 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised Convolutional Neural Networks for Multimodal Image Registration
Jul 09, 2018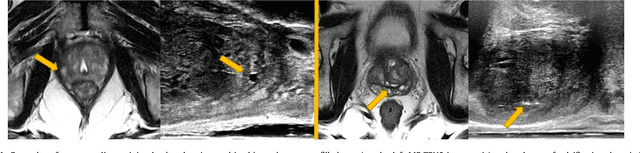


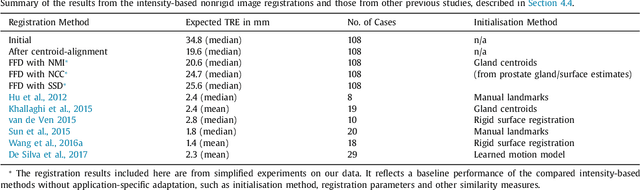
One of the fundamental challenges in supervised learning for multimodal image registration is the lack of ground-truth for voxel-level spatial correspondence. This work describes a method to infer voxel-level transformation from higher-level correspondence information contained in anatomical labels. We argue that such labels are more reliable and practical to obtain for reference sets of image pairs than voxel-level correspondence. Typical anatomical labels of interest may include solid organs, vessels, ducts, structure boundaries and other subject-specific ad hoc landmarks. The proposed end-to-end convolutional neural network approach aims to predict displacement fields to align multiple labelled corresponding structures for individual image pairs during the training, while only unlabelled image pairs are used as the network input for inference. We highlight the versatility of the proposed strategy, for training, utilising diverse types of anatomical labels, which need not to be identifiable over all training image pairs. At inference, the resulting 3D deformable image registration algorithm runs in real-time and is fully-automated without requiring any anatomical labels or initialisation. Several network architecture variants are compared for registering T2-weighted magnetic resonance images and 3D transrectal ultrasound images from prostate cancer patients. A median target registration error of 3.6 mm on landmark centroids and a median Dice of 0.87 on prostate glands are achieved from cross-validation experiments, in which 108 pairs of multimodal images from 76 patients were tested with high-quality anatomical labels.