 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy Augmented Reinforcement Learning
Paper and Code
Aug 19, 2022

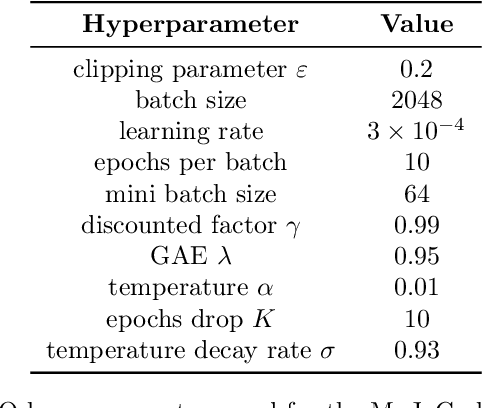

Deep reinforcement learning has gained a lot of success with the presence of trust region policy optimization (TRPO) and proximal policy optimization (PPO), for their scalability and efficiency. However, the pessimism of both algorithms, among which it either is constrained in a trust region or strictly excludes all suspicious gradients, has been proven to suppress the exploration and harm the performance of the agent. To address those issues, we propose a shifted Markov decision process (MDP), or rather, with entropy augmentation, to encourage the exploration and reinforce the ability of escaping from suboptimums. Our method is extensible and adapts to either reward shaping or bootstrapping. With convergence analysis given, we find it is crucial to control the temperature coefficient. However, if appropriately tuning it, we can achieve remarkable performance, even on other algorithms, since it is simple yet effective. Our experiments test augmented TRPO and PPO on MuJoCo benchmark tasks, of an indication that the agent is heartened towards higher reward regions, and enjoys a balance between exploration and exploitation. We verify the exploration bonus of our method on two grid world environments.