often containing over 1,000 columns and stored in local or cloud database systems such as BigQuery and Snowflake. We show that solving problems in Spider 2.0 frequently requires understanding and searching through database metadata, dialect documentation, and even project-level codebases. This challenge calls for models to interact with complex SQL workflow environments, process extremely long contexts, perform intricate reasoning, and generate multiple SQL queries with diverse operations, often exceeding 100 lines, which goes far beyond traditional text-to-SQL challenges. Our evaluations indicate that based on o1-preview, our code agent framework successfully solves only 17.0% of the tasks, compared with 91.2% on Spider 1.0 and 73.0% on BIRD. Our results on Spider 2.0 show that while language models have demonstrated remarkable performance in code generation -- especially in prior text-to-SQL benchmarks -- they require significant improvement in order to achieve adequate performance for real-world enterprise usage. Progress on Spider 2.0 represents crucial steps towards developing intelligent, autonomous, code agents for real-world enterprise settings. Our code, baseline models, and data are available at https://spider2-sql.github.io.
PET-SQL: A Prompt-enhanced Two-stage Text-to-SQL Framework with Cross-consistency
Mar 18, 2024



Recent advancements in Text-to-SQL (Text2SQL) emphasize stimulating the large language models (LLM) on in-context learning, achieving significant results. Nevertheless, they face challenges when dealing with verbose database information and complex user intentions. This paper presents a two-stage framework to enhance the performance of current LLM-based natural language to SQL systems. We first introduce a novel prompt representation, called reference-enhanced representation, which includes schema information and randomly sampled cell values from tables to instruct LLMs in generating SQL queries. Then, in the first stage, question-SQL pairs are retrieved as few-shot demonstrations, prompting the LLM to generate a preliminary SQL (PreSQL). After that, the mentioned entities in PreSQL are parsed to conduct schema linking, which can significantly compact the useful information. In the second stage, with the linked schema, we simplify the prompt's schema information and instruct the LLM to produce the final SQL. Finally, as the post-refinement module, we propose using cross-consistency across different LLMs rather than self-consistency within a particular LLM. Our methods achieve new SOTA results on the Spider benchmark, with an execution accuracy of 87.6%.
Benchmarking the Text-to-SQL Capability of Large Language Models: A Comprehensive Evaluation
Mar 06, 2024



Large Language Models (LLMs) have emerged as a powerful tool in advancing the Text-to-SQL task, significantly outperforming traditional methods. Nevertheless, as a nascent research field, there is still no consensus on the optimal prompt templates and design frameworks. Additionally, existing benchmarks inadequately explore the performance of LLMs across the various sub-tasks of the Text-to-SQL process, which hinders the assessment of LLMs' cognitive capabilities and the optimization of LLM-based solutions. To address the aforementioned issues, we firstly construct a new dataset designed to mitigate the risk of overfitting in LLMs. Then we formulate five evaluation tasks to comprehensively assess the performance of diverse methods across various LLMs throughout the Text-to-SQL process.Our study highlights the performance disparities among LLMs and proposes optimal in-context learning solutions tailored to each task. These findings offer valuable insights for enhancing the development of LLM-based Text-to-SQL systems.
Improving Cross-Domain Chinese Word Segmentation with Word Embeddings
Mar 29, 2019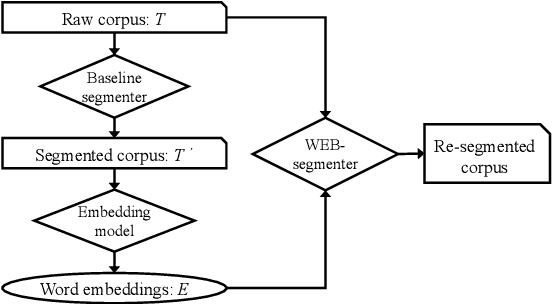
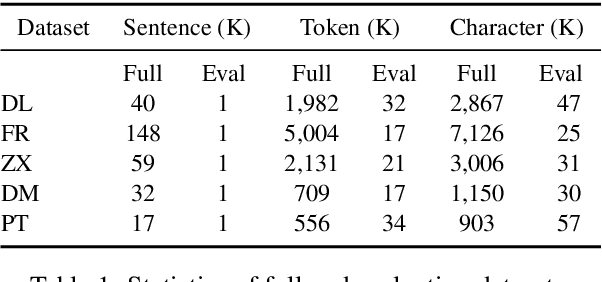


Cross-domain Chinese Word Segmentation (CWS) remains a challenge despite recent progress in neural-based CWS. The limited amount of annotated data in the target domain has been the key obstacle to a satisfactory performance. In this paper, we propose a semi-supervised word-based approach to improving cross-domain CWS given a baseline segmenter. Particularly, our model only deploys word embeddings trained on raw text in the target domain, discarding complex hand-crafted features and domain-specific dictionaries. Innovative subsampling and negative sampling methods are proposed to derive word embeddings optimized for CWS. We conduct experiments on five datasets in special domains, covering domains in novels, medicine, and patent. Results show that our model can obviously improve cross-domain CWS, especially in the segmentation of domain-specific noun entities. The word F-measure increases by over 3.0% on four datasets, outperforming state-of-the-art semi-supervised and unsupervised cross-domain CWS approaches with a large margin. We make our code and data available on Github.
Few-Shot Text Classification with Induction Network
Feb 27, 2019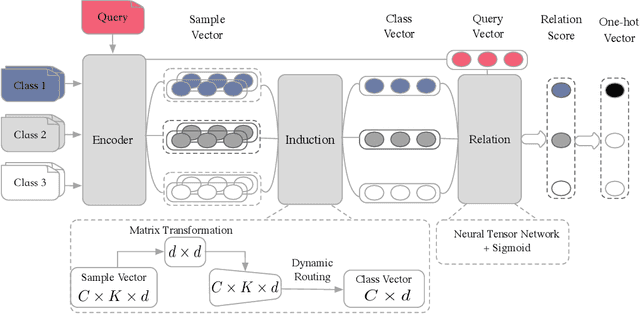


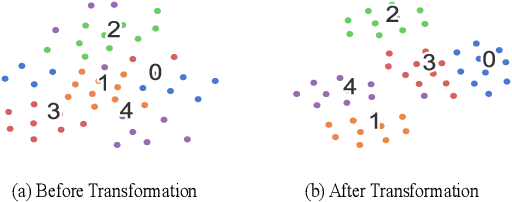
Text classification tends to struggle when data is deficient or when it needs to adapt to unseen classes. In such challenging scenarios, recent studies often use meta learning to simulate the few-shot task, in which new queries are compared to a small support set on a sample-wise level. However, this sample-wise comparison may be severely disturbed by the various expressions in the same class. Therefore, we should be able to learn a general representation of each class in the support set and then compare it to new queries. In this paper, we propose a novel Induction Network to learn such generalized class-wise representations, innovatively combining the dynamic routing algorithm with the typical meta learning framework. In this way, our model is able to induce from particularity to university, which is a more human-like learning approach. We evaluate our model on a well-studied sentiment classification dataset (English) and a real-world dialogue intent classification dataset (Chinese). Experiment results show that, on both datasets, our model significantly outperforms existing state-of-the-art models and improves the average accuracy by more than 3%, which proves the effectiveness of class-wise generalization in few-shot text classification.