 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Deep Learning for Credit Rating Prediction Using Text and Numerical Data Streams
Paper and Code
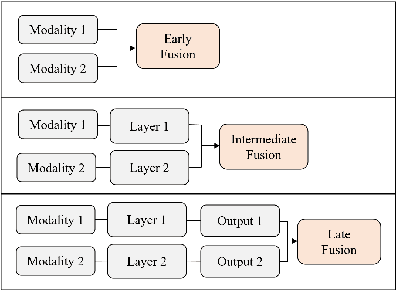



Knowing which factors are significant in credit rating assignment leads to better decision-making. However, the focus of the literature thus far has been mostly on structured data, and fewer studies have addressed unstructured or multi-modal datasets. In this paper, we present an analysis of the most effective architectures for the fusion of deep learning models for the prediction of company credit rating classes, by using structured and unstructured datasets of different types. In these models, we tested different combinations of fusion strategies with different deep learning models, including CNN, LSTM, GRU, and BERT. We studied data fusion strategies in terms of level (including early and intermediate fusion) and techniques (including concatenation and cross-attention). Our results show that a CNN-based multi-modal model with two fusion strategies outperformed other multi-modal techniques. In addition, by comparing simple architectures with more complex ones, we found that more sophisticated deep learning models do not necessarily produce the highest performance; however, if attention-based models are producing the best results, cross-attention is necessary as a fusion strategy. Finally, our comparison of rating agencies on short-, medium-, and long-term performance shows that Moody's credit ratings outperform those of other agencies like Standard & Poor's and Fitch Ratings.