 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Benchmarks of IUGC: Rethinking Requirements of Deep Learning Methods for Intrapartum Ultrasound Biometry from Fetal Ultrasound Videos
Feb 13, 2026A substantial proportion (45\%) of maternal deaths, neonatal deaths, and stillbirths occur during the intrapartum phase, with a particularly high burden in low- and middle-income countries. Intrapartum biometry plays a critical role in monitoring labor progression; however, the routine use of ultrasound in resource-limited settings is hindered by a shortage of trained sonographers. To address this challenge, the Intrapartum Ultrasound Grand Challenge (IUGC), co-hosted with MICCAI 2024, was launched. The IUGC introduces a clinically oriented multi-task automatic measurement framework that integrates standard plane classification, fetal head-pubic symphysis segmentation, and biometry, enabling algorithms to exploit complementary task information for more accurate estimation. Furthermore, the challenge releases the largest multi-center intrapartum ultrasound video dataset to date, comprising 774 videos (68,106 frames) collected from three hospitals, providing a robust foundation for model training and evaluation. In this study, we present a comprehensive overview of the challenge design, review the submissions from eight participating teams, and analyze their methods from five perspectives: preprocessing, data augmentation, learning strategy, model architecture, and post-processing. In addition, we perform a systematic analysis of the benchmark results to identify key bottlenecks, explore potential solutions, and highlight open challenges for future research. Although encouraging performance has been achieved, our findings indicate that the field remains at an early stage, and further in-depth investigation is required before large-scale clinical deployment. All benchmark solutions and the complete dataset have been publicly released to facilitate reproducible research and promote continued advances in automatic intrapartum ultrasound biometry.
APTOS-2024 challenge report: Generation of synthetic 3D OCT images from fundus photographs
Jun 09, 2025Optical Coherence Tomography (OCT) provides high-resolution, 3D, and non-invasive visualization of retinal layers in vivo, serving as a critical tool for lesion localization and disease diagnosis. However, its widespread adoption is limited by equipment costs and the need for specialized operators. In comparison, 2D color fundus photography offers faster acquisition and greater accessibility with less dependence on expensive devices. Although generative artificial intelligence has demonstrated promising results in medical image synthesis, translating 2D fundus images into 3D OCT images presents unique challenges due to inherent differences in data dimensionality and biological information between modalities. To advance generative models in the fundus-to-3D-OCT setting, the Asia Pacific Tele-Ophthalmology Society (APTOS-2024) organized a challenge titled Artificial Intelligence-based OCT Generation from Fundus Images. This paper details the challenge framework (referred to as APTOS-2024 Challenge), including: the benchmark dataset, evaluation methodology featuring two fidelity metrics-image-based distance (pixel-level OCT B-scan similarity) and video-based distance (semantic-level volumetric consistency), and analysis of top-performing solutions. The challenge attracted 342 participating teams, with 42 preliminary submissions and 9 finalists. Leading methodologies incorporated innovations in hybrid data preprocessing or augmentation (cross-modality collaborative paradigms), pre-training on external ophthalmic imaging datasets, integration of vision foundation models, and model architecture improvement. The APTOS-2024 Challenge is the first benchmark demonstrating the feasibility of fundus-to-3D-OCT synthesis as a potential solution for improving ophthalmic care accessibility in under-resourced healthcare settings, while helping to expedite medical research and clinical applications.
Learning to Generate Parameters of ConvNets for Unseen Image Data
Oct 24, 2023



Typical Convolutional Neural Networks (ConvNets) depend heavily on large amounts of image data and resort to an iterative optimization algorithm (e.g., SGD or Adam) to learn network parameters, which makes training very time- and resource-intensive. In this paper, we propose a new training paradigm and formulate the parameter learning of ConvNets into a prediction task: given a ConvNet architecture, we observe there exists correlations between image datasets and their corresponding optimal network parameters, and explore if we can learn a hyper-mapping between them to capture the relations, such that we can directly predict the parameters of the network for an image dataset never seen during the training phase. To do this, we put forward a new hypernetwork based model, called PudNet, which intends to learn a mapping between datasets and their corresponding network parameters, and then predicts parameters for unseen data with only a single forward propagation. Moreover, our model benefits from a series of adaptive hyper recurrent units sharing weights to capture the dependencies of parameters among different network layers. Extensive experiments demonstrate that our proposed method achieves good efficacy for unseen image datasets on two kinds of settings: Intra-dataset prediction and Inter-dataset prediction. Our PudNet can also well scale up to large-scale datasets, e.g., ImageNet-1K. It takes 8967 GPU seconds to train ResNet-18 on the ImageNet-1K using GC from scratch and obtain a top-5 accuracy of 44.65 %. However, our PudNet costs only 3.89 GPU seconds to predict the network parameters of ResNet-18 achieving comparable performance (44.92 %), more than 2,300 times faster than the traditional training paradigm.
Self-Supervised Information Bottleneck for Deep Multi-View Subspace Clustering
Apr 29, 2022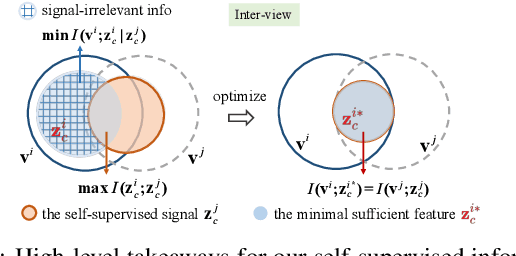
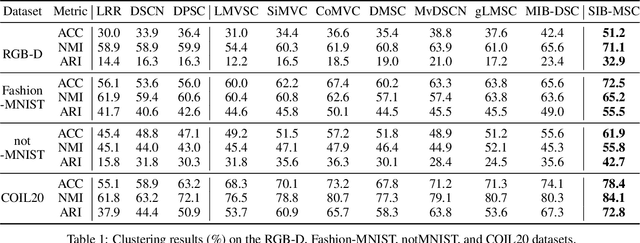
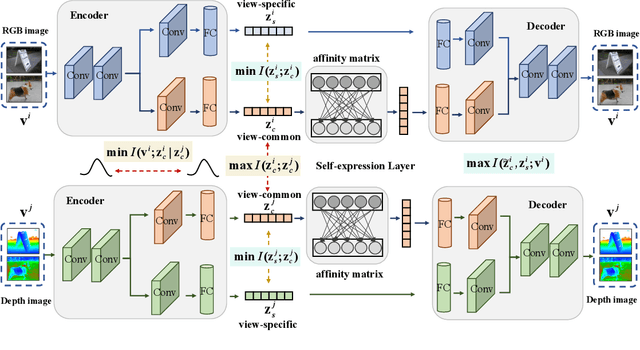
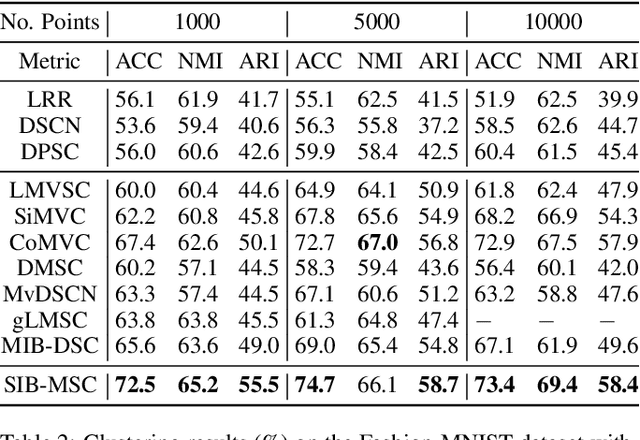
In this paper, we explore the problem of deep multi-view subspace clustering framework from an information-theoretic point of view. We extend the traditional information bottleneck principle to learn common information among different views in a self-supervised manner, and accordingly establish a new framework called Self-supervised Information Bottleneck based Multi-view Subspace Clustering (SIB-MSC). Inheriting the advantages from information bottleneck, SIB-MSC can learn a latent space for each view to capture common information among the latent representations of different views by removing superfluous information from the view itself while retaining sufficient information for the latent representations of other views. Actually, the latent representation of each view provides a kind of self-supervised signal for training the latent representations of other views. Moreover, SIB-MSC attempts to learn the other latent space for each view to capture the view-specific information by introducing mutual information based regularization terms, so as to further improve the performance of multi-view subspace clustering. To the best of our knowledge, this is the first work to explore information bottleneck for multi-view subspace clustering. Extensive experiments on real-world multi-view data demonstrate that our method achieves superior performance over the related state-of-the-art methods.
Learning Deep Representation with Energy-Based Self-Expressiveness for Subspace Clustering
Oct 28, 2021
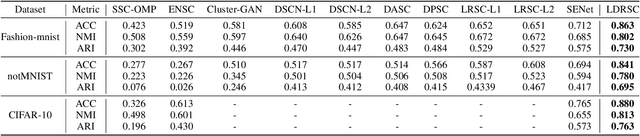
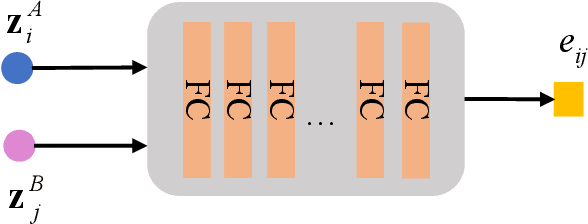
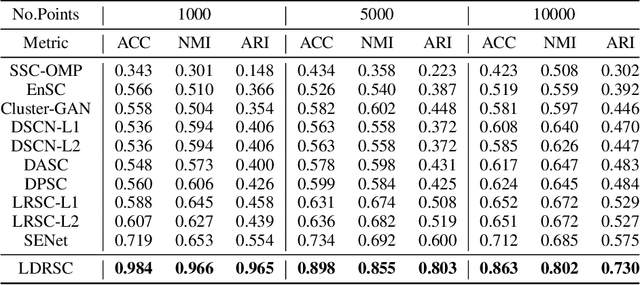
Deep subspace clustering has attracted increasing attention in recent years. Almost all the existing works are required to load the whole training data into one batch for learning the self-expressive coefficients in the framework of deep learning. Although these methods achieve promising results, such a learning fashion severely prevents from the usage of deeper neural network architectures (e.g., ResNet), leading to the limited representation abilities of the models. In this paper, we propose a new deep subspace clustering framework, motivated by the energy-based models. In contrast to previous approaches taking the weights of a fully connected layer as the self-expressive coefficients, we propose to learn an energy-based network to obtain the self-expressive coefficients by mini-batch training. By this means, it is no longer necessary to load all data into one batch for learning, and it thus becomes a reality that we can utilize deeper neural network models for subspace clustering. Considering the powerful representation ability of the recently popular self-supervised learning, we attempt to leverage self-supervised representation learning to learn the dictionary. Finally, we propose a joint framework to learn both the self-expressive coefficients and dictionary simultaneously, and train the model in an end-to-end manner. The experiments are performed on three publicly available datasets, and extensive experimental results demonstrate our method can significantly outperform the other related approaches. For instance, on the three datasets, our method can averagely achieve $13.8\%$, $15.4\%$, $20.8\%$ improvements in terms of Accuracy, NMI, and ARI over SENet which is proposed very recently and obtains the second best results in the experiments.