 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Signal and Variance: Adaptive Offline RL Post-Training for VLA Flow Models
Sep 04, 2025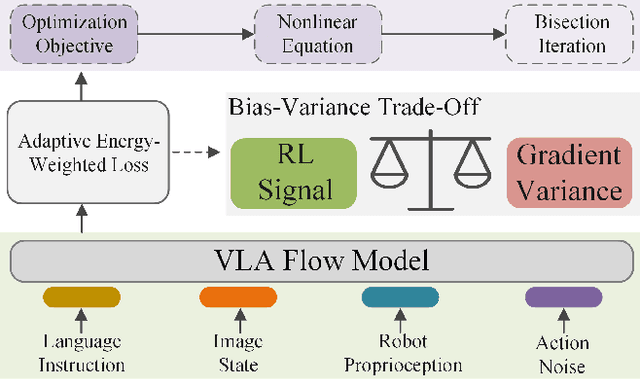
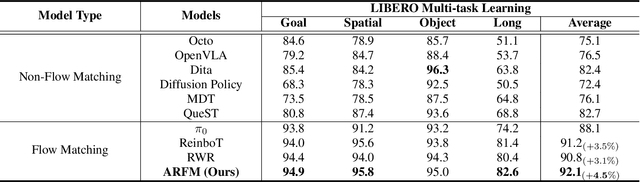

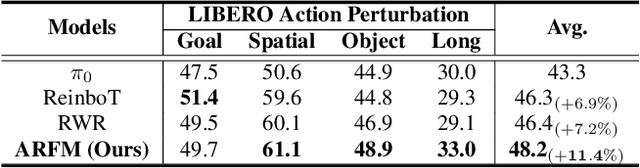
Vision-Language-Action (VLA) models based on flow matching have shown excellent performance in general-purpose robotic manipulation tasks. However, the action accuracy of these models on complex downstream tasks is unsatisfactory. One important reason is that these models rely solely on the post-training paradigm of imitation learning, which makes it difficult to have a deeper understanding of the distribution properties of data quality, which is exactly what Reinforcement Learning (RL) excels at. In this paper, we theoretically propose an offline RL post-training objective for VLA flow models and induce an efficient and feasible offline RL fine-tuning algorithm -- Adaptive Reinforced Flow Matching (ARFM). By introducing an adaptively adjusted scaling factor in the VLA flow model loss, we construct a principled bias-variance trade-off objective function to optimally control the impact of RL signal on flow loss. ARFM adaptively balances RL advantage preservation and flow loss gradient variance control, resulting in a more stable and efficient fine-tuning process. Extensive simulation and real-world experimental results show that ARFM exhibits excellent generalization, robustness, few-shot learning, and continuous learning performance.
Long-VLA: Unleashing Long-Horizon Capability of Vision Language Action Model for Robot Manipulation
Aug 28, 2025Vision-Language-Action (VLA) models have become a cornerstone in robotic policy learning, leveraging large-scale multimodal data for robust and scalable control. However, existing VLA frameworks primarily address short-horizon tasks, and their effectiveness on long-horizon, multi-step robotic manipulation remains limited due to challenges in skill chaining and subtask dependencies. In this work, we introduce Long-VLA, the first end-to-end VLA model specifically designed for long-horizon robotic tasks. Our approach features a novel phase-aware input masking strategy that adaptively segments each subtask into moving and interaction phases, enabling the model to focus on phase-relevant sensory cues and enhancing subtask compatibility. This unified strategy preserves the scalability and data efficiency of VLA training, and our architecture-agnostic module can be seamlessly integrated into existing VLA models. We further propose the L-CALVIN benchmark to systematically evaluate long-horizon manipulation. Extensive experiments on both simulated and real-world tasks demonstrate that Long-VLA significantly outperforms prior state-of-the-art methods, establishing a new baseline for long-horizon robotic control.
ReinboT: Amplifying Robot Visual-Language Manipulation with Reinforcement Learning
May 12, 2025Vision-Language-Action (VLA) models have shown great potential in general robotic decision-making tasks via imitation learning. However, the variable quality of training data often constrains the performance of these models. On the other hand, offline Reinforcement Learning (RL) excels at learning robust policy models from mixed-quality data. In this paper, we introduce Reinforced robot GPT (ReinboT), a novel end-to-end VLA model that integrates the RL principle of maximizing cumulative reward. ReinboT achieves a deeper understanding of the data quality distribution by predicting dense returns that capture the nuances of manipulation tasks. The dense return prediction capability enables the robot to generate more robust decision-making actions, oriented towards maximizing future benefits. Extensive experiments show that ReinboT achieves state-of-the-art performance on the CALVIN mixed-quality dataset and exhibits superior few-shot learning and out-of-distribution generalization capabilities in real-world tasks.
Humanoid-VLA: Towards Universal Humanoid Control with Visual Integration
Feb 21, 2025This paper addresses the limitations of current humanoid robot control frameworks, which primarily rely on reactive mechanisms and lack autonomous interaction capabilities due to data scarcity. We propose Humanoid-VLA, a novel framework that integrates language understanding, egocentric scene perception, and motion control, enabling universal humanoid control. Humanoid-VLA begins with language-motion pre-alignment using non-egocentric human motion datasets paired with textual descriptions, allowing the model to learn universal motion patterns and action semantics. We then incorporate egocentric visual context through a parameter efficient video-conditioned fine-tuning, enabling context-aware motion generation. Furthermore, we introduce a self-supervised data augmentation strategy that automatically generates pseudoannotations directly derived from motion data. This process converts raw motion sequences into informative question-answer pairs, facilitating the effective use of large-scale unlabeled video data. Built upon whole-body control architectures, extensive experiments show that Humanoid-VLA achieves object interaction and environment exploration tasks with enhanced contextual awareness, demonstrating a more human-like capacity for adaptive and intelligent engagement.
Phase Space Reconstruction Network for Lane Intrusion Action Recognition
Feb 22, 2021

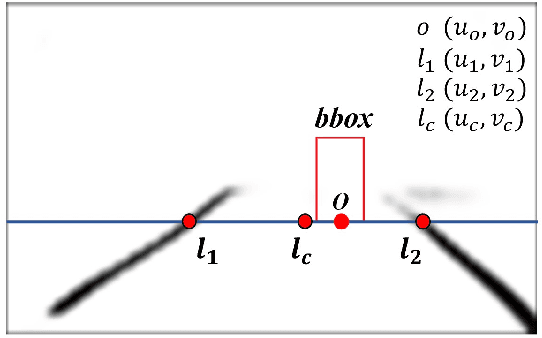
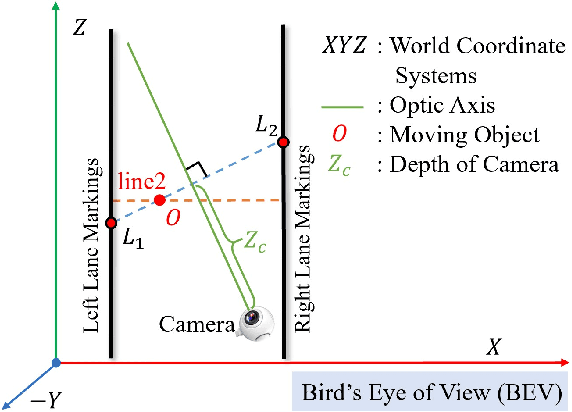
In a complex road traffic scene, illegal lane intrusion of pedestrians or cyclists constitutes one of the main safety challenges in autonomous driving application. In this paper, we propose a novel object-level phase space reconstruction network (PSRNet) for motion time series classification, aiming to recognize lane intrusion actions that occur 150m ahead through a monocular camera fixed on moving vehicle. In the PSRNet, the movement of pedestrians and cyclists, specifically viewed as an observable object-level dynamic process, can be reconstructed as trajectories of state vectors in a latent phase space and further characterized by a learnable Lyapunov exponent-like classifier that indicates discrimination in terms of average exponential divergence of state trajectories. Additionally, in order to first transform video inputs into one-dimensional motion time series of each object, a lane width normalization based on visual object tracking-by-detection is presented. Extensive experiments are conducted on the THU-IntrudBehavior dataset collected from real urban roads. The results show that our PSRNet could reach the best accuracy of 98.0%, which remarkably exceeds existing action recognition approaches by more than 30%.
Fast Object Detection in Compressed Video
Nov 27, 2018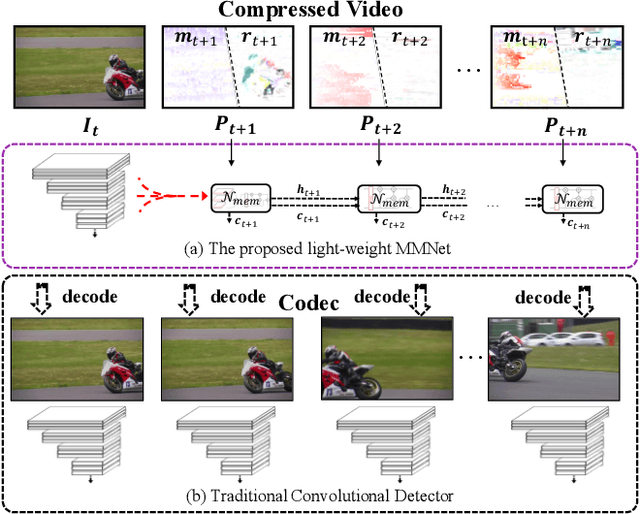
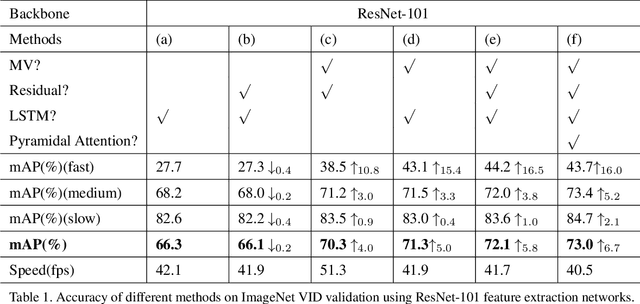
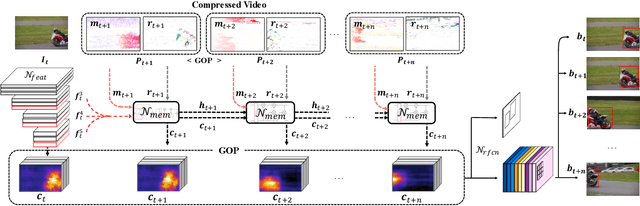

Object detection in videos has drawn increasing attention recently since it is more important in real scenarios. Most of the deep learning methods for video analysis use convolutional neural networks designed for image-wise parsing in a video stream. But they usually ignore the fact that a video is generally stored and transmitted in a compressed data format. In this paper, we propose a fast object detection model that incorporates light-weight motion-aided memory network (MMNet), which can be directly used for H.264 compressed video. MMNet has two major advantages: 1) For a group of successive pictures (GOP) in a compressed video stream, it runs the heavy computational network for I-frames, i.e. a few reference frames in videos, while a light-weight memory network is designed to generate features for prediction frames called P-frames; 2) Unlike establishing an additional network to explicitly model motion among frames, we directly take full advantage of both motion vectors and residual errors that are all encoded in a compressed video. Such signals maintain spatial variations and are freely available. To our best knowledge, the MMNet is the first work that explores a convolutional detector on a compressed video and a motion-based memory in order to achieve significant speedup. Our model is evaluated on the large-scale ImageNet VID dataset, and the results show that it is about 3x times faster than single image detector R-FCN and 10x times faster than high performance detectors like FGFA and MANet.