 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiF-VLA: Hindsight, Insight and Foresight through Motion Representation for Vision-Language-Action Models
Dec 10, 2025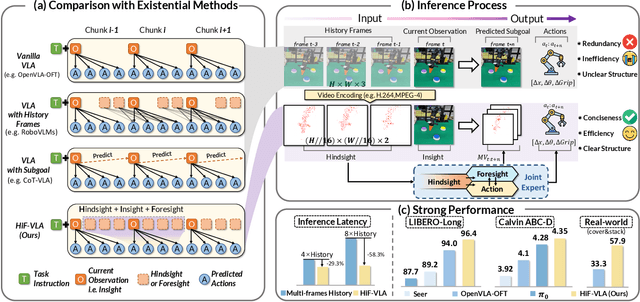
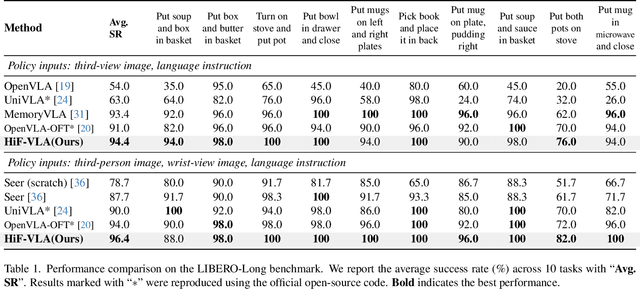
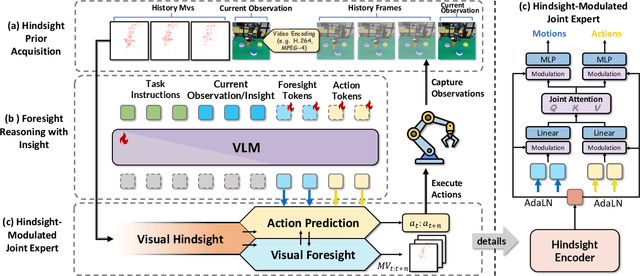
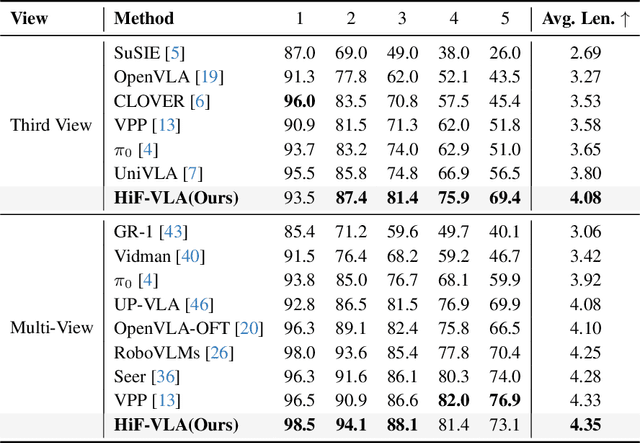
Vision-Language-Action (VLA) models have recently enabled robotic manipulation by grounding visual and linguistic cues into actions. However, most VLAs assume the Markov property, relying only on the current observation and thus suffering from temporal myopia that degrades long-horizon coherence. In this work, we view motion as a more compact and informative representation of temporal context and world dynamics, capturing inter-state changes while filtering static pixel-level noise. Building on this idea, we propose HiF-VLA (Hindsight, Insight, and Foresight for VLAs), a unified framework that leverages motion for bidirectional temporal reasoning. HiF-VLA encodes past dynamics through hindsight priors, anticipates future motion via foresight reasoning, and integrates both through a hindsight-modulated joint expert to enable a ''think-while-acting'' paradigm for long-horizon manipulation. As a result, HiF-VLA surpasses strong baselines on LIBERO-Long and CALVIN ABC-D benchmarks, while incurring negligible additional inference latency. Furthermore, HiF-VLA achieves substantial improvements in real-world long-horizon manipulation tasks, demonstrating its broad effectiveness in practical robotic settings.
VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
Sep 11, 2025Vision-Language-Action (VLA) models typically bridge the gap between perceptual and action spaces by pre-training a large-scale Vision-Language Model (VLM) on robotic data. While this approach greatly enhances performance, it also incurs significant training costs. In this paper, we investigate how to effectively bridge vision-language (VL) representations to action (A). We introduce VLA-Adapter, a novel paradigm designed to reduce the reliance of VLA models on large-scale VLMs and extensive pre-training. To this end, we first systematically analyze the effectiveness of various VL conditions and present key findings on which conditions are essential for bridging perception and action spaces. Based on these insights, we propose a lightweight Policy module with Bridge Attention, which autonomously injects the optimal condition into the action space. In this way, our method achieves high performance using only a 0.5B-parameter backbone, without any robotic data pre-training. Extensive experiments on both simulated and real-world robotic benchmarks demonstrate that VLA-Adapter not only achieves state-of-the-art level performance, but also offers the fast inference speed reported to date. Furthermore, thanks to the proposed advanced bridging paradigm, VLA-Adapter enables the training of a powerful VLA model in just 8 hours on a single consumer-grade GPU, greatly lowering the barrier to deploying the VLA model. Project page: https://vla-adapter.github.io/.
Long-VLA: Unleashing Long-Horizon Capability of Vision Language Action Model for Robot Manipulation
Aug 28, 2025Vision-Language-Action (VLA) models have become a cornerstone in robotic policy learning, leveraging large-scale multimodal data for robust and scalable control. However, existing VLA frameworks primarily address short-horizon tasks, and their effectiveness on long-horizon, multi-step robotic manipulation remains limited due to challenges in skill chaining and subtask dependencies. In this work, we introduce Long-VLA, the first end-to-end VLA model specifically designed for long-horizon robotic tasks. Our approach features a novel phase-aware input masking strategy that adaptively segments each subtask into moving and interaction phases, enabling the model to focus on phase-relevant sensory cues and enhancing subtask compatibility. This unified strategy preserves the scalability and data efficiency of VLA training, and our architecture-agnostic module can be seamlessly integrated into existing VLA models. We further propose the L-CALVIN benchmark to systematically evaluate long-horizon manipulation. Extensive experiments on both simulated and real-world tasks demonstrate that Long-VLA significantly outperforms prior state-of-the-art methods, establishing a new baseline for long-horizon robotic control.
A2Seek: Towards Reasoning-Centric Benchmark for Aerial Anomaly Understanding
May 28, 2025While unmanned aerial vehicles (UAVs) offer wide-area, high-altitude coverage for anomaly detection, they face challenges such as dynamic viewpoints, scale variations, and complex scenes. Existing datasets and methods, mainly designed for fixed ground-level views, struggle to adapt to these conditions, leading to significant performance drops in drone-view scenarios. To bridge this gap, we introduce A2Seek (Aerial Anomaly Seek), a large-scale, reasoning-centric benchmark dataset for aerial anomaly understanding. This dataset covers various scenarios and environmental conditions, providing high-resolution real-world aerial videos with detailed annotations, including anomaly categories, frame-level timestamps, region-level bounding boxes, and natural language explanations for causal reasoning. Building on this dataset, we propose A2Seek-R1, a novel reasoning framework that generalizes R1-style strategies to aerial anomaly understanding, enabling a deeper understanding of "Where" anomalies occur and "Why" they happen in aerial frames. To this end, A2Seek-R1 first employs a graph-of-thought (GoT)-guided supervised fine-tuning approach to activate the model's latent reasoning capabilities on A2Seek. Then, we introduce Aerial Group Relative Policy Optimization (A-GRPO) to design rule-based reward functions tailored to aerial scenarios. Furthermore, we propose a novel "seeking" mechanism that simulates UAV flight behavior by directing the model's attention to informative regions. Extensive experiments demonstrate that A2Seek-R1 achieves up to a 22.04% improvement in AP for prediction accuracy and a 13.9% gain in mIoU for anomaly localization, exhibiting strong generalization across complex environments and out-of-distribution scenarios. Our dataset and code will be released at https://hayneyday.github.io/A2Seek/.
OpenHelix: A Short Survey, Empirical Analysis, and Open-Source Dual-System VLA Model for Robotic Manipulation
May 06, 2025



Dual-system VLA (Vision-Language-Action) architectures have become a hot topic in embodied intelligence research, but there is a lack of sufficient open-source work for further performance analysis and optimization. To address this problem, this paper will summarize and compare the structural designs of existing dual-system architectures, and conduct systematic empirical evaluations on the core design elements of existing dual-system architectures. Ultimately, it will provide a low-cost open-source model for further exploration. Of course, this project will continue to update with more experimental conclusions and open-source models with improved performance for everyone to choose from. Project page: https://openhelix-robot.github.io/.
MoRE: Unlocking Scalability in Reinforcement Learning for Quadruped Vision-Language-Action Models
Mar 11, 2025Developing versatile quadruped robots that can smoothly perform various actions and tasks in real-world environments remains a significant challenge. This paper introduces a novel vision-language-action (VLA) model, mixture of robotic experts (MoRE), for quadruped robots that aim to introduce reinforcement learning (RL) for fine-tuning large-scale VLA models with a large amount of mixed-quality data. MoRE integrates multiple low-rank adaptation modules as distinct experts within a dense multi-modal large language model (MLLM), forming a sparse-activated mixture-of-experts model. This design enables the model to effectively adapt to a wide array of downstream tasks. Moreover, we employ a reinforcement learning-based training objective to train our model as a Q-function after deeply exploring the structural properties of our tasks. Effective learning from automatically collected mixed-quality data enhances data efficiency and model performance. Extensive experiments demonstrate that MoRE outperforms all baselines across six different skills and exhibits superior generalization capabilities in out-of-distribution scenarios. We further validate our method in real-world scenarios, confirming the practicality of our approach and laying a solid foundation for future research on multi-task learning in quadruped robots.
Humanoid-VLA: Towards Universal Humanoid Control with Visual Integration
Feb 21, 2025This paper addresses the limitations of current humanoid robot control frameworks, which primarily rely on reactive mechanisms and lack autonomous interaction capabilities due to data scarcity. We propose Humanoid-VLA, a novel framework that integrates language understanding, egocentric scene perception, and motion control, enabling universal humanoid control. Humanoid-VLA begins with language-motion pre-alignment using non-egocentric human motion datasets paired with textual descriptions, allowing the model to learn universal motion patterns and action semantics. We then incorporate egocentric visual context through a parameter efficient video-conditioned fine-tuning, enabling context-aware motion generation. Furthermore, we introduce a self-supervised data augmentation strategy that automatically generates pseudoannotations directly derived from motion data. This process converts raw motion sequences into informative question-answer pairs, facilitating the effective use of large-scale unlabeled video data. Built upon whole-body control architectures, extensive experiments show that Humanoid-VLA achieves object interaction and environment exploration tasks with enhanced contextual awareness, demonstrating a more human-like capacity for adaptive and intelligent engagement.
QUART-Online: Latency-Free Large Multimodal Language Model for Quadruped Robot Learning
Dec 23, 2024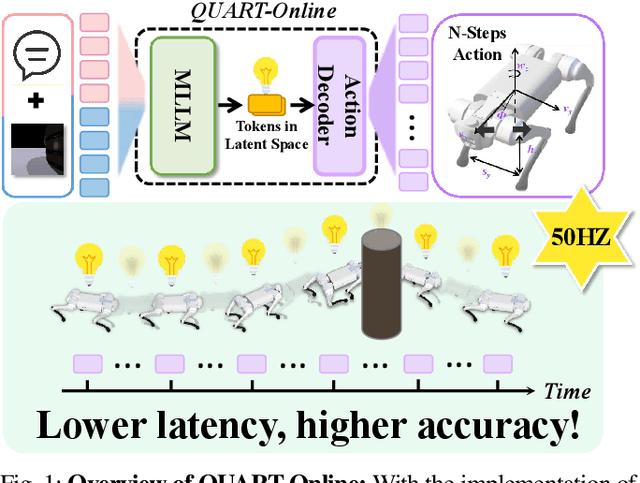
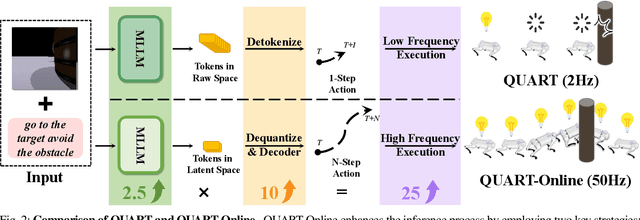
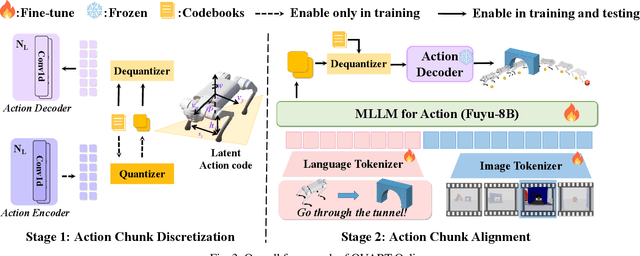
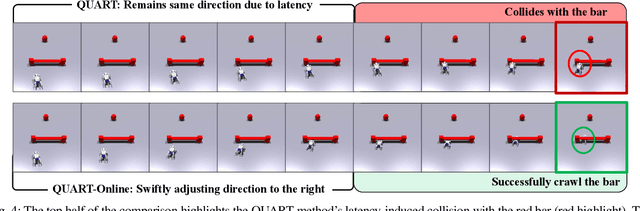
This paper addresses the inherent inference latency challenges associated with deploying multimodal large language models (MLLM) in quadruped vision-language-action (QUAR-VLA) tasks. Our investigation reveals that conventional parameter reduction techniques ultimately impair the performance of the language foundation model during the action instruction tuning phase, making them unsuitable for this purpose. We introduce a novel latency-free quadruped MLLM model, dubbed QUART-Online, designed to enhance inference efficiency without degrading the performance of the language foundation model. By incorporating Action Chunk Discretization (ACD), we compress the original action representation space, mapping continuous action values onto a smaller set of discrete representative vectors while preserving critical information. Subsequently, we fine-tune the MLLM to integrate vision, language, and compressed actions into a unified semantic space. Experimental results demonstrate that QUART-Online operates in tandem with the existing MLLM system, achieving real-time inference in sync with the underlying controller frequency, significantly boosting the success rate across various tasks by 65%. Our project page is https://quart-online.github.io.