 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-VLA: Unleashing Long-Horizon Capability of Vision Language Action Model for Robot Manipulation
Aug 28, 2025Vision-Language-Action (VLA) models have become a cornerstone in robotic policy learning, leveraging large-scale multimodal data for robust and scalable control. However, existing VLA frameworks primarily address short-horizon tasks, and their effectiveness on long-horizon, multi-step robotic manipulation remains limited due to challenges in skill chaining and subtask dependencies. In this work, we introduce Long-VLA, the first end-to-end VLA model specifically designed for long-horizon robotic tasks. Our approach features a novel phase-aware input masking strategy that adaptively segments each subtask into moving and interaction phases, enabling the model to focus on phase-relevant sensory cues and enhancing subtask compatibility. This unified strategy preserves the scalability and data efficiency of VLA training, and our architecture-agnostic module can be seamlessly integrated into existing VLA models. We further propose the L-CALVIN benchmark to systematically evaluate long-horizon manipulation. Extensive experiments on both simulated and real-world tasks demonstrate that Long-VLA significantly outperforms prior state-of-the-art methods, establishing a new baseline for long-horizon robotic control.
Humanoid-VLA: Towards Universal Humanoid Control with Visual Integration
Feb 21, 2025This paper addresses the limitations of current humanoid robot control frameworks, which primarily rely on reactive mechanisms and lack autonomous interaction capabilities due to data scarcity. We propose Humanoid-VLA, a novel framework that integrates language understanding, egocentric scene perception, and motion control, enabling universal humanoid control. Humanoid-VLA begins with language-motion pre-alignment using non-egocentric human motion datasets paired with textual descriptions, allowing the model to learn universal motion patterns and action semantics. We then incorporate egocentric visual context through a parameter efficient video-conditioned fine-tuning, enabling context-aware motion generation. Furthermore, we introduce a self-supervised data augmentation strategy that automatically generates pseudoannotations directly derived from motion data. This process converts raw motion sequences into informative question-answer pairs, facilitating the effective use of large-scale unlabeled video data. Built upon whole-body control architectures, extensive experiments show that Humanoid-VLA achieves object interaction and environment exploration tasks with enhanced contextual awareness, demonstrating a more human-like capacity for adaptive and intelligent engagement.
QUART-Online: Latency-Free Large Multimodal Language Model for Quadruped Robot Learning
Dec 23, 2024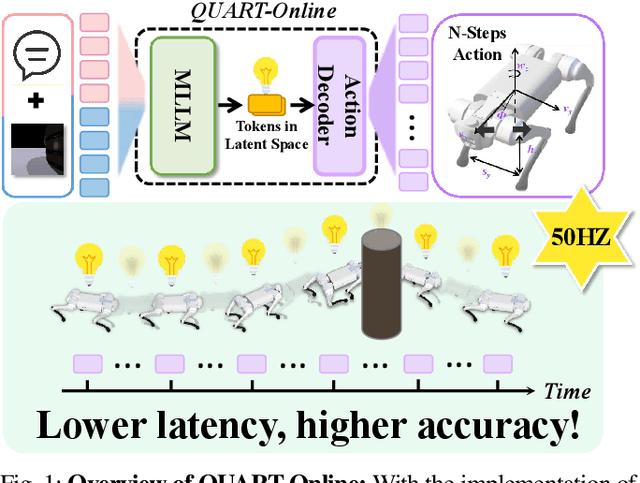
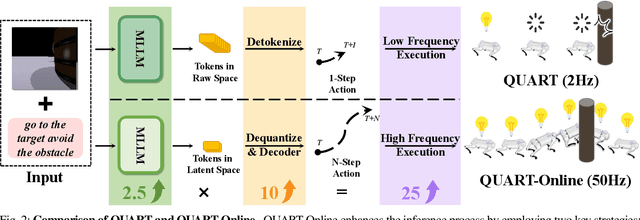
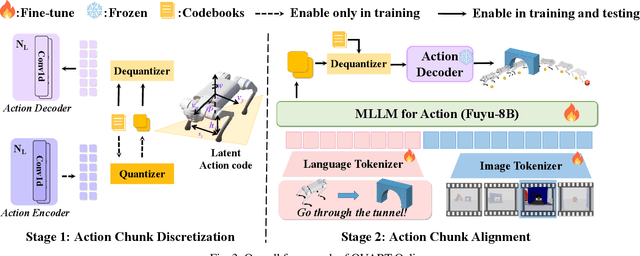
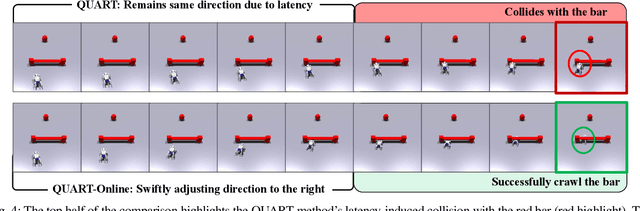
This paper addresses the inherent inference latency challenges associated with deploying multimodal large language models (MLLM) in quadruped vision-language-action (QUAR-VLA) tasks. Our investigation reveals that conventional parameter reduction techniques ultimately impair the performance of the language foundation model during the action instruction tuning phase, making them unsuitable for this purpose. We introduce a novel latency-free quadruped MLLM model, dubbed QUART-Online, designed to enhance inference efficiency without degrading the performance of the language foundation model. By incorporating Action Chunk Discretization (ACD), we compress the original action representation space, mapping continuous action values onto a smaller set of discrete representative vectors while preserving critical information. Subsequently, we fine-tune the MLLM to integrate vision, language, and compressed actions into a unified semantic space. Experimental results demonstrate that QUART-Online operates in tandem with the existing MLLM system, achieving real-time inference in sync with the underlying controller frequency, significantly boosting the success rate across various tasks by 65%. Our project page is https://quart-online.github.io.