 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEUBRL: Epistemic Uncertainty Directed Bayesian Reinforcement Learning
Dec 17, 2025At the boundary between the known and the unknown, an agent inevitably confronts the dilemma of whether to explore or to exploit. Epistemic uncertainty reflects such boundaries, representing systematic uncertainty due to limited knowledge. In this paper, we propose a Bayesian reinforcement learning (RL) algorithm, $\texttt{EUBRL}$, which leverages epistemic guidance to achieve principled exploration. This guidance adaptively reduces per-step regret arising from estimation errors. We establish nearly minimax-optimal regret and sample complexity guarantees for a class of sufficiently expressive priors in infinite-horizon discounted MDPs. Empirically, we evaluate $\texttt{EUBRL}$ on tasks characterized by sparse rewards, long horizons, and stochasticity. Results demonstrate that $\texttt{EUBRL}$ achieves superior sample efficiency, scalability, and consistency.
Learning to Look at the Other Side: A Semantic Probing Study of Word Embeddings in LLMs with Enabled Bidirectional Attention
Oct 02, 2025Autoregressive Large Language Models (LLMs) demonstrate exceptional performance in language understanding and generation. However, their application in text embedding tasks has been relatively slow, along with the analysis of their semantic representation in probing tasks, due to the constraints of the unidirectional attention mechanism. This paper aims to explore whether such constraints can be overcome by enabling bidirectional attention in LLMs. We tested different variants of the Llama architecture through additional training steps, progressively enabling bidirectional attention and unsupervised/supervised contrastive learning.
From BERT to LLMs: Comparing and Understanding Chinese Classifier Prediction in Language Models
Aug 25, 2025Classifiers are an important and defining feature of the Chinese language, and their correct prediction is key to numerous educational applications. Yet, whether the most popular Large Language Models (LLMs) possess proper knowledge the Chinese classifiers is an issue that has largely remain unexplored in the Natural Language Processing (NLP) literature. To address such a question, we employ various masking strategies to evaluate the LLMs' intrinsic ability, the contribution of different sentence elements, and the working of the attention mechanisms during prediction. Besides, we explore fine-tuning for LLMs to enhance the classifier performance. Our findings reveal that LLMs perform worse than BERT, even with fine-tuning. The prediction, as expected, greatly benefits from the information about the following noun, which also explains the advantage of models with a bidirectional attention mechanism such as BERT.
Humanoid-VLA: Towards Universal Humanoid Control with Visual Integration
Feb 21, 2025This paper addresses the limitations of current humanoid robot control frameworks, which primarily rely on reactive mechanisms and lack autonomous interaction capabilities due to data scarcity. We propose Humanoid-VLA, a novel framework that integrates language understanding, egocentric scene perception, and motion control, enabling universal humanoid control. Humanoid-VLA begins with language-motion pre-alignment using non-egocentric human motion datasets paired with textual descriptions, allowing the model to learn universal motion patterns and action semantics. We then incorporate egocentric visual context through a parameter efficient video-conditioned fine-tuning, enabling context-aware motion generation. Furthermore, we introduce a self-supervised data augmentation strategy that automatically generates pseudoannotations directly derived from motion data. This process converts raw motion sequences into informative question-answer pairs, facilitating the effective use of large-scale unlabeled video data. Built upon whole-body control architectures, extensive experiments show that Humanoid-VLA achieves object interaction and environment exploration tasks with enhanced contextual awareness, demonstrating a more human-like capacity for adaptive and intelligent engagement.
Discerning Temporal Difference Learning
Oct 12, 2023Temporal difference learning (TD) is a foundational concept in reinforcement learning (RL), aimed at efficiently assessing a policy's value function. TD($\lambda$), a potent variant, incorporates a memory trace to distribute the prediction error into the historical context. However, this approach often neglects the significance of historical states and the relative importance of propagating the TD error, influenced by challenges such as visitation imbalance or outcome noise. To address this, we propose a novel TD algorithm named discerning TD learning (DTD), which allows flexible emphasis functions$-$predetermined or adapted during training$-$to allocate efforts effectively across states. We establish the convergence properties of our method within a specific class of emphasis functions and showcase its promising potential for adaptation to deep RL contexts. Empirical results underscore that employing a judicious emphasis function not only improves value estimation but also expedites learning across diverse scenarios.
Generative Intrinsic Optimization: Intrisic Control with Model Learning
Oct 12, 2023Future sequence represents the outcome after executing the action into the environment. When driven by the information-theoretic concept of mutual information, it seeks maximally informative consequences. Explicit outcomes may vary across state, return, or trajectory serving different purposes such as credit assignment or imitation learning. However, the inherent nature of incorporating intrinsic motivation with reward maximization is often neglected. In this work, we propose a variational approach to jointly learn the necessary quantity for estimating the mutual information and the dynamics model, providing a general framework for incorporating different forms of outcomes of interest. Integrated into a policy iteration scheme, our approach guarantees convergence to the optimal policy. While we mainly focus on theoretical analysis, our approach opens the possibilities of leveraging intrinsic control with model learning to enhance sample efficiency and incorporate uncertainty of the environment into decision-making.
The Point to Which Soft Actor-Critic Converges
Mar 06, 2023Soft actor-critic is a successful successor over soft Q-learning. While lived under maximum entropy framework, their relationship is still unclear. In this paper, we prove that in the limit they converge to the same solution. This is appealing since it translates the optimization from an arduous to an easier way. The same justification can also be applied to other regularizers such as KL divergence.
Distillation Policy Optimization
Feb 02, 2023



On-policy algorithms are supposed to be stable, however, sample-intensive yet. Off-policy algorithms utilizing past experiences are deemed to be sample-efficient, nevertheless, unstable in general. Can we design an algorithm that can employ the off-policy data, while exploit the stable learning by sailing along the course of the on-policy walkway? In this paper, we present an actor-critic learning framework that borrows the distributional perspective of interest to evaluate, and cross-breeds two sources of the data for policy improvement, which enables fast learning and can be applied to a wide class of algorithms. In its backbone, the variance reduction mechanisms, such as unified advantage estimator (UAE), that extends generalized advantage estimator (GAE) to be applicable on any state-dependent baseline, and a learned baseline, that is competent to stabilize the policy gradient, are firstly put forward to not merely be a bridge to the action-value function but also distill the advantageous learning signal. Lastly, it is empirically shown that our method improves sample efficiency and interpolates different levels well. Being of an organic whole, its mixture places more inspiration to the algorithm design.
Entropy Augmented Reinforcement Learning
Aug 19, 2022

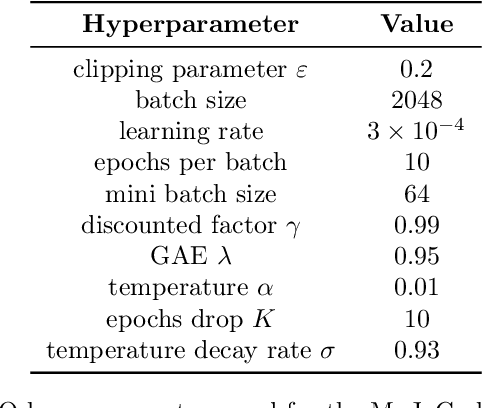

Deep reinforcement learning has gained a lot of success with the presence of trust region policy optimization (TRPO) and proximal policy optimization (PPO), for their scalability and efficiency. However, the pessimism of both algorithms, among which it either is constrained in a trust region or strictly excludes all suspicious gradients, has been proven to suppress the exploration and harm the performance of the agent. To address those issues, we propose a shifted Markov decision process (MDP), or rather, with entropy augmentation, to encourage the exploration and reinforce the ability of escaping from suboptimums. Our method is extensible and adapts to either reward shaping or bootstrapping. With convergence analysis given, we find it is crucial to control the temperature coefficient. However, if appropriately tuning it, we can achieve remarkable performance, even on other algorithms, since it is simple yet effective. Our experiments test augmented TRPO and PPO on MuJoCo benchmark tasks, of an indication that the agent is heartened towards higher reward regions, and enjoys a balance between exploration and exploitation. We verify the exploration bonus of our method on two grid world environments.