 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomical Similarity as a New Metric to Evaluate Brain Generative Models
Apr 30, 2025Generative models enhance neuroimaging through data augmentation, quality improvement, and rare condition studies. Despite advances in realistic synthetic MRIs, evaluations focus on texture and perception, lacking sensitivity to crucial anatomical fidelity. This study proposes a new metric, called WASABI (Wasserstein-Based Anatomical Brain Index), to assess the anatomical realism of synthetic brain MRIs. WASABI leverages \textit{SynthSeg}, a deep learning-based brain parcellation tool, to derive volumetric measures of brain regions in each MRI and uses the multivariate Wasserstein distance to compare distributions between real and synthetic anatomies. Based on controlled experiments on two real datasets and synthetic MRIs from five generative models, WASABI demonstrates higher sensitivity in quantifying anatomical discrepancies compared to traditional image-level metrics, even when synthetic images achieve near-perfect visual quality. Our findings advocate for shifting the evaluation paradigm beyond visual inspection and conventional metrics, emphasizing anatomical fidelity as a crucial benchmark for clinically meaningful brain MRI synthesis. Our code is available at https://github.com/BahramJafrasteh/wasabi-mri.
OphNet: A Large-Scale Video Benchmark for Ophthalmic Surgical Workflow Understanding
Jun 12, 2024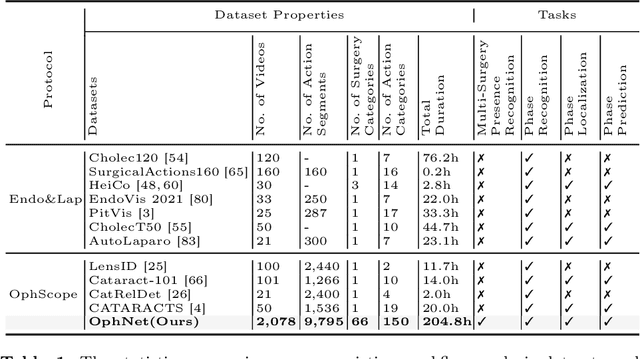
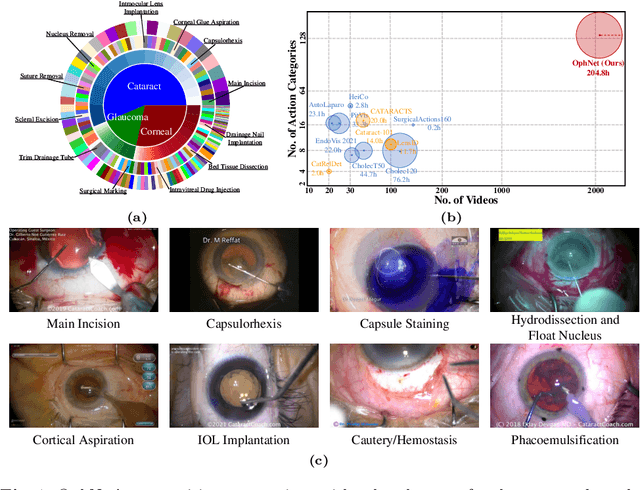

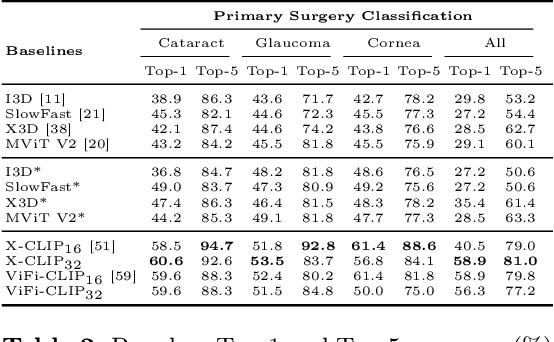
Surgical scene perception via videos are critical for advancing robotic surgery, telesurgery, and AI-assisted surgery, particularly in ophthalmology. However, the scarcity of diverse and richly annotated video datasets has hindered the development of intelligent systems for surgical workflow analysis. Existing datasets for surgical workflow analysis, which typically face challenges such as small scale, a lack of diversity in surgery and phase categories, and the absence of time-localized annotations, limit the requirements for action understanding and model generalization validation in complex and diverse real-world surgical scenarios. To address this gap, we introduce OphNet, a large-scale, expert-annotated video benchmark for ophthalmic surgical workflow understanding. OphNet features: 1) A diverse collection of 2,278 surgical videos spanning 66 types of cataract, glaucoma, and corneal surgeries, with detailed annotations for 102 unique surgical phases and 150 granular operations; 2) It offers sequential and hierarchical annotations for each surgery, phase, and operation, enabling comprehensive understanding and improved interpretability; 3) Moreover, OphNet provides time-localized annotations, facilitating temporal localization and prediction tasks within surgical workflows. With approximately 205 hours of surgical videos, OphNet is about 20 times larger than the largest existing surgical workflow analysis benchmark. Our dataset and code have been made available at: \url{https://github.com/minghu0830/OphNet-benchmark}.
A Survey of Emerging Applications of Diffusion Probabilistic Models in MRI
Nov 19, 2023



Diffusion probabilistic models (DPMs) which employ explicit likelihood characterization and a gradual sampling process to synthesize data, have gained increasing research interest. Despite their huge computational burdens due to the large number of steps involved during sampling, DPMs are widely appreciated in various medical imaging tasks for their high-quality and diversity of generation. Magnetic resonance imaging (MRI) is an important medical imaging modality with excellent soft tissue contrast and superb spatial resolution, which possesses unique opportunities for diffusion models. Although there is a recent surge of studies exploring DPMs in MRI, a survey paper of DPMs specifically designed for MRI applications is still lacking. This review article aims to help researchers in the MRI community to grasp the advances of DPMs in different applications. We first introduce the theory of two dominant kinds of DPMs, categorized according to whether the diffusion time step is discrete or continuous, and then provide a comprehensive review of emerging DPMs in MRI, including reconstruction, image generation, image translation, segmentation, anomaly detection, and further research topics. Finally, we discuss the general limitations as well as limitations specific to the MRI tasks of DPMs and point out potential areas that are worth further exploration.
Multi-Scale Progressive Fusion Network for Single Image Deraining
Mar 28, 2020
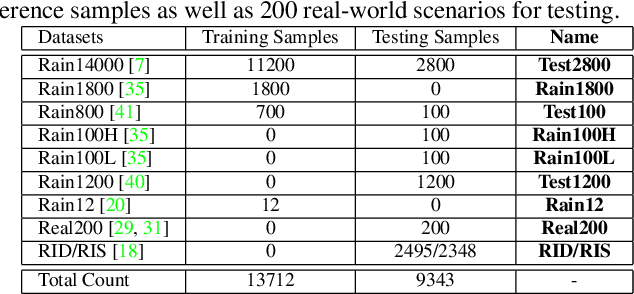
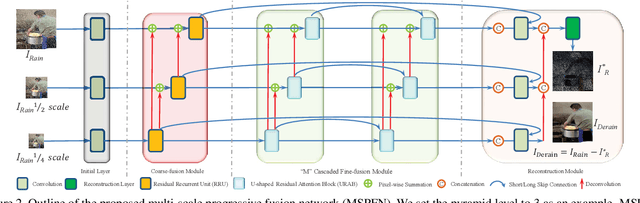
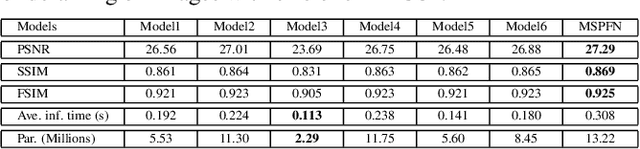
Rain streaks in the air appear in various blurring degrees and resolutions due to different distances from their positions to the camera. Similar rain patterns are visible in a rain image as well as its multi-scale (or multi-resolution) versions, which makes it possible to exploit such complementary information for rain streak representation. In this work, we explore the multi-scale collaborative representation for rain streaks from the perspective of input image scales and hierarchical deep features in a unified framework, termed multi-scale progressive fusion network (MSPFN) for single image rain streak removal. For similar rain streaks at different positions, we employ recurrent calculation to capture the global texture, thus allowing to explore the complementary and redundant information at the spatial dimension to characterize target rain streaks. Besides, we construct multi-scale pyramid structure, and further introduce the attention mechanism to guide the fine fusion of this correlated information from different scales. This multi-scale progressive fusion strategy not only promotes the cooperative representation, but also boosts the end-to-end training. Our proposed method is extensively evaluated on several benchmark datasets and achieves state-of-the-art results. Moreover, we conduct experiments on joint deraining, detection, and segmentation tasks, and inspire a new research direction of vision task-driven image deraining. The source code is available at \url{https://github.com/kuihua/MSPFN}.