 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSGround-R1: Rethinking Remote Sensing Visual Grounding through Spatial Reasoning
Jan 29, 2026Remote Sensing Visual Grounding (RSVG) aims to localize target objects in large-scale aerial imagery based on natural language descriptions. Owing to the vast spatial scale and high semantic ambiguity of remote sensing scenes, these descriptions often rely heavily on positional cues, posing unique challenges for Multimodal Large Language Models (MLLMs) in spatial reasoning. To leverage this unique feature, we propose a reasoning-guided, position-aware post-training framework, dubbed \textbf{RSGround-R1}, to progressively enhance spatial understanding. Specifically, we first introduce Chain-of-Thought Supervised Fine-Tuning (CoT-SFT) using synthetically generated RSVG reasoning data to establish explicit position awareness. Reinforcement Fine-Tuning (RFT) is then applied, augmented by our newly designed positional reward that provides continuous and distance-aware guidance toward accurate localization. Moreover, to mitigate incoherent localization behaviors across rollouts, we introduce a spatial consistency guided optimization scheme that dynamically adjusts policy updates based on their spatial coherence, ensuring stable and robust convergence. Extensive experiments on RSVG benchmarks demonstrate superior performance and generalization of our model.
Understanding the Transfer Limits of Vision Foundation Models
Jan 22, 2026Foundation models leverage large-scale pretraining to capture extensive knowledge, demonstrating generalization in a wide range of language tasks. By comparison, vision foundation models (VFMs) often exhibit uneven improvements across downstream tasks, despite substantial computational investment. We postulate that this limitation arises from a mismatch between pretraining objectives and the demands of downstream vision-and-imaging tasks. Pretraining strategies like masked image reconstruction or contrastive learning shape representations for tasks such as recovery of generic visual patterns or global semantic structures, which may not align with the task-specific requirements of downstream applications including segmentation, classification, or image synthesis. To investigate this in a concrete real-world clinical area, we assess two VFMs, a reconstruction-focused MAE-based model (ProFound) and a contrastive-learning-based model (ProViCNet), on five prostate multiparametric MR imaging tasks, examining how such task alignment influences transfer performance, i.e., from pretraining to fine-tuning. Our findings indicate that better alignment between pretraining and downstream tasks, measured by simple divergence metrics such as maximum-mean-discrepancy (MMD) between the same features before and after fine-tuning, correlates with greater performance improvements and faster convergence, emphasizing the importance of designing and analyzing pretraining objectives with downstream applicability in mind.
Tell2Reg: Establishing spatial correspondence between images by the same language prompts
Feb 05, 2025Spatial correspondence can be represented by pairs of segmented regions, such that the image registration networks aim to segment corresponding regions rather than predicting displacement fields or transformation parameters. In this work, we show that such a corresponding region pair can be predicted by the same language prompt on two different images using the pre-trained large multimodal models based on GroundingDINO and SAM. This enables a fully automated and training-free registration algorithm, potentially generalisable to a wide range of image registration tasks. In this paper, we present experimental results using one of the challenging tasks, registering inter-subject prostate MR images, which involves both highly variable intensity and morphology between patients. Tell2Reg is training-free, eliminating the need for costly and time-consuming data curation and labelling that was previously required for this registration task. This approach outperforms unsupervised learning-based registration methods tested, and has a performance comparable to weakly-supervised methods. Additional qualitative results are also presented to suggest that, for the first time, there is a potential correlation between language semantics and spatial correspondence, including the spatial invariance in language-prompted regions and the difference in language prompts between the obtained local and global correspondences. Code is available at https://github.com/yanwenCi/Tell2Reg.git.
ZoRI: Towards Discriminative Zero-Shot Remote Sensing Instance Segmentation
Dec 17, 2024



Instance segmentation algorithms in remote sensing are typically based on conventional methods, limiting their application to seen scenarios and closed-set predictions. In this work, we propose a novel task called zero-shot remote sensing instance segmentation, aimed at identifying aerial objects that are absent from training data. Challenges arise when classifying aerial categories with high inter-class similarity and intra-class variance. Besides, the domain gap between vision-language models' pretraining datasets and remote sensing datasets hinders the zero-shot capabilities of the pretrained model when it is directly applied to remote sensing images. To address these challenges, we propose a $\textbf{Z}$ero-Sh$\textbf{o}$t $\textbf{R}$emote Sensing $\textbf{I}$nstance Segmentation framework, dubbed $\textbf{ZoRI}$. Our approach features a discrimination-enhanced classifier that uses refined textual embeddings to increase the awareness of class disparities. Instead of direct fine-tuning, we propose a knowledge-maintained adaptation strategy that decouples semantic-related information to preserve the pretrained vision-language alignment while adjusting features to capture remote sensing domain-specific visual cues. Additionally, we introduce a prior-injected prediction with cache bank of aerial visual prototypes to supplement the semantic richness of text embeddings and seamlessly integrate aerial representations, adapting to the remote sensing domain. We establish new experimental protocols and benchmarks, and extensive experiments convincingly demonstrate that ZoRI achieves the state-of-art performance on the zero-shot remote sensing instance segmentation task. Our code is available at https://github.com/HuangShiqi128/ZoRI.
SAMReg: SAM-enabled Image Registration with ROI-based Correspondence
Oct 17, 2024



This paper describes a new spatial correspondence representation based on paired regions-of-interest (ROIs), for medical image registration. The distinct properties of the proposed ROI-based correspondence are discussed, in the context of potential benefits in clinical applications following image registration, compared with alternative correspondence-representing approaches, such as those based on sampled displacements and spatial transformation functions. These benefits include a clear connection between learning-based image registration and segmentation, which in turn motivates two cases of image registration approaches using (pre-)trained segmentation networks. Based on the segment anything model (SAM), a vision foundation model for segmentation, we develop a new registration algorithm SAMReg, which does not require any training (or training data), gradient-based fine-tuning or prompt engineering. The proposed SAMReg models are evaluated across five real-world applications, including intra-subject registration tasks with cardiac MR and lung CT, challenging inter-subject registration scenarios with prostate MR and retinal imaging, and an additional evaluation with a non-clinical example with aerial image registration. The proposed methods outperform both intensity-based iterative algorithms and DDF-predicting learning-based networks across tested metrics including Dice and target registration errors on anatomical structures, and further demonstrates competitive performance compared to weakly-supervised registration approaches that rely on fully-segmented training data. Open source code and examples are available at: https://github.com/sqhuang0103/SAMReg.git.
Competing for pixels: a self-play algorithm for weakly-supervised segmentation
May 26, 2024Weakly-supervised segmentation (WSS) methods, reliant on image-level labels indicating object presence, lack explicit correspondence between labels and regions of interest (ROIs), posing a significant challenge. Despite this, WSS methods have attracted attention due to their much lower annotation costs compared to fully-supervised segmentation. Leveraging reinforcement learning (RL) self-play, we propose a novel WSS method that gamifies image segmentation of a ROI. We formulate segmentation as a competition between two agents that compete to select ROI-containing patches until exhaustion of all such patches. The score at each time-step, used to compute the reward for agent training, represents likelihood of object presence within the selection, determined by an object presence detector pre-trained using only image-level binary classification labels of object presence. Additionally, we propose a game termination condition that can be called by either side upon exhaustion of all ROI-containing patches, followed by the selection of a final patch from each. Upon termination, the agent is incentivised if ROI-containing patches are exhausted or disincentivised if an ROI-containing patch is found by the competitor. This competitive setup ensures minimisation of over- or under-segmentation, a common problem with WSS methods. Extensive experimentation across four datasets demonstrates significant performance improvements over recent state-of-the-art methods. Code: https://github.com/s-sd/spurl/tree/main/wss
One registration is worth two segmentations
May 17, 2024



The goal of image registration is to establish spatial correspondence between two or more images, traditionally through dense displacement fields (DDFs) or parametric transformations (e.g., rigid, affine, and splines). Rethinking the existing paradigms of achieving alignment via spatial transformations, we uncover an alternative but more intuitive correspondence representation: a set of corresponding regions-of-interest (ROI) pairs, which we demonstrate to have sufficient representational capability as other correspondence representation methods.Further, it is neither necessary nor sufficient for these ROIs to hold specific anatomical or semantic significance. In turn, we formulate image registration as searching for the same set of corresponding ROIs from both moving and fixed images - in other words, two multi-class segmentation tasks on a pair of images. For a general-purpose and practical implementation, we integrate the segment anything model (SAM) into our proposed algorithms, resulting in a SAM-enabled registration (SAMReg) that does not require any training data, gradient-based fine-tuning or engineered prompts. We experimentally show that the proposed SAMReg is capable of segmenting and matching multiple ROI pairs, which establish sufficiently accurate correspondences, in three clinical applications of registering prostate MR, cardiac MR and abdominal CT images. Based on metrics including Dice and target registration errors on anatomical structures, the proposed registration outperforms both intensity-based iterative algorithms and DDF-predicting learning-based networks, even yielding competitive performance with weakly-supervised registration which requires fully-segmented training data.
A Survey of Emerging Applications of Diffusion Probabilistic Models in MRI
Nov 19, 2023



Diffusion probabilistic models (DPMs) which employ explicit likelihood characterization and a gradual sampling process to synthesize data, have gained increasing research interest. Despite their huge computational burdens due to the large number of steps involved during sampling, DPMs are widely appreciated in various medical imaging tasks for their high-quality and diversity of generation. Magnetic resonance imaging (MRI) is an important medical imaging modality with excellent soft tissue contrast and superb spatial resolution, which possesses unique opportunities for diffusion models. Although there is a recent surge of studies exploring DPMs in MRI, a survey paper of DPMs specifically designed for MRI applications is still lacking. This review article aims to help researchers in the MRI community to grasp the advances of DPMs in different applications. We first introduce the theory of two dominant kinds of DPMs, categorized according to whether the diffusion time step is discrete or continuous, and then provide a comprehensive review of emerging DPMs in MRI, including reconstruction, image generation, image translation, segmentation, anomaly detection, and further research topics. Finally, we discuss the general limitations as well as limitations specific to the MRI tasks of DPMs and point out potential areas that are worth further exploration.
RTNet: Relation Transformer Network for Diabetic Retinopathy Multi-lesion Segmentation
Jan 26, 2022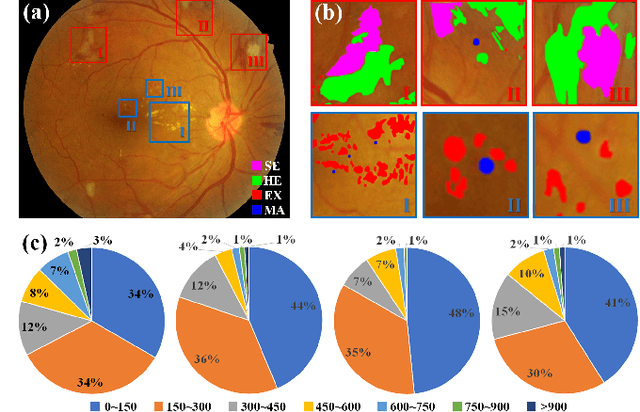

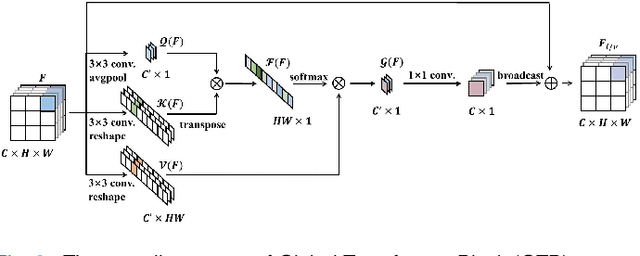
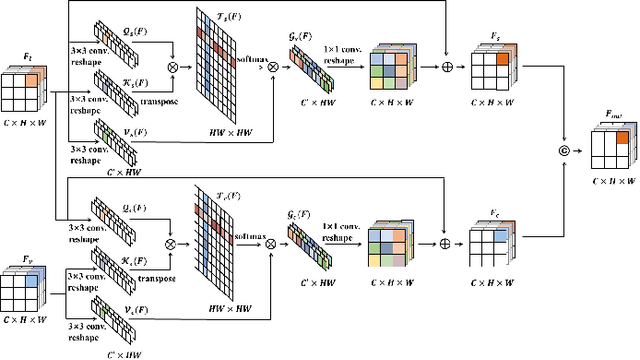
Automatic diabetic retinopathy (DR) lesions segmentation makes great sense of assisting ophthalmologists in diagnosis. Although many researches have been conducted on this task, most prior works paid too much attention to the designs of networks instead of considering the pathological association for lesions. Through investigating the pathogenic causes of DR lesions in advance, we found that certain lesions are closed to specific vessels and present relative patterns to each other. Motivated by the observation, we propose a relation transformer block (RTB) to incorporate attention mechanisms at two main levels: a self-attention transformer exploits global dependencies among lesion features, while a cross-attention transformer allows interactions between lesion and vessel features by integrating valuable vascular information to alleviate ambiguity in lesion detection caused by complex fundus structures. In addition, to capture the small lesion patterns first, we propose a global transformer block (GTB) which preserves detailed information in deep network. By integrating the above blocks of dual-branches, our network segments the four kinds of lesions simultaneously. Comprehensive experiments on IDRiD and DDR datasets well demonstrate the superiority of our approach, which achieves competitive performance compared to state-of-the-arts.