 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeOrbit4D: Training-Free Arbitrary Camera Redirection for Monocular Videos via Geometry-Complete 4D Reconstruction
Jan 26, 2026Camera redirection aims to replay a dynamic scene from a single monocular video under a user-specified camera trajectory. However, large-angle redirection is inherently ill-posed: a monocular video captures only a narrow spatio-temporal view of a dynamic 3D scene, providing highly partial observations of the underlying 4D world. The key challenge is therefore to recover a complete and coherent representation from this limited input, with consistent geometry and motion. While recent diffusion-based methods achieve impressive results, they often break down under large-angle viewpoint changes far from the original trajectory, where missing visual grounding leads to severe geometric ambiguity and temporal inconsistency. To address this, we present FreeOrbit4D, an effective training-free framework that tackles this geometric ambiguity by recovering a geometry-complete 4D proxy as structural grounding for video generation. We obtain this proxy by decoupling foreground and background reconstructions: we unproject the monocular video into a static background and geometry-incomplete foreground point clouds in a unified global space, then leverage an object-centric multi-view diffusion model to synthesize multi-view images and reconstruct geometry-complete foreground point clouds in canonical object space. By aligning the canonical foreground point cloud to the global scene space via dense pixel-synchronized 3D--3D correspondences and projecting the geometry-complete 4D proxy onto target camera viewpoints, we provide geometric scaffolds that guide a conditional video diffusion model. Extensive experiments show that FreeOrbit4D produces more faithful redirected videos under challenging large-angle trajectories, and our geometry-complete 4D proxy further opens a potential avenue for practical applications such as edit propagation and 4D data generation. Project page and code will be released soon.
Semantic Flow: Learning Semantic Field of Dynamic Scenes from Monocular Videos
Apr 08, 2024In this work, we pioneer Semantic Flow, a neural semantic representation of dynamic scenes from monocular videos. In contrast to previous NeRF methods that reconstruct dynamic scenes from the colors and volume densities of individual points, Semantic Flow learns semantics from continuous flows that contain rich 3D motion information. As there is 2D-to-3D ambiguity problem in the viewing direction when extracting 3D flow features from 2D video frames, we consider the volume densities as opacity priors that describe the contributions of flow features to the semantics on the frames. More specifically, we first learn a flow network to predict flows in the dynamic scene, and propose a flow feature aggregation module to extract flow features from video frames. Then, we propose a flow attention module to extract motion information from flow features, which is followed by a semantic network to output semantic logits of flows. We integrate the logits with volume densities in the viewing direction to supervise the flow features with semantic labels on video frames. Experimental results show that our model is able to learn from multiple dynamic scenes and supports a series of new tasks such as instance-level scene editing, semantic completions, dynamic scene tracking and semantic adaption on novel scenes. Codes are available at https://github.com/tianfr/Semantic-Flow/.
Learning a Category-level Object Pose Estimator without Pose Annotations
Apr 08, 2024



3D object pose estimation is a challenging task. Previous works always require thousands of object images with annotated poses for learning the 3D pose correspondence, which is laborious and time-consuming for labeling. In this paper, we propose to learn a category-level 3D object pose estimator without pose annotations. Instead of using manually annotated images, we leverage diffusion models (e.g., Zero-1-to-3) to generate a set of images under controlled pose differences and propose to learn our object pose estimator with those images. Directly using the original diffusion model leads to images with noisy poses and artifacts. To tackle this issue, firstly, we exploit an image encoder, which is learned from a specially designed contrastive pose learning, to filter the unreasonable details and extract image feature maps. Additionally, we propose a novel learning strategy that allows the model to learn object poses from those generated image sets without knowing the alignment of their canonical poses. Experimental results show that our method has the capability of category-level object pose estimation from a single shot setting (as pose definition), while significantly outperforming other state-of-the-art methods on the few-shot category-level object pose estimation benchmarks.
Multi-Modal Deep Learning for Credit Rating Prediction Using Text and Numerical Data Streams
Apr 21, 2023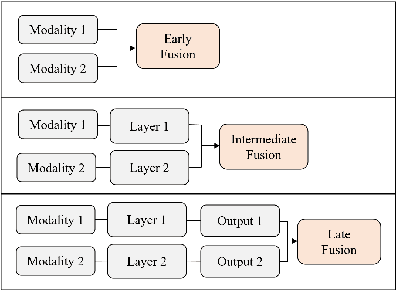



Knowing which factors are significant in credit rating assignment leads to better decision-making. However, the focus of the literature thus far has been mostly on structured data, and fewer studies have addressed unstructured or multi-modal datasets. In this paper, we present an analysis of the most effective architectures for the fusion of deep learning models for the prediction of company credit rating classes, by using structured and unstructured datasets of different types. In these models, we tested different combinations of fusion strategies with different deep learning models, including CNN, LSTM, GRU, and BERT. We studied data fusion strategies in terms of level (including early and intermediate fusion) and techniques (including concatenation and cross-attention). Our results show that a CNN-based multi-modal model with two fusion strategies outperformed other multi-modal techniques. In addition, by comparing simple architectures with more complex ones, we found that more sophisticated deep learning models do not necessarily produce the highest performance; however, if attention-based models are producing the best results, cross-attention is necessary as a fusion strategy. Finally, our comparison of rating agencies on short-, medium-, and long-term performance shows that Moody's credit ratings outperform those of other agencies like Standard & Poor's and Fitch Ratings.
MonoNeRF: Learning a Generalizable Dynamic Radiance Field from Monocular Videos
Dec 26, 2022In this paper, we target at the problem of learning a generalizable dynamic radiance field from monocular videos. Different from most existing NeRF methods that are based on multiple views, monocular videos only contain one view at each timestamp, thereby suffering from ambiguity along the view direction in estimating point features and scene flows. Previous studies such as DynNeRF disambiguate point features by positional encoding, which is not transferable and severely limits the generalization ability. As a result, these methods have to train one independent model for each scene and suffer from heavy computational costs when applying to increasing monocular videos in real-world applications. To address this, We propose MonoNeRF to simultaneously learn point features and scene flows with point trajectory and feature correspondence constraints across frames. More specifically, we learn an implicit velocity field to estimate point trajectory from temporal features with Neural ODE, which is followed by a flow-based feature aggregation module to obtain spatial features along the point trajectory. We jointly optimize temporal and spatial features by training the network in an end-to-end manner. Experiments show that our MonoNeRF is able to learn from multiple scenes and support new applications such as scene editing, unseen frame synthesis, and fast novel scene adaptation.