 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCP: Accelerating Discovery with a Global Web of Autonomous Scientific Agents
Dec 30, 2025We introduce SCP: the Science Context Protocol, an open-source standard designed to accelerate discovery by enabling a global network of autonomous scientific agents. SCP is built on two foundational pillars: (1) Unified Resource Integration: At its core, SCP provides a universal specification for describing and invoking scientific resources, spanning software tools, models, datasets, and physical instruments. This protocol-level standardization enables AI agents and applications to discover, call, and compose capabilities seamlessly across disparate platforms and institutional boundaries. (2) Orchestrated Experiment Lifecycle Management: SCP complements the protocol with a secure service architecture, which comprises a centralized SCP Hub and federated SCP Servers. This architecture manages the complete experiment lifecycle (registration, planning, execution, monitoring, and archival), enforces fine-grained authentication and authorization, and orchestrates traceable, end-to-end workflows that bridge computational and physical laboratories. Based on SCP, we have constructed a scientific discovery platform that offers researchers and agents a large-scale ecosystem of more than 1,600 tool resources. Across diverse use cases, SCP facilitates secure, large-scale collaboration between heterogeneous AI systems and human researchers while significantly reducing integration overhead and enhancing reproducibility. By standardizing scientific context and tool orchestration at the protocol level, SCP establishes essential infrastructure for scalable, multi-institution, agent-driven science.
ViLaCD-R1: A Vision-Language Framework for Semantic Change Detection in Remote Sensing
Dec 29, 2025Remote sensing change detection (RSCD), a complex multi-image inference task, traditionally uses pixel-based operators or encoder-decoder networks that inadequately capture high-level semantics and are vulnerable to non-semantic perturbations. Although recent multimodal and vision-language model (VLM)-based approaches enhance semantic understanding of change regions by incorporating textual descriptions, they still suffer from challenges such as inaccurate spatial localization, imprecise pixel-level boundary delineation, and limited interpretability. To address these issues, we propose ViLaCD-R1, a two-stage framework comprising a Multi-Image Reasoner (MIR) and a Mask-Guided Decoder (MGD). Specifically, the VLM is trained through supervised fine-tuning (SFT) and reinforcement learning (RL) on block-level dual-temporal inference tasks, taking dual-temporal image patches as input and outputting a coarse change mask. Then, the decoder integrates dual-temporal image features with this coarse mask to predict a precise binary change map. Comprehensive evaluations on multiple RSCD benchmarks demonstrate that ViLaCD-R1 substantially improves true semantic change recognition and localization, robustly suppresses non-semantic variations, and achieves state-of-the-art accuracy in complex real-world scenarios.
NovelSeek: When Agent Becomes the Scientist -- Building Closed-Loop System from Hypothesis to Verification
May 22, 2025
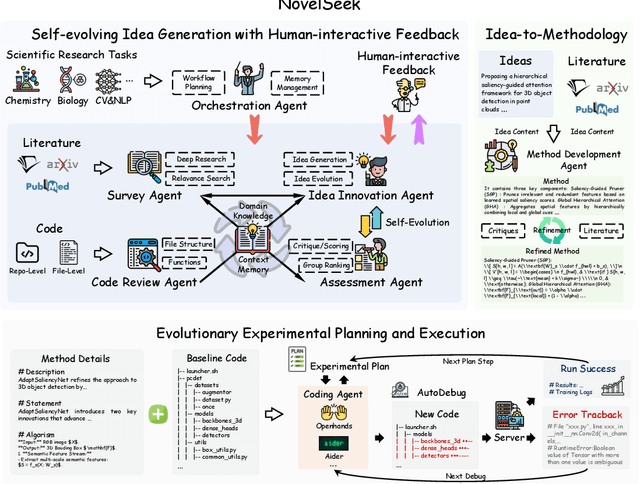

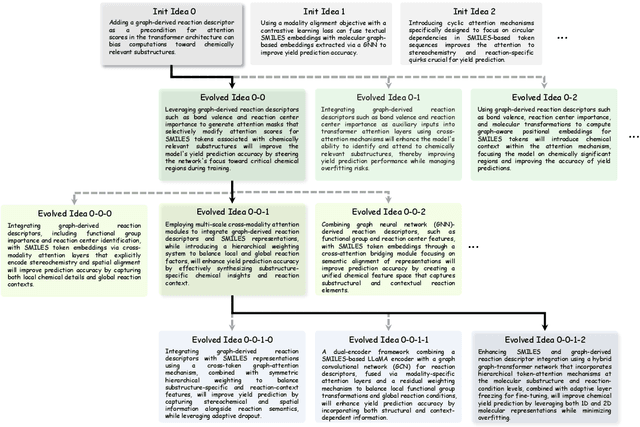
Artificial Intelligence (AI) is accelerating the transformation of scientific research paradigms, not only enhancing research efficiency but also driving innovation. We introduce NovelSeek, a unified closed-loop multi-agent framework to conduct Autonomous Scientific Research (ASR) across various scientific research fields, enabling researchers to tackle complicated problems in these fields with unprecedented speed and precision. NovelSeek highlights three key advantages: 1) Scalability: NovelSeek has demonstrated its versatility across 12 scientific research tasks, capable of generating innovative ideas to enhance the performance of baseline code. 2) Interactivity: NovelSeek provides an interface for human expert feedback and multi-agent interaction in automated end-to-end processes, allowing for the seamless integration of domain expert knowledge. 3) Efficiency: NovelSeek has achieved promising performance gains in several scientific fields with significantly less time cost compared to human efforts. For instance, in reaction yield prediction, it increased from 27.6% to 35.4% in just 12 hours; in enhancer activity prediction, accuracy rose from 0.52 to 0.79 with only 4 hours of processing; and in 2D semantic segmentation, precision advanced from 78.8% to 81.0% in a mere 30 hours.
TrustGeoGen: Scalable and Formal-Verified Data Engine for Trustworthy Multi-modal Geometric Problem Solving
Apr 22, 2025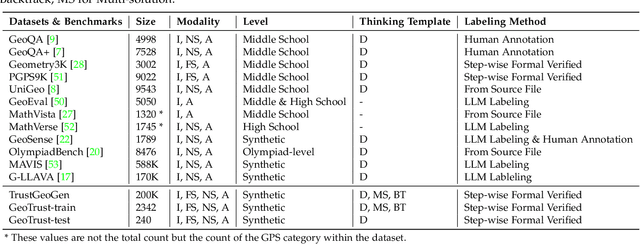
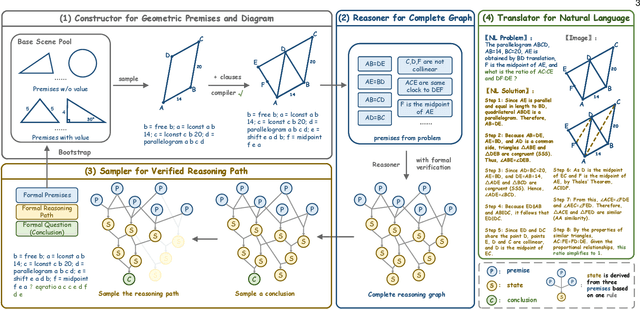
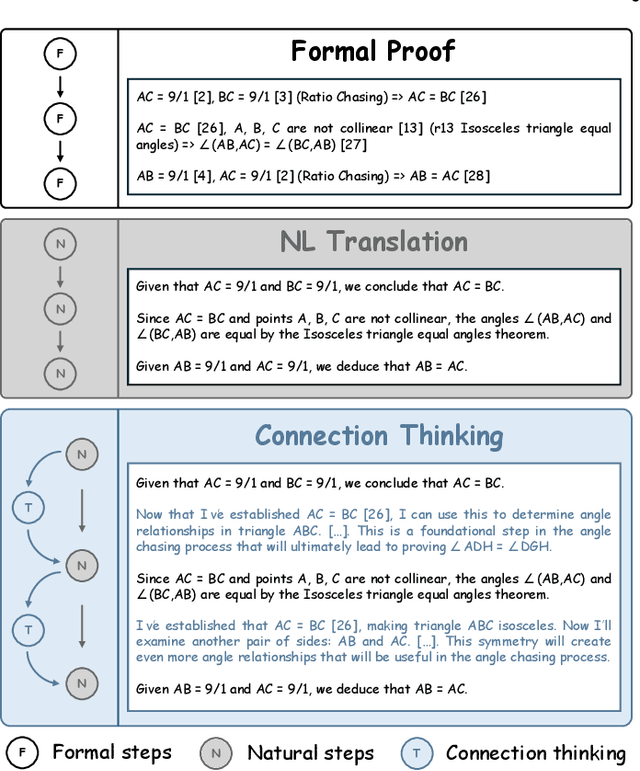
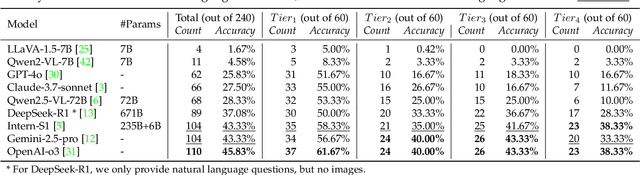
Mathematical geometric problem solving (GPS) often requires effective integration of multimodal information and verifiable logical coherence. Despite the fast development of large language models in general problem solving, it remains unresolved regarding with both methodology and benchmarks, especially given the fact that exiting synthetic GPS benchmarks are often not self-verified and contain noise and self-contradicted information due to the illusion of LLMs. In this paper, we propose a scalable data engine called TrustGeoGen for problem generation, with formal verification to provide a principled benchmark, which we believe lays the foundation for the further development of methods for GPS. The engine synthesizes geometric data through four key innovations: 1) multimodal-aligned generation of diagrams, textual descriptions, and stepwise solutions; 2) formal verification ensuring rule-compliant reasoning paths; 3) a bootstrapping mechanism enabling complexity escalation via recursive state generation and 4) our devised GeoExplore series algorithms simultaneously produce multi-solution variants and self-reflective backtracking traces. By formal logical verification, TrustGeoGen produces GeoTrust-200K dataset with guaranteed modality integrity, along with GeoTrust-test testset. Experiments reveal the state-of-the-art models achieve only 49.17\% accuracy on GeoTrust-test, demonstrating its evaluation stringency. Crucially, models trained on GeoTrust achieve OOD generalization on GeoQA, significantly reducing logical inconsistencies relative to pseudo-label annotated by OpenAI-o1. Our code is available at https://github.com/Alpha-Innovator/TrustGeoGen
SurveyForge: On the Outline Heuristics, Memory-Driven Generation, and Multi-dimensional Evaluation for Automated Survey Writing
Mar 06, 2025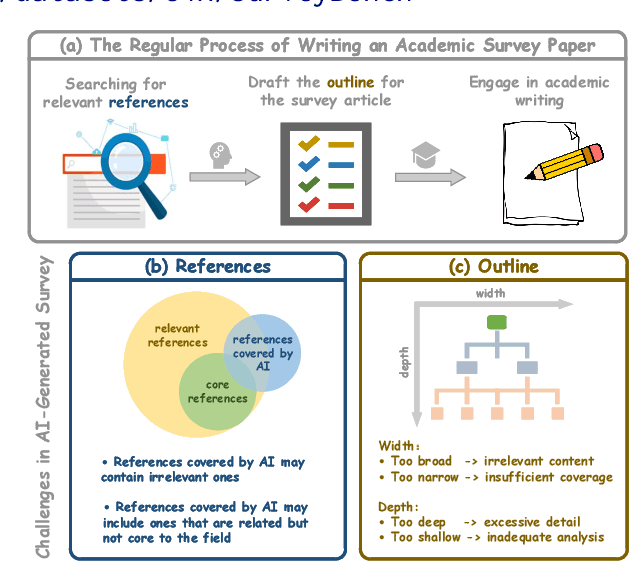



Survey paper plays a crucial role in scientific research, especially given the rapid growth of research publications. Recently, researchers have begun using LLMs to automate survey generation for better efficiency. However, the quality gap between LLM-generated surveys and those written by human remains significant, particularly in terms of outline quality and citation accuracy. To close these gaps, we introduce SurveyForge, which first generates the outline by analyzing the logical structure of human-written outlines and referring to the retrieved domain-related articles. Subsequently, leveraging high-quality papers retrieved from memory by our scholar navigation agent, SurveyForge can automatically generate and refine the content of the generated article. Moreover, to achieve a comprehensive evaluation, we construct SurveyBench, which includes 100 human-written survey papers for win-rate comparison and assesses AI-generated survey papers across three dimensions: reference, outline, and content quality. Experiments demonstrate that SurveyForge can outperform previous works such as AutoSurvey.
DocGenome: An Open Large-scale Scientific Document Benchmark for Training and Testing Multi-modal Large Language Models
Jun 17, 2024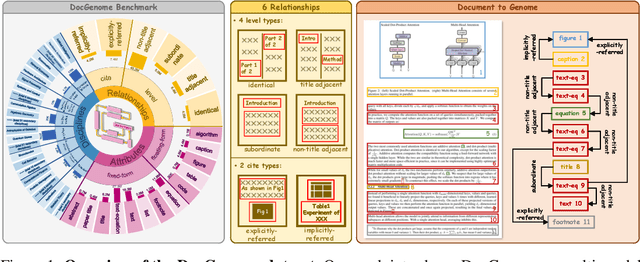
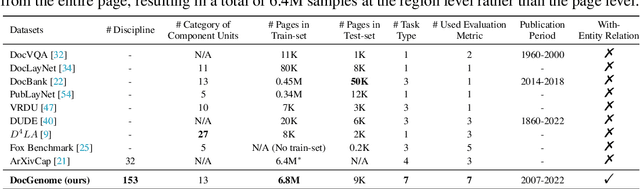
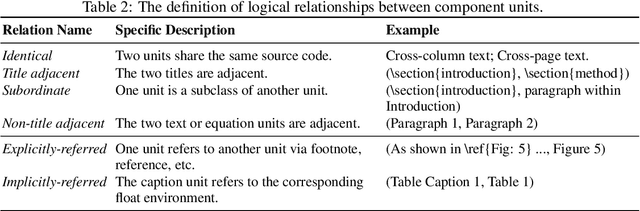
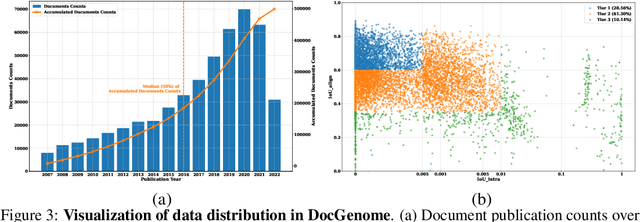
Scientific documents record research findings and valuable human knowledge, comprising a vast corpus of high-quality data. Leveraging multi-modality data extracted from these documents and assessing large models' abilities to handle scientific document-oriented tasks is therefore meaningful. Despite promising advancements, large models still perform poorly on multi-page scientific document extraction and understanding tasks, and their capacity to process within-document data formats such as charts and equations remains under-explored. To address these issues, we present DocGenome, a structured document benchmark constructed by annotating 500K scientific documents from 153 disciplines in the arXiv open-access community, using our custom auto-labeling pipeline. DocGenome features four key characteristics: 1) Completeness: It is the first dataset to structure data from all modalities including 13 layout attributes along with their LaTeX source codes. 2) Logicality: It provides 6 logical relationships between different entities within each scientific document. 3) Diversity: It covers various document-oriented tasks, including document classification, visual grounding, document layout detection, document transformation, open-ended single-page QA and multi-page QA. 4) Correctness: It undergoes rigorous quality control checks conducted by a specialized team. We conduct extensive experiments to demonstrate the advantages of DocGenome and objectively evaluate the performance of large models on our benchmark.