 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do LLMs and VLMs Understand Viewpoint Rotation Without Vision? An Interpretability Study
Apr 16, 2026Over the past year, spatial intelligence has drawn increasing attention. Many prior works study it from the perspective of visual-spatial intelligence, where models have access to visuospatial information from visual inputs. However, in the absence of visual information, whether linguistic intelligence alone is sufficient to endow models with spatial intelligence, and how models perform relevant tasks with text-only inputs still remain unexplored. Therefore, in this paper, we focus on a fundamental and critical capability in spatial intelligence from a linguistic perspective: viewpoint rotation understanding (VRU). Specifically, LLMs and VLMs are asked to infer their final viewpoint and predict the corresponding observation in an environment given textual description of viewpoint rotation and observation over multiple steps. We find that both LLMs and VLMs perform poorly on our proposed dataset while human can easily achieve 100% accuracy, indicating a substantial gap between current model capabilities and the requirements of spatial intelligence. To uncover the underlying mechanisms, we conduct a layer-wise probing analysis and head-wise causal intervention. Our findings reveal that although models encode viewpoint information in the hidden states, they appear to struggle to bind the viewpoint position with corresponding observation, resulting in a hallucination in final layers. Finally, we selectively fine-tune the key attention heads identified by causal intervention to improve VRU performance. Experimental results demonstrate that such selective fine-tuning achieves improved VRU performance while avoiding catastrophic forgetting of generic abilities. Our dataset and code will be released at https://github.com/Young-Zhen/VRU_Interpret .
HINTBench: Horizon-agent Intrinsic Non-attack Trajectory Benchmark
Apr 15, 2026Existing agent-safety evaluation has focused mainly on externally induced risks. Yet agents may still enter unsafe trajectories under benign conditions. We study this complementary but underexplored setting through the lens of \emph{intrinsic} risk, where intrinsic failures remain latent, propagate across long-horizon execution, and eventually lead to high-consequence outcomes. To evaluate this setting, we introduce \emph{non-attack intrinsic risk auditing} and present \textbf{HINTBench}, a benchmark of 629 agent trajectories (523 risky, 106 safe; 33 steps on average) supporting three tasks: risk detection, risk-step localization, and intrinsic failure-type identification. Its annotations are organized under a unified five-constraint taxonomy. Experiments reveal a substantial capability gap: strong LLMs perform well on trajectory-level risk detection, but their performance drops to below 35 Strict-F1 on risk-step localization, while fine-grained failure diagnosis proves even harder. Existing guard models transfer poorly to this setting. These findings establish intrinsic risk auditing as an open challenge for agent safety.
The Struggle Between Continuation and Refusal: A Mechanistic Analysis of the Continuation-Triggered Jailbreak in LLMs
Mar 09, 2026With the rapid advancement of large language models (LLMs), the safety of LLMs has become a critical concern. Despite significant efforts in safety alignment, current LLMs remain vulnerable to jailbreaking attacks. However, the root causes of such vulnerabilities are still poorly understood, necessitating a rigorous investigation into jailbreak mechanisms across both academic and industrial communities. In this work, we focus on a continuation-triggered jailbreak phenomenon, whereby simply relocating a continuation-triggered instruction suffix can substantially increase jailbreak success rates. To uncover the intrinsic mechanisms of this phenomenon, we conduct a comprehensive mechanistic interpretability analysis at the level of attention heads. Through causal interventions and activation scaling, we show that this jailbreak behavior primarily arises from an inherent competition between the model's intrinsic continuation drive and the safety defenses acquired through alignment training. Furthermore, we perform a detailed behavioral analysis of the identified safety-critical attention heads, revealing notable differences in the functions and behaviors of safety heads across different model architectures. These findings provide a novel mechanistic perspective for understanding and interpreting jailbreak behaviors in LLMs, offering both theoretical insights and practical implications for improving model safety.
Patch the Distribution Mismatch: RL Rewriting Agent for Stable Off-Policy SFT
Feb 11, 2026Large language models (LLMs) have made rapid progress, yet adapting them to downstream scenarios still commonly relies on supervised fine-tuning (SFT). When downstream data exhibit a substantial distribution shift from the model's prior training distribution, SFT can induce catastrophic forgetting. To narrow this gap, data rewriting has been proposed as a data-centric approach that rewrites downstream training data prior to SFT. However, existing methods typically sample rewrites from a prompt-induced conditional distribution, so the resulting targets are not necessarily aligned with the model's natural QA-style generation distribution. Moreover, reliance on fixed templates can lead to diversity collapse. To address these issues, we cast data rewriting as a policy learning problem and learn a rewriting policy that better matches the backbone's QA-style generation distribution while preserving diversity. Since distributional alignment, diversity and task consistency are automatically evaluable but difficult to optimize end-to-end with differentiable objectives, we leverage reinforcement learning to optimize the rewrite distribution under reward feedback and propose an RL-based data-rewriting agent. The agent jointly optimizes QA-style distributional alignment and diversity under a hard task-consistency gate, thereby constructing a higher-quality rewritten dataset for downstream SFT. Extensive experiments show that our method achieves downstream gains comparable to standard SFT while reducing forgetting on non-downstream benchmarks by 12.34% on average. Our code is available at https://anonymous.4open.science/r/Patch-the-Prompt-Gap-4112 .
Can LLMs See Without Pixels? Benchmarking Spatial Intelligence from Textual Descriptions
Jan 07, 2026Recent advancements in Spatial Intelligence (SI) have predominantly relied on Vision-Language Models (VLMs), yet a critical question remains: does spatial understanding originate from visual encoders or the fundamental reasoning backbone? Inspired by this question, we introduce SiT-Bench, a novel benchmark designed to evaluate the SI performance of Large Language Models (LLMs) without pixel-level input, comprises over 3,800 expert-annotated items across five primary categories and 17 subtasks, ranging from egocentric navigation and perspective transformation to fine-grained robotic manipulation. By converting single/multi-view scenes into high-fidelity, coordinate-aware textual descriptions, we challenge LLMs to perform symbolic textual reasoning rather than visual pattern matching. Evaluation results of state-of-the-art (SOTA) LLMs reveals that while models achieve proficiency in localized semantic tasks, a significant "spatial gap" remains in global consistency. Notably, we find that explicit spatial reasoning significantly boosts performance, suggesting that LLMs possess latent world-modeling potential. Our proposed dataset SiT-Bench serves as a foundational resource to foster the development of spatially-grounded LLM backbones for future VLMs and embodied agents. Our code and benchmark will be released at https://github.com/binisalegend/SiT-Bench .
Beyond Flatlands: Unlocking Spatial Intelligence by Decoupling 3D Reasoning from Numerical Regression
Nov 18, 2025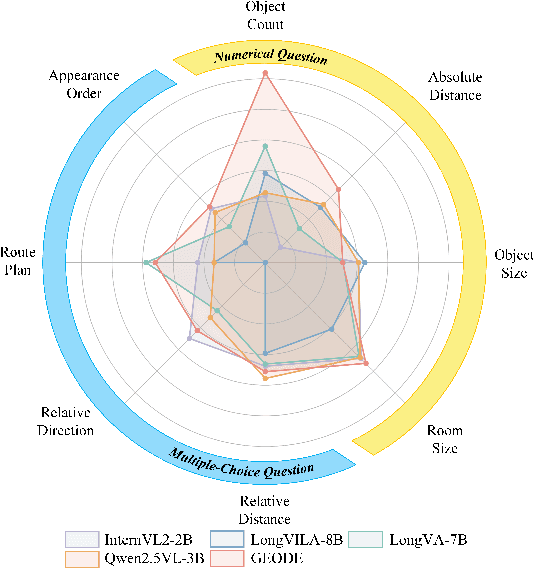
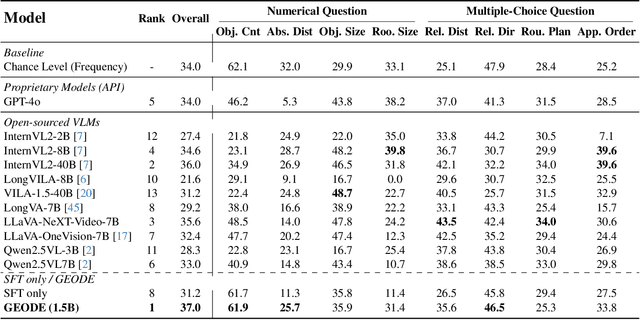
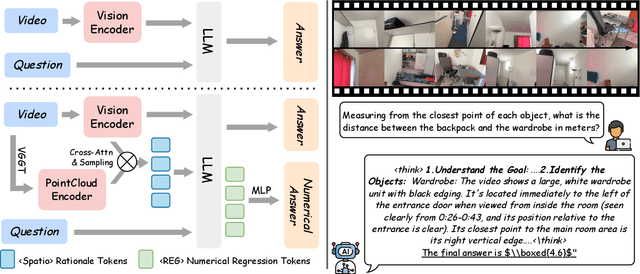
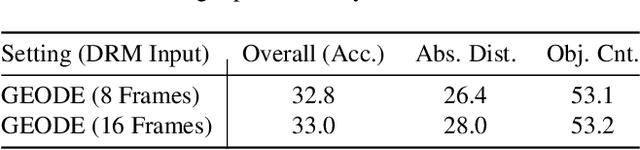
Existing Vision Language Models (VLMs) architecturally rooted in "flatland" perception, fundamentally struggle to comprehend real-world 3D spatial intelligence. This failure stems from a dual-bottleneck: input-stage conflict between computationally exorbitant geometric-aware encoders and superficial 2D-only features, and output-stage misalignment where discrete tokenizers are structurally incapable of producing precise, continuous numerical values. To break this impasse, we introduce GEODE (Geometric-Output and Decoupled-Input Engine), a novel architecture that resolves this dual-bottleneck by decoupling 3D reasoning from numerical generation. GEODE augments main VLM with two specialized, plug-and-play modules: Decoupled Rationale Module (DRM) that acts as spatial co-processor, aligning explicit 3D data with 2D visual features via cross-attention and distilling spatial Chain-of-Thought (CoT) logic into injectable Rationale Tokens; and Direct Regression Head (DRH), an "Embedding-as-Value" paradigm which routes specialized control tokens to a lightweight MLP for precise, continuous regression of scalars and 3D bounding boxes. The synergy of these modules allows our 1.5B parameter model to function as a high-level semantic dispatcher, achieving state-of-the-art spatial reasoning performance that rivals 7B+ models.
TAMMs: Temporal-Aware Multimodal Model for Satellite Image Change Understanding and Forecasting
Jun 23, 2025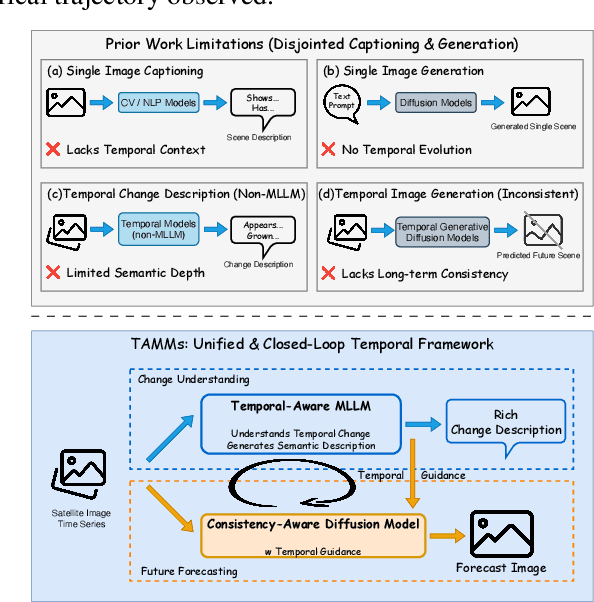
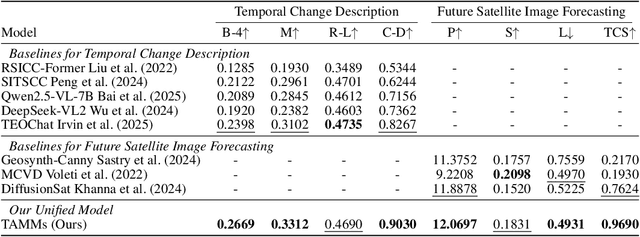
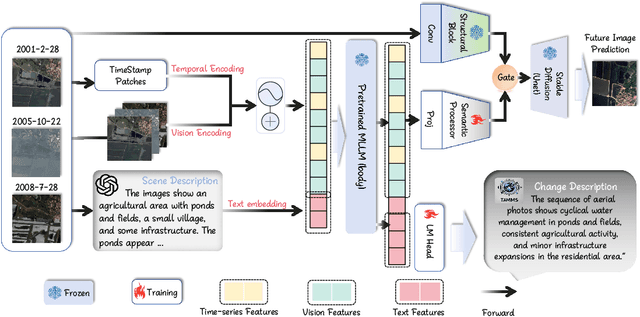
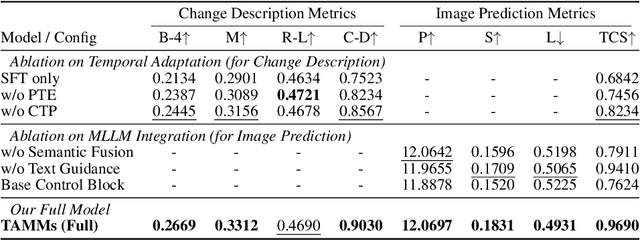
Satellite image time-series analysis demands fine-grained spatial-temporal reasoning, which remains a challenge for existing multimodal large language models (MLLMs). In this work, we study the capabilities of MLLMs on a novel task that jointly targets temporal change understanding and future scene generation, aiming to assess their potential for modeling complex multimodal dynamics over time. We propose TAMMs, a Temporal-Aware Multimodal Model for satellite image change understanding and forecasting, which enhances frozen MLLMs with lightweight temporal modules for structured sequence encoding and contextual prompting. To guide future image generation, TAMMs introduces a Semantic-Fused Control Injection (SFCI) mechanism that adaptively combines high-level semantic reasoning and structural priors within an enhanced ControlNet. This dual-path conditioning enables temporally consistent and semantically grounded image synthesis. Experiments demonstrate that TAMMs outperforms strong MLLM baselines in both temporal change understanding and future image forecasting tasks, highlighting how carefully designed temporal reasoning and semantic fusion can unlock the full potential of MLLMs for spatio-temporal understanding.
Thought-Path Contrastive Learning via Premise-Oriented Data Augmentation for Logical Reading Comprehension
Sep 24, 2024



Logical reading comprehension is a challenging task that entails grasping the underlying semantics of text and applying reasoning to deduce the correct answer. Prior researches have primarily focused on enhancing logical reasoning capabilities through Chain-of-Thought (CoT) or data augmentation. However, previous work constructing chain-of-thought rationales concentrates solely on analyzing correct options, neglecting the incorrect alternatives. Addtionally, earlier efforts on data augmentation by altering contexts rely on rule-based methods, which result in generated contexts that lack diversity and coherence. To address these issues, we propose a Premise-Oriented Data Augmentation (PODA) framework. This framework can generate CoT rationales including analyses for both correct and incorrect options, while constructing diverse and high-quality counterfactual contexts from incorrect candidate options. We integrate summarizing premises and identifying premises for each option into rationales. Subsequently, we employ multi-step prompts with identified premises to construct counterfactual context. To facilitate the model's capabilities to better differentiate the reasoning process associated with each option, we introduce a novel thought-path contrastive learning method that compares reasoning paths between the original and counterfactual samples. Experimental results on three representative LLMs demonstrate that our method can improve the baselines substantially across two challenging logical reasoning benchmarks (ReClor and LogiQA 2.0). The data and code are released at https://github.com/lalalamdbf/TPReasoner.
Prompt-based Logical Semantics Enhancement for Implicit Discourse Relation Recognition
Nov 01, 2023
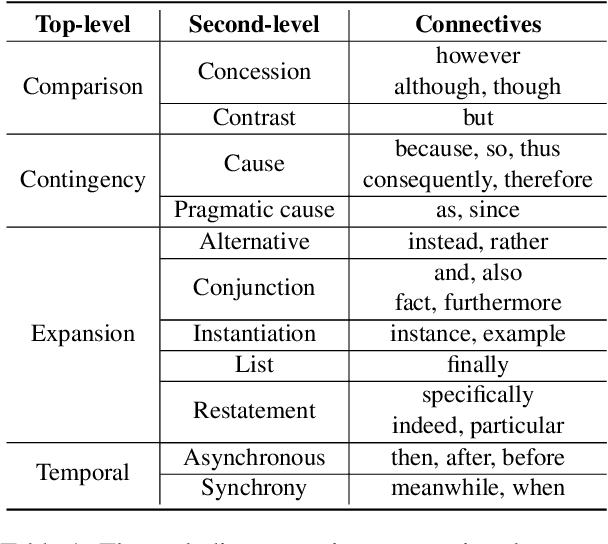
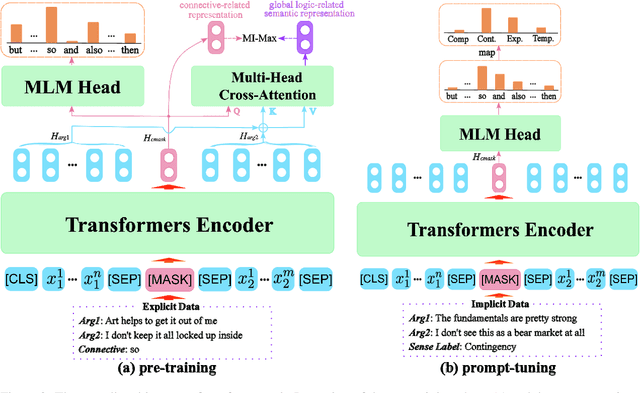
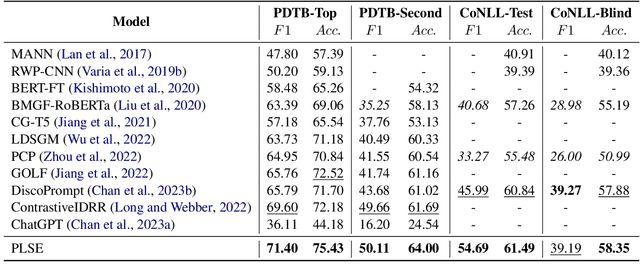
Implicit Discourse Relation Recognition (IDRR), which infers discourse relations without the help of explicit connectives, is still a crucial and challenging task for discourse parsing. Recent works tend to exploit the hierarchical structure information from the annotated senses, which demonstrate enhanced discourse relation representations can be obtained by integrating sense hierarchy. Nevertheless, the performance and robustness for IDRR are significantly constrained by the availability of annotated data. Fortunately, there is a wealth of unannotated utterances with explicit connectives, that can be utilized to acquire enriched discourse relation features. In light of such motivation, we propose a Prompt-based Logical Semantics Enhancement (PLSE) method for IDRR. Essentially, our method seamlessly injects knowledge relevant to discourse relation into pre-trained language models through prompt-based connective prediction. Furthermore, considering the prompt-based connective prediction exhibits local dependencies due to the deficiency of masked language model (MLM) in capturing global semantics, we design a novel self-supervised learning objective based on mutual information maximization to derive enhanced representations of logical semantics for IDRR. Experimental results on PDTB 2.0 and CoNLL16 datasets demonstrate that our method achieves outstanding and consistent performance against the current state-of-the-art models.
Teach model to answer questions after comprehending the document
Jul 18, 2023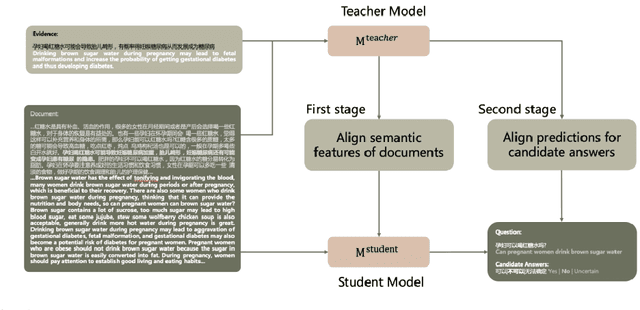
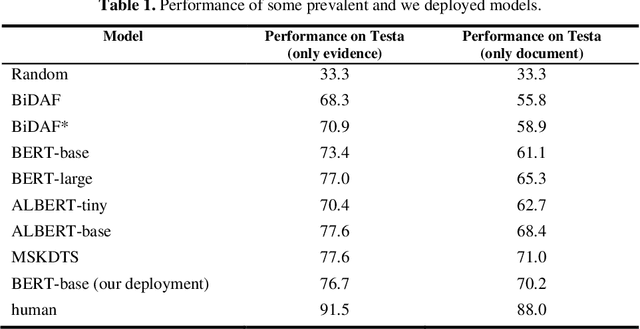
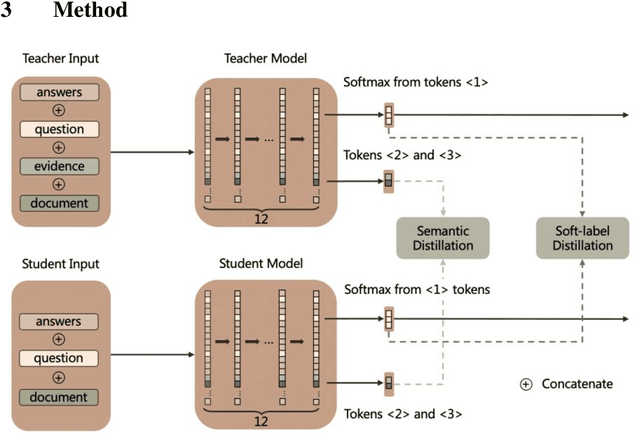

Multi-choice Machine Reading Comprehension (MRC) is a challenging extension of Natural Language Processing (NLP) that requires the ability to comprehend the semantics and logical relationships between entities in a given text. The MRC task has traditionally been viewed as a process of answering questions based on the given text. This single-stage approach has often led the network to concentrate on generating the correct answer, potentially neglecting the comprehension of the text itself. As a result, many prevalent models have faced challenges in performing well on this task when dealing with longer texts. In this paper, we propose a two-stage knowledge distillation method that teaches the model to better comprehend the document by dividing the MRC task into two separate stages. Our experimental results show that the student model, when equipped with our method, achieves significant improvements, demonstrating the effectiveness of our method.