 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-assisted prostate cancer detection and localisation on biparametric MR by classifying radiologist-positives
Oct 30, 2024



Prostate cancer diagnosis through MR imaging have currently relied on radiologists' interpretation, whilst modern AI-based methods have been developed to detect clinically significant cancers independent of radiologists. In this study, we propose to develop deep learning models that improve the overall cancer diagnostic accuracy, by classifying radiologist-identified patients or lesions (i.e. radiologist-positives), as opposed to the existing models that are trained to discriminate over all patients. We develop a single voxel-level classification model, with a simple percentage threshold to determine positive cases, at levels of lesions, Barzell-zones and patients. Based on the presented experiments from two clinical data sets, consisting of histopathology-labelled MR images from more than 800 and 500 patients in the respective UCLA and UCL PROMIS studies, we show that the proposed strategy can improve the diagnostic accuracy, by augmenting the radiologist reading of the MR imaging. Among varying definition of clinical significance, the proposed strategy, for example, achieved a specificity of 44.1% (with AI assistance) from 36.3% (by radiologists alone), at a controlled sensitivity of 80.0% on the publicly available UCLA data set. This provides measurable clinical values in a range of applications such as reducing unnecessary biopsies, lowering cost in cancer screening and quantifying risk in therapies.
Competing for pixels: a self-play algorithm for weakly-supervised segmentation
May 26, 2024Weakly-supervised segmentation (WSS) methods, reliant on image-level labels indicating object presence, lack explicit correspondence between labels and regions of interest (ROIs), posing a significant challenge. Despite this, WSS methods have attracted attention due to their much lower annotation costs compared to fully-supervised segmentation. Leveraging reinforcement learning (RL) self-play, we propose a novel WSS method that gamifies image segmentation of a ROI. We formulate segmentation as a competition between two agents that compete to select ROI-containing patches until exhaustion of all such patches. The score at each time-step, used to compute the reward for agent training, represents likelihood of object presence within the selection, determined by an object presence detector pre-trained using only image-level binary classification labels of object presence. Additionally, we propose a game termination condition that can be called by either side upon exhaustion of all ROI-containing patches, followed by the selection of a final patch from each. Upon termination, the agent is incentivised if ROI-containing patches are exhausted or disincentivised if an ROI-containing patch is found by the competitor. This competitive setup ensures minimisation of over- or under-segmentation, a common problem with WSS methods. Extensive experimentation across four datasets demonstrates significant performance improvements over recent state-of-the-art methods. Code: https://github.com/s-sd/spurl/tree/main/wss
Active learning using adaptable task-based prioritisation
Dec 03, 2022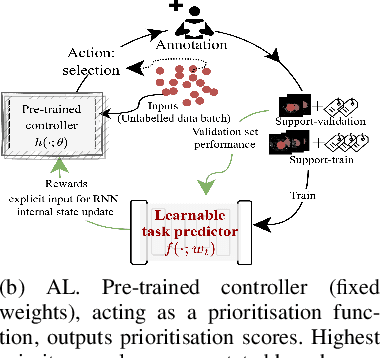
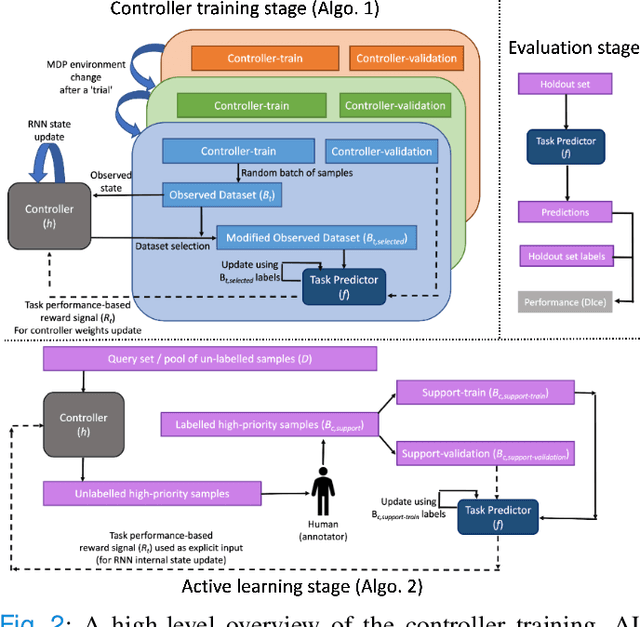
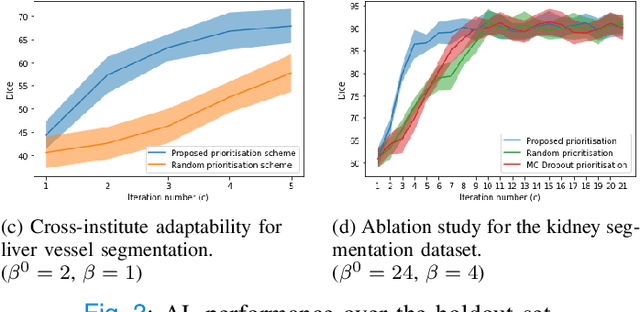
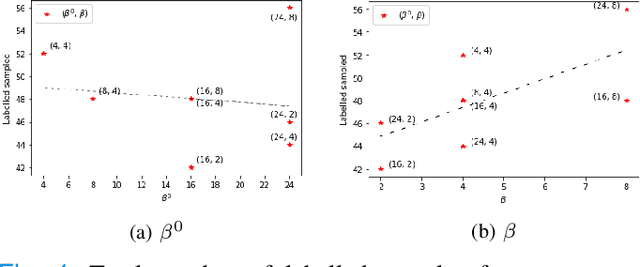
Supervised machine learning-based medical image computing applications necessitate expert label curation, while unlabelled image data might be relatively abundant. Active learning methods aim to prioritise a subset of available image data for expert annotation, for label-efficient model training. We develop a controller neural network that measures priority of images in a sequence of batches, as in batch-mode active learning, for multi-class segmentation tasks. The controller is optimised by rewarding positive task-specific performance gain, within a Markov decision process (MDP) environment that also optimises the task predictor. In this work, the task predictor is a segmentation network. A meta-reinforcement learning algorithm is proposed with multiple MDPs, such that the pre-trained controller can be adapted to a new MDP that contains data from different institutes and/or requires segmentation of different organs or structures within the abdomen. We present experimental results using multiple CT datasets from more than one thousand patients, with segmentation tasks of nine different abdominal organs, to demonstrate the efficacy of the learnt prioritisation controller function and its cross-institute and cross-organ adaptability. We show that the proposed adaptable prioritisation metric yields converging segmentation accuracy for the novel class of kidney, unseen in training, using between approximately 40\% to 60\% of labels otherwise required with other heuristic or random prioritisation metrics. For clinical datasets of limited size, the proposed adaptable prioritisation offers a performance improvement of 22.6\% and 10.2\% in Dice score, for tasks of kidney and liver vessel segmentation, respectively, compared to random prioritisation and alternative active sampling strategies.
Voice-assisted Image Labelling for Endoscopic Ultrasound Classification using Neural Networks
Oct 12, 2021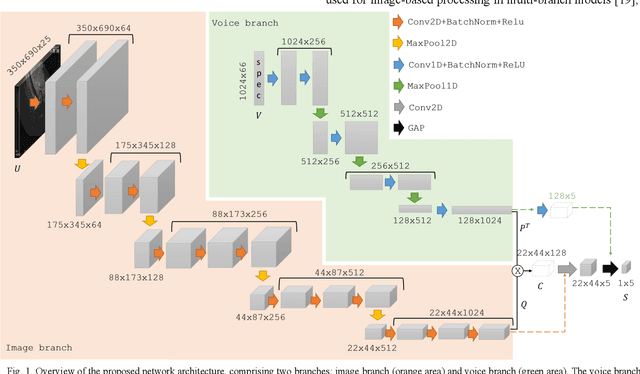
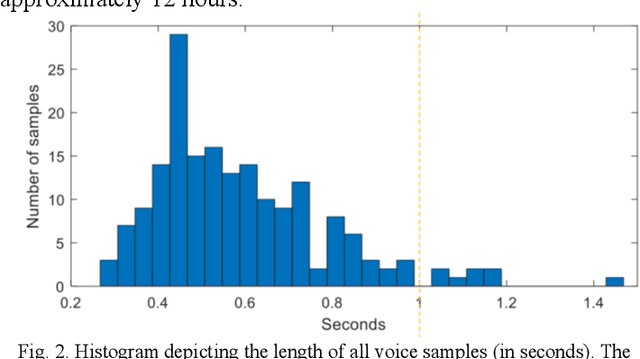
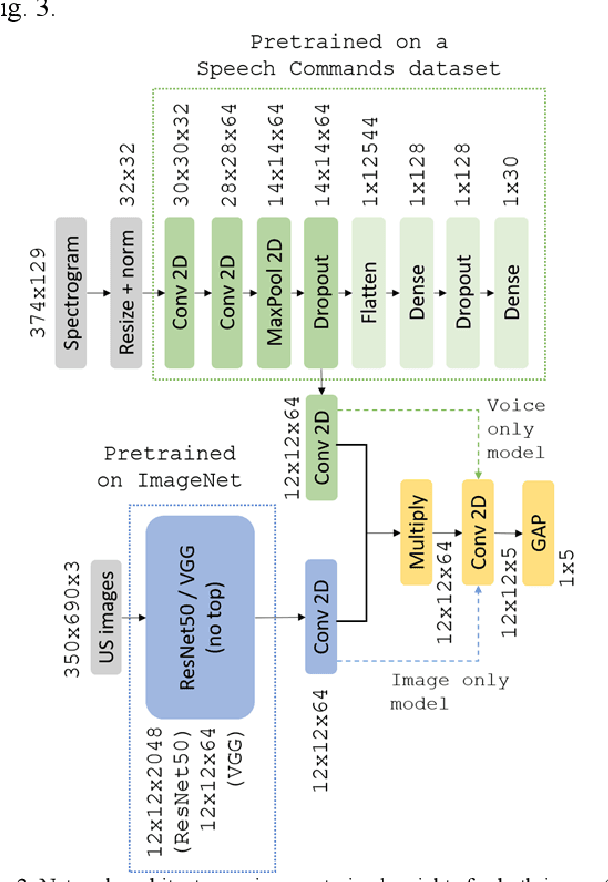
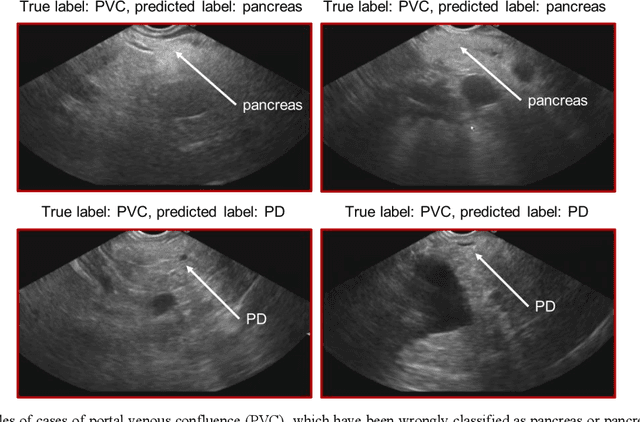
Ultrasound imaging is a commonly used technology for visualising patient anatomy in real-time during diagnostic and therapeutic procedures. High operator dependency and low reproducibility make ultrasound imaging and interpretation challenging with a steep learning curve. Automatic image classification using deep learning has the potential to overcome some of these challenges by supporting ultrasound training in novices, as well as aiding ultrasound image interpretation in patient with complex pathology for more experienced practitioners. However, the use of deep learning methods requires a large amount of data in order to provide accurate results. Labelling large ultrasound datasets is a challenging task because labels are retrospectively assigned to 2D images without the 3D spatial context available in vivo or that would be inferred while visually tracking structures between frames during the procedure. In this work, we propose a multi-modal convolutional neural network (CNN) architecture that labels endoscopic ultrasound (EUS) images from raw verbal comments provided by a clinician during the procedure. We use a CNN composed of two branches, one for voice data and another for image data, which are joined to predict image labels from the spoken names of anatomical landmarks. The network was trained using recorded verbal comments from expert operators. Our results show a prediction accuracy of 76% at image level on a dataset with 5 different labels. We conclude that the addition of spoken commentaries can increase the performance of ultrasound image classification, and eliminate the burden of manually labelling large EUS datasets necessary for deep learning applications.
DeepReg: a deep learning toolkit for medical image registration
Nov 04, 2020DeepReg (https://github.com/DeepRegNet/DeepReg) is a community-supported open-source toolkit for research and education in medical image registration using deep learning.
Assisted Probe Positioning for Ultrasound Guided Radiotherapy Using Image Sequence Classification
Oct 06, 2020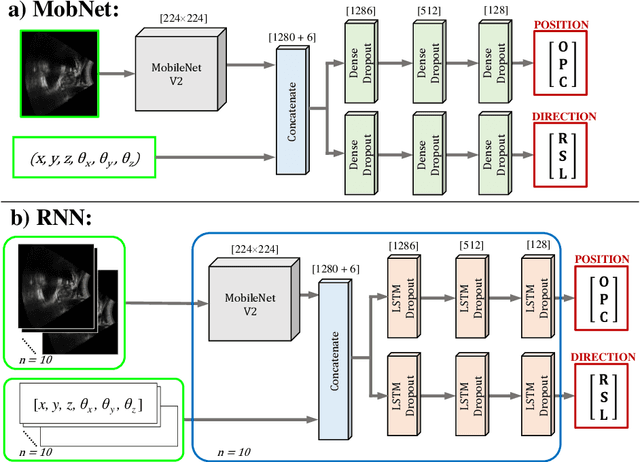
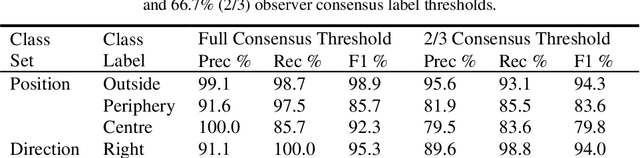
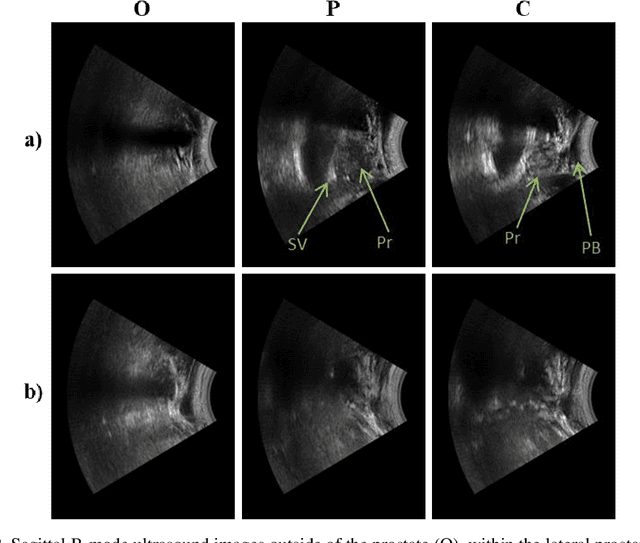
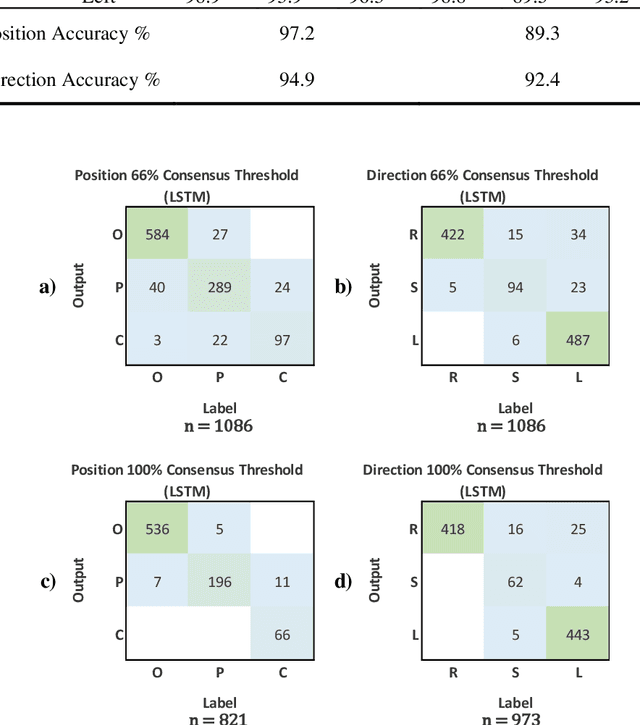
Effective transperineal ultrasound image guidance in prostate external beam radiotherapy requires consistent alignment between probe and prostate at each session during patient set-up. Probe placement and ultrasound image inter-pretation are manual tasks contingent upon operator skill, leading to interoperator uncertainties that degrade radiotherapy precision. We demonstrate a method for ensuring accurate probe placement through joint classification of images and probe position data. Using a multi-input multi-task algorithm, spatial coordinate data from an optically tracked ultrasound probe is combined with an image clas-sifier using a recurrent neural network to generate two sets of predictions in real-time. The first set identifies relevant prostate anatomy visible in the field of view using the classes: outside prostate, prostate periphery, prostate centre. The second set recommends a probe angular adjustment to achieve alignment between the probe and prostate centre with the classes: move left, move right, stop. The algo-rithm was trained and tested on 9,743 clinical images from 61 treatment sessions across 32 patients. We evaluated classification accuracy against class labels de-rived from three experienced observers at 2/3 and 3/3 agreement thresholds. For images with unanimous consensus between observers, anatomical classification accuracy was 97.2% and probe adjustment accuracy was 94.9%. The algorithm identified optimal probe alignment within a mean (standard deviation) range of 3.7$^{\circ}$ (1.2$^{\circ}$) from angle labels with full observer consensus, comparable to the 2.8$^{\circ}$ (2.6$^{\circ}$) mean interobserver range. We propose such an algorithm could assist ra-diotherapy practitioners with limited experience of ultrasound image interpreta-tion by providing effective real-time feedback during patient set-up.
Image quality assessment for closed-loop computer-assisted lung ultrasound
Aug 20, 2020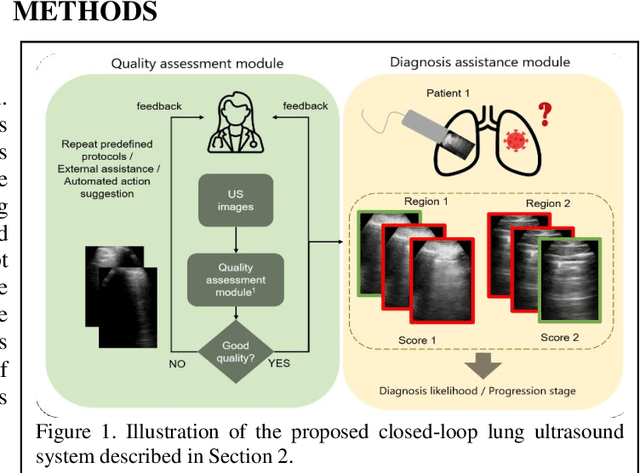
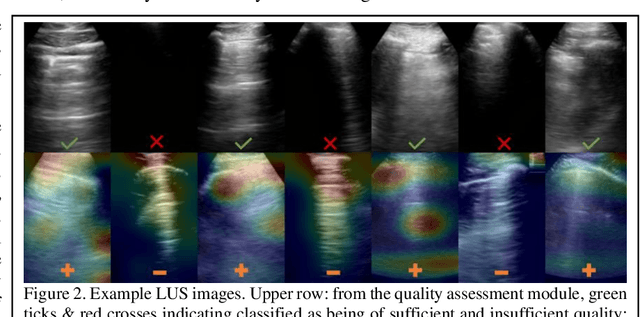
We describe a novel, two-stage computer assistance system for lung anomaly detection using ultrasound imaging in the intensive care setting to improve operator performance and patient stratification during coronavirus pandemics. The proposed system consists of two deep-learning-based models. A quality assessment module automates predictions of image quality, and a diagnosis assistance module determines the likelihood-of-anomaly in ultrasound images of sufficient quality. Our two-stage strategy uses a novelty detection algorithm to address the lack of control cases available for training a quality assessment classifier. The diagnosis assistance module can then be trained with data that are deemed of sufficient quality, guaranteed by the closed-loop feedback mechanism from the quality assessment module. Integrating the two modules yields accurate, fast, and practical acquisition guidance and diagnostic assistance for patients with suspected respiratory conditions at the point-of-care. Using more than 25,000 ultrasound images from 37 COVID-19-positive patients scanned at two hospitals, plus 12 control cases, this study demonstrates the feasibility of using the proposed machine learning approach. We report an accuracy of 86% when classifying between sufficient and insufficient quality images by the quality assessment module. For data of sufficient quality, the mean classification accuracy in detecting COVID-19-positive cases was 95% on five holdout test data sets, unseen during the training of any networks within the proposed system.
Weakly-Supervised Convolutional Neural Networks for Multimodal Image Registration
Jul 09, 2018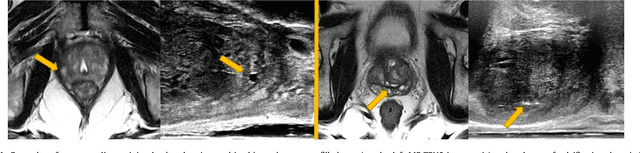


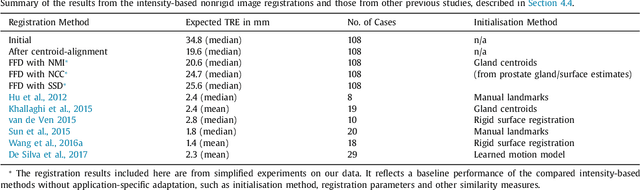
One of the fundamental challenges in supervised learning for multimodal image registration is the lack of ground-truth for voxel-level spatial correspondence. This work describes a method to infer voxel-level transformation from higher-level correspondence information contained in anatomical labels. We argue that such labels are more reliable and practical to obtain for reference sets of image pairs than voxel-level correspondence. Typical anatomical labels of interest may include solid organs, vessels, ducts, structure boundaries and other subject-specific ad hoc landmarks. The proposed end-to-end convolutional neural network approach aims to predict displacement fields to align multiple labelled corresponding structures for individual image pairs during the training, while only unlabelled image pairs are used as the network input for inference. We highlight the versatility of the proposed strategy, for training, utilising diverse types of anatomical labels, which need not to be identifiable over all training image pairs. At inference, the resulting 3D deformable image registration algorithm runs in real-time and is fully-automated without requiring any anatomical labels or initialisation. Several network architecture variants are compared for registering T2-weighted magnetic resonance images and 3D transrectal ultrasound images from prostate cancer patients. A median target registration error of 3.6 mm on landmark centroids and a median Dice of 0.87 on prostate glands are achieved from cross-validation experiments, in which 108 pairs of multimodal images from 76 patients were tested with high-quality anatomical labels.
Adversarial Deformation Regularization for Training Image Registration Neural Networks
May 27, 2018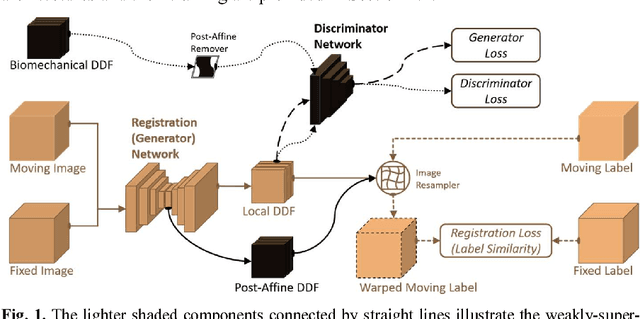
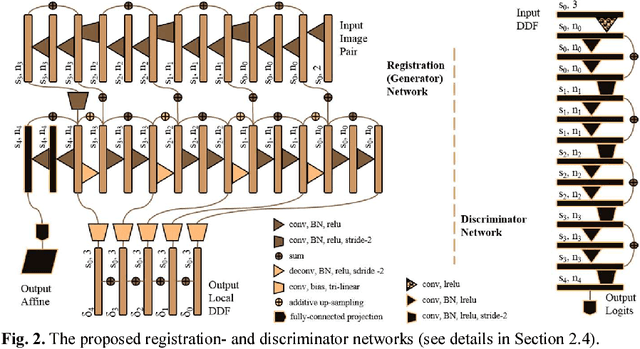
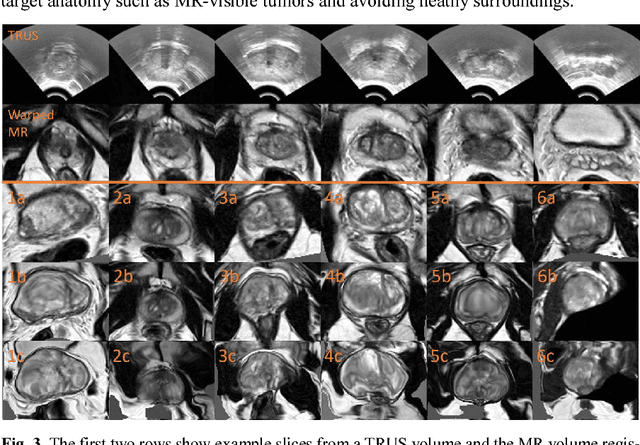
We describe an adversarial learning approach to constrain convolutional neural network training for image registration, replacing heuristic smoothness measures of displacement fields often used in these tasks. Using minimally-invasive prostate cancer intervention as an example application, we demonstrate the feasibility of utilizing biomechanical simulations to regularize a weakly-supervised anatomical-label-driven registration network for aligning pre-procedural magnetic resonance (MR) and 3D intra-procedural transrectal ultrasound (TRUS) images. A discriminator network is optimized to distinguish the registration-predicted displacement fields from the motion data simulated by finite element analysis. During training, the registration network simultaneously aims to maximize similarity between anatomical labels that drives image alignment and to minimize an adversarial generator loss that measures divergence between the predicted- and simulated deformation. The end-to-end trained network enables efficient and fully-automated registration that only requires an MR and TRUS image pair as input, without anatomical labels or simulated data during inference. 108 pairs of labelled MR and TRUS images from 76 prostate cancer patients and 71,500 nonlinear finite-element simulations from 143 different patients were used for this study. We show that, with only gland segmentation as training labels, the proposed method can help predict physically plausible deformation without any other smoothness penalty. Based on cross-validation experiments using 834 pairs of independent validation landmarks, the proposed adversarial-regularized registration achieved a target registration error of 6.3 mm that is significantly lower than those from several other regularization methods.
Label-driven weakly-supervised learning for multimodal deformable image registration
Dec 24, 2017Spatially aligning medical images from different modalities remains a challenging task, especially for intraoperative applications that require fast and robust algorithms. We propose a weakly-supervised, label-driven formulation for learning 3D voxel correspondence from higher-level label correspondence, thereby bypassing classical intensity-based image similarity measures. During training, a convolutional neural network is optimised by outputting a dense displacement field (DDF) that warps a set of available anatomical labels from the moving image to match their corresponding counterparts in the fixed image. These label pairs, including solid organs, ducts, vessels, point landmarks and other ad hoc structures, are only required at training time and can be spatially aligned by minimising a cross-entropy function of the warped moving label and the fixed label. During inference, the trained network takes a new image pair to predict an optimal DDF, resulting in a fully-automatic, label-free, real-time and deformable registration. For interventional applications where large global transformation prevails, we also propose a neural network architecture to jointly optimise the global- and local displacements. Experiment results are presented based on cross-validating registrations of 111 pairs of T2-weighted magnetic resonance images and 3D transrectal ultrasound images from prostate cancer patients with a total of over 4000 anatomical labels, yielding a median target registration error of 4.2 mm on landmark centroids and a median Dice of 0.88 on prostate glands.