 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuSEAgent: A Multimodal Reasoning Agent with Stateful Experiences
Mar 29, 2026Research agents have recently achieved significant progress in information seeking and synthesis across heterogeneous textual and visual sources. In this paper, we introduce MuSEAgent, a multimodal reasoning agent that enhances decision-making by extending the capabilities of research agents to discover and leverage stateful experiences. Rather than relying on trajectory-level retrieval, we propose a stateful experience learning paradigm that abstracts interaction data into atomic decision experiences through hindsight reasoning. These experiences are organized into a quality-filtered experience bank that supports policy-driven experience retrieval at inference time. Specifically, MuSEAgent enables adaptive experience exploitation through complementary wide- and deep-search strategies, allowing the agent to dynamically retrieve multimodal guidance across diverse compositional semantic viewpoints. Extensive experiments demonstrate that MuSEAgent consistently outperforms strong trajectory-level experience retrieval baselines on both fine-grained visual perception and complex multimodal reasoning tasks. These results validate the effectiveness of stateful experience modeling in improving multimodal agent reasoning.
RationalVLA: A Rational Vision-Language-Action Model with Dual System
Jun 12, 2025A fundamental requirement for real-world robotic deployment is the ability to understand and respond to natural language instructions. Existing language-conditioned manipulation tasks typically assume that instructions are perfectly aligned with the environment. This assumption limits robustness and generalization in realistic scenarios where instructions may be ambiguous, irrelevant, or infeasible. To address this problem, we introduce RAtional MAnipulation (RAMA), a new benchmark that challenges models with both unseen executable instructions and defective ones that should be rejected. In RAMA, we construct a dataset with over 14,000 samples, including diverse defective instructions spanning six dimensions: visual, physical, semantic, motion, safety, and out-of-context. We further propose the Rational Vision-Language-Action model (RationalVLA). It is a dual system for robotic arms that integrates the high-level vision-language model with the low-level manipulation policy by introducing learnable latent space embeddings. This design enables RationalVLA to reason over instructions, reject infeasible commands, and execute manipulation effectively. Experiments demonstrate that RationalVLA outperforms state-of-the-art baselines on RAMA by a 14.5% higher success rate and 0.94 average task length, while maintaining competitive performance on standard manipulation tasks. Real-world trials further validate its effectiveness and robustness in practical applications. Our project page is https://irpn-eai.github.io/rationalvla.
APTOS-2024 challenge report: Generation of synthetic 3D OCT images from fundus photographs
Jun 09, 2025Optical Coherence Tomography (OCT) provides high-resolution, 3D, and non-invasive visualization of retinal layers in vivo, serving as a critical tool for lesion localization and disease diagnosis. However, its widespread adoption is limited by equipment costs and the need for specialized operators. In comparison, 2D color fundus photography offers faster acquisition and greater accessibility with less dependence on expensive devices. Although generative artificial intelligence has demonstrated promising results in medical image synthesis, translating 2D fundus images into 3D OCT images presents unique challenges due to inherent differences in data dimensionality and biological information between modalities. To advance generative models in the fundus-to-3D-OCT setting, the Asia Pacific Tele-Ophthalmology Society (APTOS-2024) organized a challenge titled Artificial Intelligence-based OCT Generation from Fundus Images. This paper details the challenge framework (referred to as APTOS-2024 Challenge), including: the benchmark dataset, evaluation methodology featuring two fidelity metrics-image-based distance (pixel-level OCT B-scan similarity) and video-based distance (semantic-level volumetric consistency), and analysis of top-performing solutions. The challenge attracted 342 participating teams, with 42 preliminary submissions and 9 finalists. Leading methodologies incorporated innovations in hybrid data preprocessing or augmentation (cross-modality collaborative paradigms), pre-training on external ophthalmic imaging datasets, integration of vision foundation models, and model architecture improvement. The APTOS-2024 Challenge is the first benchmark demonstrating the feasibility of fundus-to-3D-OCT synthesis as a potential solution for improving ophthalmic care accessibility in under-resourced healthcare settings, while helping to expedite medical research and clinical applications.
Seeing Far and Clearly: Mitigating Hallucinations in MLLMs with Attention Causal Decoding
May 22, 2025Recent advancements in multimodal large language models (MLLMs) have significantly improved performance in visual question answering. However, they often suffer from hallucinations. In this work, hallucinations are categorized into two main types: initial hallucinations and snowball hallucinations. We argue that adequate contextual information can be extracted directly from the token interaction process. Inspired by causal inference in the decoding strategy, we propose to leverage causal masks to establish information propagation between multimodal tokens. The hypothesis is that insufficient interaction between those tokens may lead the model to rely on outlier tokens, overlooking dense and rich contextual cues. Therefore, we propose to intervene in the propagation process by tackling outlier tokens to enhance in-context inference. With this goal, we present FarSight, a versatile plug-and-play decoding strategy to reduce attention interference from outlier tokens merely by optimizing the causal mask. The heart of our method is effective token propagation. We design an attention register structure within the upper triangular matrix of the causal mask, dynamically allocating attention to capture attention diverted to outlier tokens. Moreover, a positional awareness encoding method with a diminishing masking rate is proposed, allowing the model to attend to further preceding tokens, especially for video sequence tasks. With extensive experiments, FarSight demonstrates significant hallucination-mitigating performance across different MLLMs on both image and video benchmarks, proving its effectiveness.
MoRE: Unlocking Scalability in Reinforcement Learning for Quadruped Vision-Language-Action Models
Mar 11, 2025Developing versatile quadruped robots that can smoothly perform various actions and tasks in real-world environments remains a significant challenge. This paper introduces a novel vision-language-action (VLA) model, mixture of robotic experts (MoRE), for quadruped robots that aim to introduce reinforcement learning (RL) for fine-tuning large-scale VLA models with a large amount of mixed-quality data. MoRE integrates multiple low-rank adaptation modules as distinct experts within a dense multi-modal large language model (MLLM), forming a sparse-activated mixture-of-experts model. This design enables the model to effectively adapt to a wide array of downstream tasks. Moreover, we employ a reinforcement learning-based training objective to train our model as a Q-function after deeply exploring the structural properties of our tasks. Effective learning from automatically collected mixed-quality data enhances data efficiency and model performance. Extensive experiments demonstrate that MoRE outperforms all baselines across six different skills and exhibits superior generalization capabilities in out-of-distribution scenarios. We further validate our method in real-world scenarios, confirming the practicality of our approach and laying a solid foundation for future research on multi-task learning in quadruped robots.
OphNet: A Large-Scale Video Benchmark for Ophthalmic Surgical Workflow Understanding
Jun 12, 2024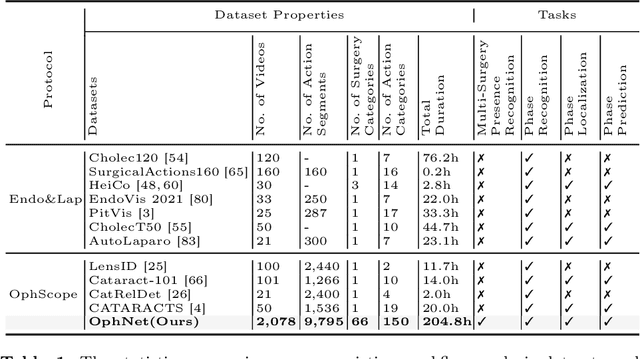
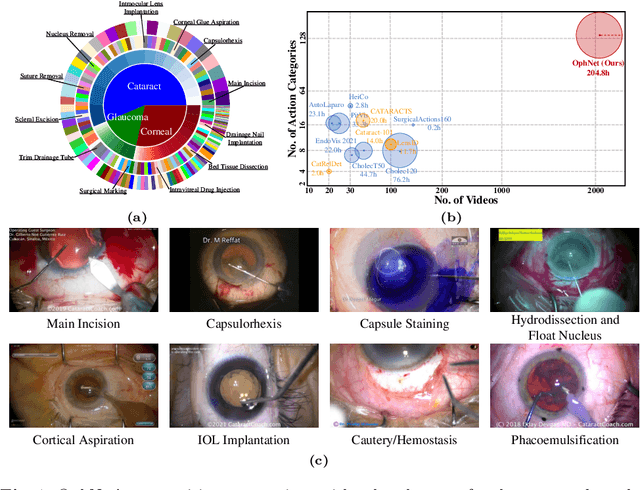

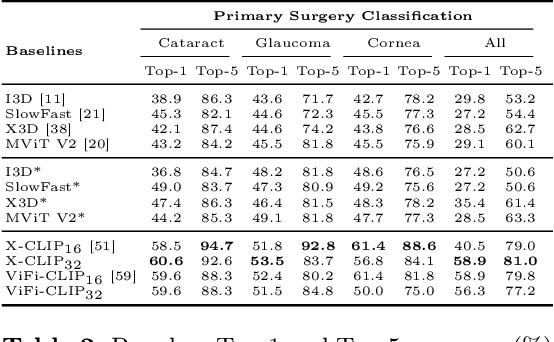
Surgical scene perception via videos are critical for advancing robotic surgery, telesurgery, and AI-assisted surgery, particularly in ophthalmology. However, the scarcity of diverse and richly annotated video datasets has hindered the development of intelligent systems for surgical workflow analysis. Existing datasets for surgical workflow analysis, which typically face challenges such as small scale, a lack of diversity in surgery and phase categories, and the absence of time-localized annotations, limit the requirements for action understanding and model generalization validation in complex and diverse real-world surgical scenarios. To address this gap, we introduce OphNet, a large-scale, expert-annotated video benchmark for ophthalmic surgical workflow understanding. OphNet features: 1) A diverse collection of 2,278 surgical videos spanning 66 types of cataract, glaucoma, and corneal surgeries, with detailed annotations for 102 unique surgical phases and 150 granular operations; 2) It offers sequential and hierarchical annotations for each surgery, phase, and operation, enabling comprehensive understanding and improved interpretability; 3) Moreover, OphNet provides time-localized annotations, facilitating temporal localization and prediction tasks within surgical workflows. With approximately 205 hours of surgical videos, OphNet is about 20 times larger than the largest existing surgical workflow analysis benchmark. Our dataset and code have been made available at: \url{https://github.com/minghu0830/OphNet-benchmark}.
EndoSurf: Neural Surface Reconstruction of Deformable Tissues with Stereo Endoscope Videos
Jul 21, 2023Reconstructing soft tissues from stereo endoscope videos is an essential prerequisite for many medical applications. Previous methods struggle to produce high-quality geometry and appearance due to their inadequate representations of 3D scenes. To address this issue, we propose a novel neural-field-based method, called EndoSurf, which effectively learns to represent a deforming surface from an RGBD sequence. In EndoSurf, we model surface dynamics, shape, and texture with three neural fields. First, 3D points are transformed from the observed space to the canonical space using the deformation field. The signed distance function (SDF) field and radiance field then predict their SDFs and colors, respectively, with which RGBD images can be synthesized via differentiable volume rendering. We constrain the learned shape by tailoring multiple regularization strategies and disentangling geometry and appearance. Experiments on public endoscope datasets demonstrate that EndoSurf significantly outperforms existing solutions, particularly in reconstructing high-fidelity shapes. Code is available at https://github.com/Ruyi-Zha/endosurf.git.
Deep Laparoscopic Stereo Matching with Transformers
Jul 25, 2022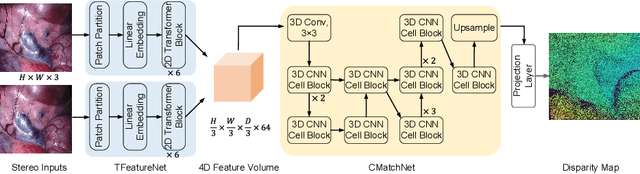

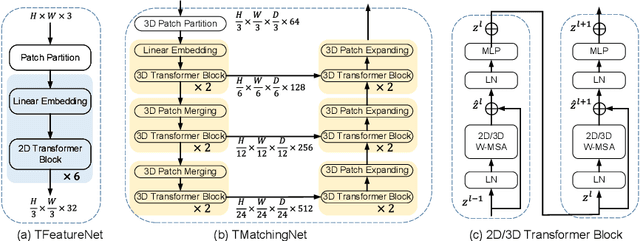
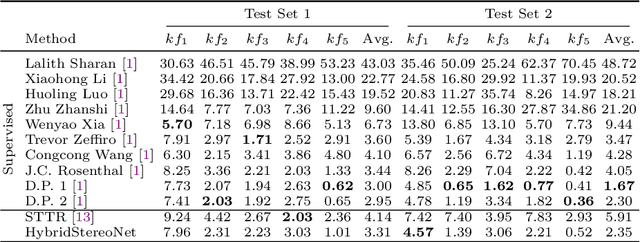
The self-attention mechanism, successfully employed with the transformer structure is shown promise in many computer vision tasks including image recognition, and object detection. Despite the surge, the use of the transformer for the problem of stereo matching remains relatively unexplored. In this paper, we comprehensively investigate the use of the transformer for the problem of stereo matching, especially for laparoscopic videos, and propose a new hybrid deep stereo matching framework (HybridStereoNet) that combines the best of the CNN and the transformer in a unified design. To be specific, we investigate several ways to introduce transformers to volumetric stereo matching pipelines by analyzing the loss landscape of the designs and in-domain/cross-domain accuracy. Our analysis suggests that employing transformers for feature representation learning, while using CNNs for cost aggregation will lead to faster convergence, higher accuracy and better generalization than other options. Our extensive experiments on Sceneflow, SCARED2019 and dVPN datasets demonstrate the superior performance of our HybridStereoNet.
Implicit Motion Handling for Video Camouflaged Object Detection
Mar 15, 2022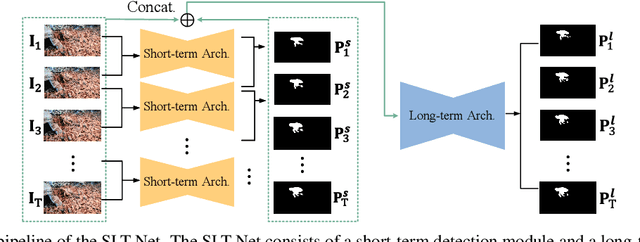
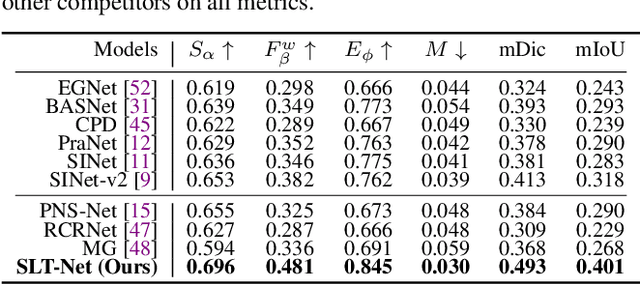
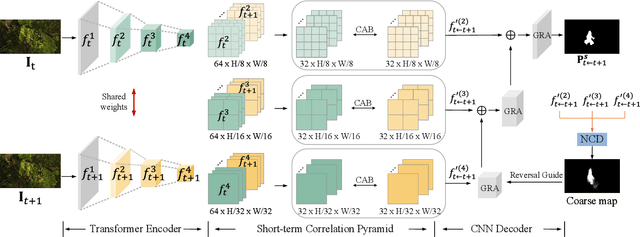

We propose a new video camouflaged object detection (VCOD) framework that can exploit both short-term dynamics and long-term temporal consistency to detect camouflaged objects from video frames. An essential property of camouflaged objects is that they usually exhibit patterns similar to the background and thus make them hard to identify from still images. Therefore, effectively handling temporal dynamics in videos becomes the key for the VCOD task as the camouflaged objects will be noticeable when they move. However, current VCOD methods often leverage homography or optical flows to represent motions, where the detection error may accumulate from both the motion estimation error and the segmentation error. On the other hand, our method unifies motion estimation and object segmentation within a single optimization framework. Specifically, we build a dense correlation volume to implicitly capture motions between neighbouring frames and utilize the final segmentation supervision to optimize the implicit motion estimation and segmentation jointly. Furthermore, to enforce temporal consistency within a video sequence, we jointly utilize a spatio-temporal transformer to refine the short-term predictions. Extensive experiments on VCOD benchmarks demonstrate the architectural effectiveness of our approach. We also provide a large-scale VCOD dataset named MoCA-Mask with pixel-level handcrafted ground-truth masks and construct a comprehensive VCOD benchmark with previous methods to facilitate research in this direction. Dataset Link: https://xueliancheng.github.io/SLT-Net-project.
Hierarchical Neural Architecture Search for Deep Stereo Matching
Oct 26, 2020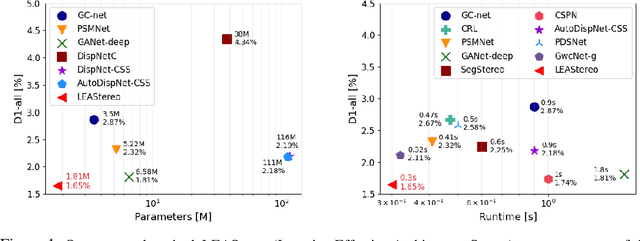
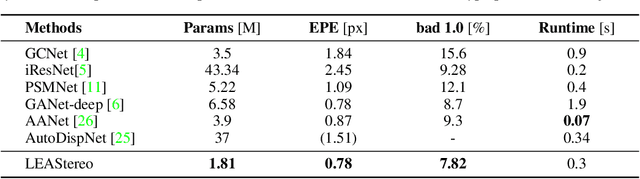
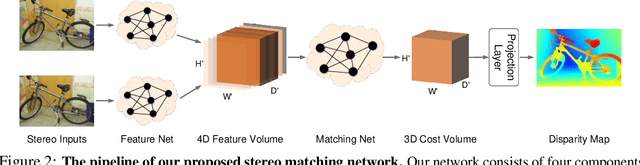
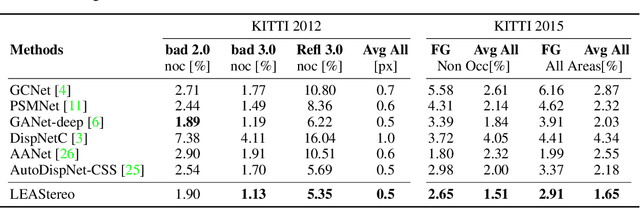
To reduce the human efforts in neural network design, Neural Architecture Search (NAS) has been applied with remarkable success to various high-level vision tasks such as classification and semantic segmentation. The underlying idea for the NAS algorithm is straightforward, namely, to enable the network the ability to choose among a set of operations (e.g., convolution with different filter sizes), one is able to find an optimal architecture that is better adapted to the problem at hand. However, so far the success of NAS has not been enjoyed by low-level geometric vision tasks such as stereo matching. This is partly due to the fact that state-of-the-art deep stereo matching networks, designed by humans, are already sheer in size. Directly applying the NAS to such massive structures is computationally prohibitive based on the currently available mainstream computing resources. In this paper, we propose the first end-to-end hierarchical NAS framework for deep stereo matching by incorporating task-specific human knowledge into the neural architecture search framework. Specifically, following the gold standard pipeline for deep stereo matching (i.e., feature extraction -- feature volume construction and dense matching), we optimize the architectures of the entire pipeline jointly. Extensive experiments show that our searched network outperforms all state-of-the-art deep stereo matching architectures and is ranked at the top 1 accuracy on KITTI stereo 2012, 2015 and Middlebury benchmarks, as well as the top 1 on SceneFlow dataset with a substantial improvement on the size of the network and the speed of inference. The code is available at https://github.com/XuelianCheng/LEAStereo.