 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDarwinian Memory: A Training-Free Self-Regulating Memory System for GUI Agent Evolution
Jan 30, 2026Multimodal Large Language Model (MLLM) agents facilitate Graphical User Interface (GUI) automation but struggle with long-horizon, cross-application tasks due to limited context windows. While memory systems provide a viable solution, existing paradigms struggle to adapt to dynamic GUI environments, suffering from a granularity mismatch between high-level intent and low-level execution, and context pollution where the static accumulation of outdated experiences drives agents into hallucination. To address these bottlenecks, we propose the Darwinian Memory System (DMS), a self-evolving architecture that constructs memory as a dynamic ecosystem governed by the law of survival of the fittest. DMS decomposes complex trajectories into independent, reusable units for compositional flexibility, and implements Utility-driven Natural Selection to track survival value, actively pruning suboptimal paths and inhibiting high-risk plans. This evolutionary pressure compels the agent to derive superior strategies. Extensive experiments on real-world multi-app benchmarks validate that DMS boosts general-purpose MLLMs without training costs or architectural overhead, achieving average gains of 18.0% in success rate and 33.9% in execution stability, while reducing task latency, establishing it as an effective self-evolving memory system for GUI tasks.
Self-Supervised Information Bottleneck for Deep Multi-View Subspace Clustering
Apr 29, 2022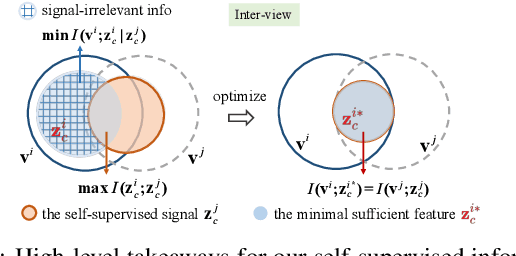
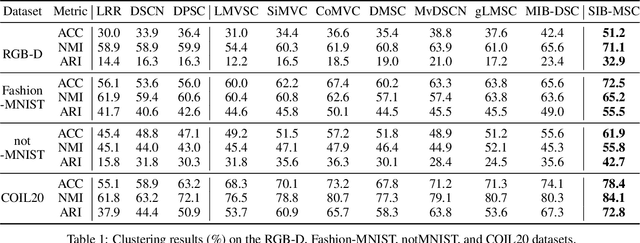
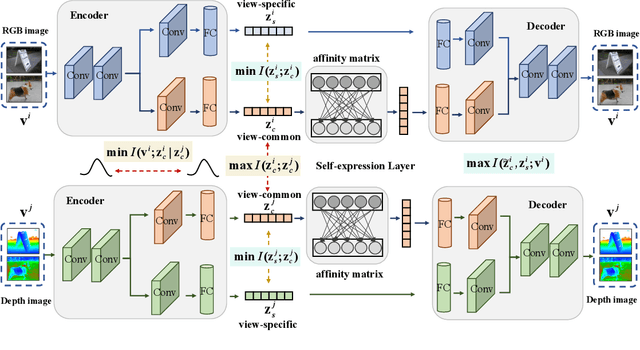
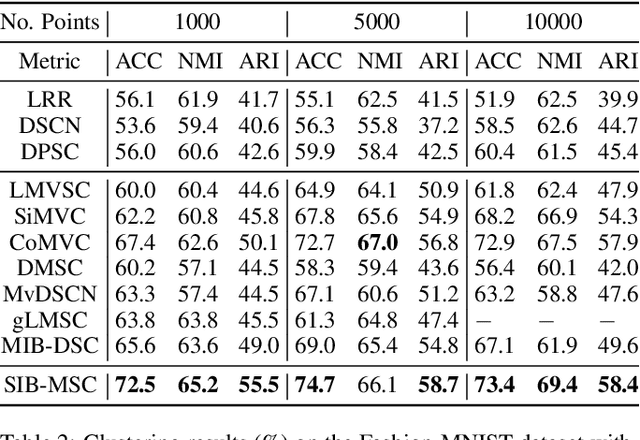
In this paper, we explore the problem of deep multi-view subspace clustering framework from an information-theoretic point of view. We extend the traditional information bottleneck principle to learn common information among different views in a self-supervised manner, and accordingly establish a new framework called Self-supervised Information Bottleneck based Multi-view Subspace Clustering (SIB-MSC). Inheriting the advantages from information bottleneck, SIB-MSC can learn a latent space for each view to capture common information among the latent representations of different views by removing superfluous information from the view itself while retaining sufficient information for the latent representations of other views. Actually, the latent representation of each view provides a kind of self-supervised signal for training the latent representations of other views. Moreover, SIB-MSC attempts to learn the other latent space for each view to capture the view-specific information by introducing mutual information based regularization terms, so as to further improve the performance of multi-view subspace clustering. To the best of our knowledge, this is the first work to explore information bottleneck for multi-view subspace clustering. Extensive experiments on real-world multi-view data demonstrate that our method achieves superior performance over the related state-of-the-art methods.
Learning Deep Representation with Energy-Based Self-Expressiveness for Subspace Clustering
Oct 28, 2021
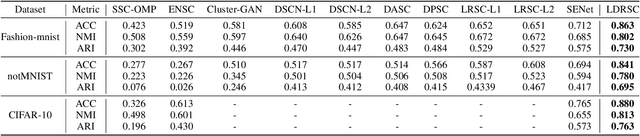
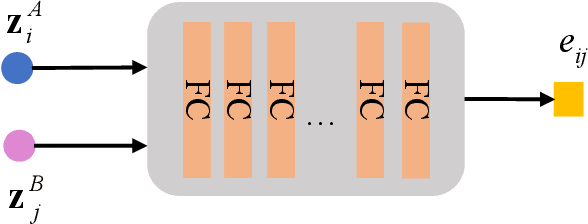
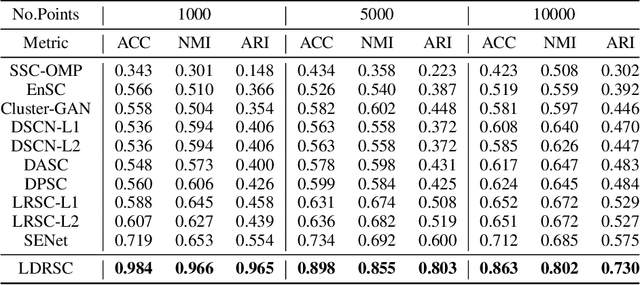
Deep subspace clustering has attracted increasing attention in recent years. Almost all the existing works are required to load the whole training data into one batch for learning the self-expressive coefficients in the framework of deep learning. Although these methods achieve promising results, such a learning fashion severely prevents from the usage of deeper neural network architectures (e.g., ResNet), leading to the limited representation abilities of the models. In this paper, we propose a new deep subspace clustering framework, motivated by the energy-based models. In contrast to previous approaches taking the weights of a fully connected layer as the self-expressive coefficients, we propose to learn an energy-based network to obtain the self-expressive coefficients by mini-batch training. By this means, it is no longer necessary to load all data into one batch for learning, and it thus becomes a reality that we can utilize deeper neural network models for subspace clustering. Considering the powerful representation ability of the recently popular self-supervised learning, we attempt to leverage self-supervised representation learning to learn the dictionary. Finally, we propose a joint framework to learn both the self-expressive coefficients and dictionary simultaneously, and train the model in an end-to-end manner. The experiments are performed on three publicly available datasets, and extensive experimental results demonstrate our method can significantly outperform the other related approaches. For instance, on the three datasets, our method can averagely achieve $13.8\%$, $15.4\%$, $20.8\%$ improvements in terms of Accuracy, NMI, and ARI over SENet which is proposed very recently and obtains the second best results in the experiments.
Covariance-Insured Screening
May 17, 2018
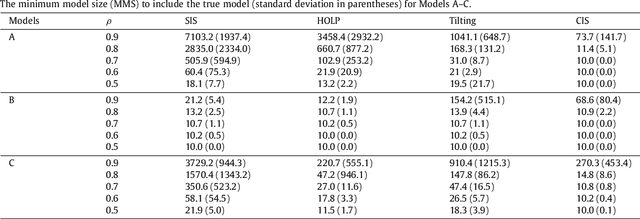
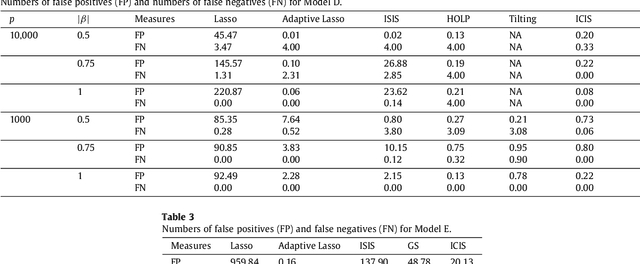
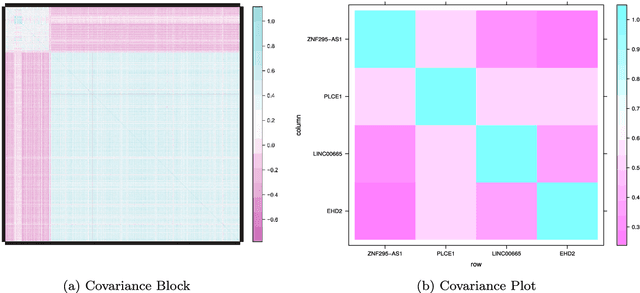
Modern bio-technologies have produced a vast amount of high-throughput data with the number of predictors far greater than the sample size. In order to identify more novel biomarkers and understand biological mechanisms, it is vital to detect signals weakly associated with outcomes among ultrahigh-dimensional predictors. However, existing screening methods, which typically ignore correlation information, are likely to miss these weak signals. By incorporating the inter-feature dependence, we propose a covariance-insured screening methodology to identify predictors that are jointly informative but only marginally weakly associated with outcomes. The validity of the method is examined via extensive simulations and real data studies for selecting potential genetic factors related to the onset of cancer.
Classification with Ultrahigh-Dimensional Features
Nov 04, 2016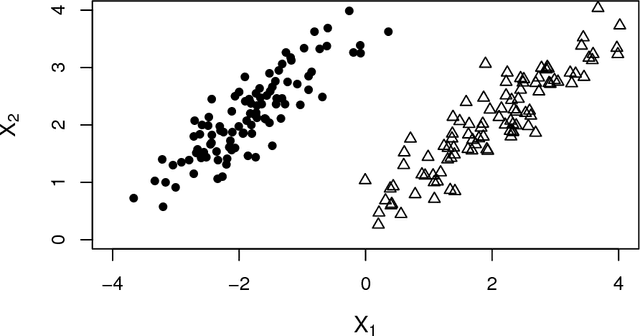

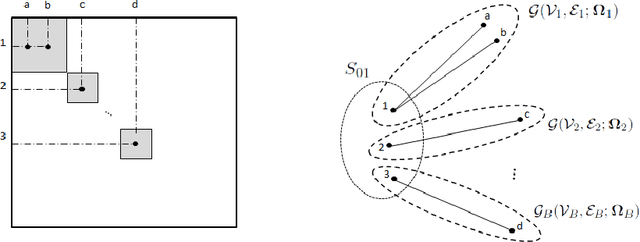

Although much progress has been made in classification with high-dimensional features \citep{Fan_Fan:2008, JGuo:2010, CaiSun:2014, PRXu:2014}, classification with ultrahigh-dimensional features, wherein the features much outnumber the sample size, defies most existing work. This paper introduces a novel and computationally feasible multivariate screening and classification method for ultrahigh-dimensional data. Leveraging inter-feature correlations, the proposed method enables detection of marginally weak and sparse signals and recovery of the true informative feature set, and achieves asymptotic optimal misclassification rates. We also show that the proposed procedure provides more powerful discovery boundaries compared to those in \citet{CaiSun:2014} and \citet{JJin:2009}. The performance of the proposed procedure is evaluated using simulation studies and demonstrated via classification of patients with different post-transplantation renal functional types.