 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABot-N0: Technical Report on the VLA Foundation Model for Versatile Embodied Navigation
Feb 12, 2026Embodied navigation has long been fragmented by task-specific architectures. We introduce ABot-N0, a unified Vision-Language-Action (VLA) foundation model that achieves a ``Grand Unification'' across 5 core tasks: Point-Goal, Object-Goal, Instruction-Following, POI-Goal, and Person-Following. ABot-N0 utilizes a hierarchical ``Brain-Action'' architecture, pairing an LLM-based Cognitive Brain for semantic reasoning with a Flow Matching-based Action Expert for precise, continuous trajectory generation. To support large-scale learning, we developed the ABot-N0 Data Engine, curating 16.9M expert trajectories and 5.0M reasoning samples across 7,802 high-fidelity 3D scenes (10.7 $\text{km}^2$). ABot-N0 achieves new SOTA performance across 7 benchmarks, significantly outperforming specialized models. Furthermore, our Agentic Navigation System integrates a planner with hierarchical topological memory, enabling robust, long-horizon missions in dynamic real-world environments.
Bridging the Indoor-Outdoor Gap: Vision-Centric Instruction-Guided Embodied Navigation for the Last Meters
Feb 06, 2026Embodied navigation holds significant promise for real-world applications such as last-mile delivery. However, most existing approaches are confined to either indoor or outdoor environments and rely heavily on strong assumptions, such as access to precise coordinate systems. While current outdoor methods can guide agents to the vicinity of a target using coarse-grained localization, they fail to enable fine-grained entry through specific building entrances, critically limiting their utility in practical deployment scenarios that require seamless outdoor-to-indoor transitions. To bridge this gap, we introduce a novel task: out-to-in prior-free instruction-driven embodied navigation. This formulation explicitly eliminates reliance on accurate external priors, requiring agents to navigate solely based on egocentric visual observations guided by instructions. To tackle this task, we propose a vision-centric embodied navigation framework that leverages image-based prompts to drive decision-making. Additionally, we present the first open-source dataset for this task, featuring a pipeline that integrates trajectory-conditioned video synthesis into the data generation process. Through extensive experiments, we demonstrate that our proposed method consistently outperforms state-of-the-art baselines across key metrics including success rate and path efficiency.
InstaDrive: Instance-Aware Driving World Models for Realistic and Consistent Video Generation
Feb 03, 2026Autonomous driving relies on robust models trained on high-quality, large-scale multi-view driving videos. While world models offer a cost-effective solution for generating realistic driving videos, they struggle to maintain instance-level temporal consistency and spatial geometric fidelity. To address these challenges, we propose InstaDrive, a novel framework that enhances driving video realism through two key advancements: (1) Instance Flow Guider, which extracts and propagates instance features across frames to enforce temporal consistency, preserving instance identity over time. (2) Spatial Geometric Aligner, which improves spatial reasoning, ensures precise instance positioning, and explicitly models occlusion hierarchies. By incorporating these instance-aware mechanisms, InstaDrive achieves state-of-the-art video generation quality and enhances downstream autonomous driving tasks on the nuScenes dataset. Additionally, we utilize CARLA's autopilot to procedurally and stochastically simulate rare but safety-critical driving scenarios across diverse maps and regions, enabling rigorous safety evaluation for autonomous systems. Our project page is https://shanpoyang654.github.io/InstaDrive/page.html.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Physical Informed Driving World Model
Dec 13, 2024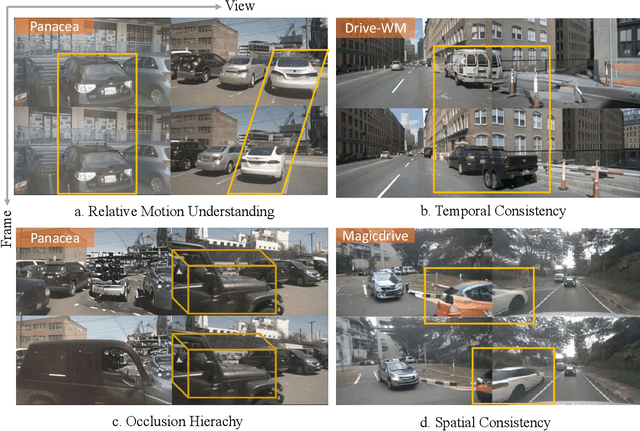
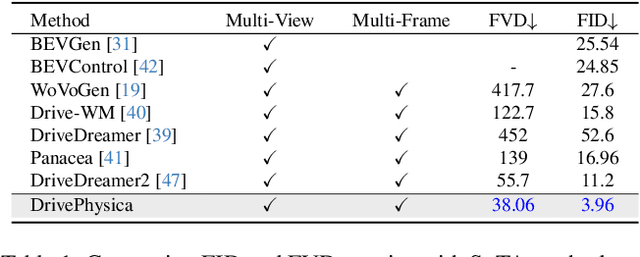
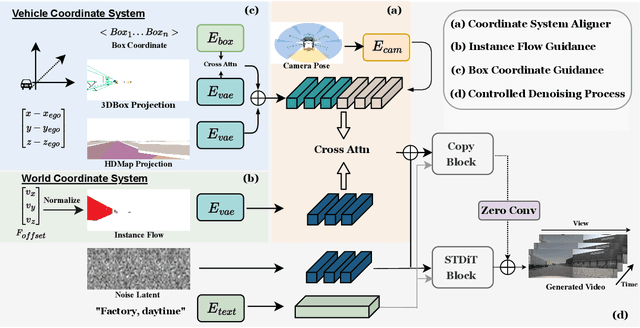
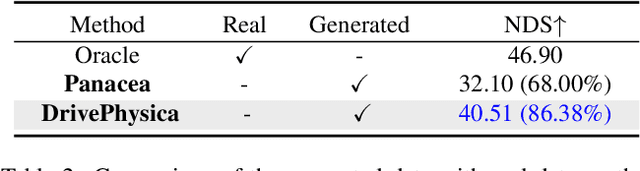
Autonomous driving requires robust perception models trained on high-quality, large-scale multi-view driving videos for tasks like 3D object detection, segmentation and trajectory prediction. While world models provide a cost-effective solution for generating realistic driving videos, challenges remain in ensuring these videos adhere to fundamental physical principles, such as relative and absolute motion, spatial relationship like occlusion and spatial consistency, and temporal consistency. To address these, we propose DrivePhysica, an innovative model designed to generate realistic multi-view driving videos that accurately adhere to essential physical principles through three key advancements: (1) a Coordinate System Aligner module that integrates relative and absolute motion features to enhance motion interpretation, (2) an Instance Flow Guidance module that ensures precise temporal consistency via efficient 3D flow extraction, and (3) a Box Coordinate Guidance module that improves spatial relationship understanding and accurately resolves occlusion hierarchies. Grounded in physical principles, we achieve state-of-the-art performance in driving video generation quality (3.96 FID and 38.06 FVD on the Nuscenes dataset) and downstream perception tasks. Our project homepage: https://metadrivescape.github.io/papers_project/DrivePhysica/page.html
Pysical Informed Driving World Model
Dec 11, 2024Autonomous driving requires robust perception models trained on high-quality, large-scale multi-view driving videos for tasks like 3D object detection, segmentation and trajectory prediction. While world models provide a cost-effective solution for generating realistic driving videos, challenges remain in ensuring these videos adhere to fundamental physical principles, such as relative and absolute motion, spatial relationship like occlusion and spatial consistency, and temporal consistency. To address these, we propose DrivePhysica, an innovative model designed to generate realistic multi-view driving videos that accurately adhere to essential physical principles through three key advancements: (1) a Coordinate System Aligner module that integrates relative and absolute motion features to enhance motion interpretation, (2) an Instance Flow Guidance module that ensures precise temporal consistency via efficient 3D flow extraction, and (3) a Box Coordinate Guidance module that improves spatial relationship understanding and accurately resolves occlusion hierarchies. Grounded in physical principles, we achieve state-of-the-art performance in driving video generation quality (3.96 FID and 38.06 FVD on the Nuscenes dataset) and downstream perception tasks. Our project homepage: https://metadrivescape.github.io/papers_project/DrivePhysica/page.html
DriveScape: Towards High-Resolution Controllable Multi-View Driving Video Generation
Sep 11, 2024



Recent advancements in generative models have provided promising solutions for synthesizing realistic driving videos, which are crucial for training autonomous driving perception models. However, existing approaches often struggle with multi-view video generation due to the challenges of integrating 3D information while maintaining spatial-temporal consistency and effectively learning from a unified model. In this paper, we propose an end-to-end framework named DriveScape for multi-view, 3D condition-guided video generation. DriveScape not only streamlines the process by integrating camera data to ensure comprehensive spatial-temporal coverage, but also introduces a Bi-Directional Modulated Transformer module to effectively align 3D road structural information. As a result, our approach enables precise control over video generation, significantly enhancing realism and providing a robust solution for generating multi-view driving videos. Our framework achieves state-of-the-art results on the nuScenes dataset, demonstrating impressive generative quality metrics with an FID score of 8.34 and an FVD score of 76.39, as well as superior performance across various perception tasks. This paves the way for more accurate environmental simulations in autonomous driving. Our project homepage: https://metadrivescape.github.io/papers_project/drivescapev1/index.html
SGC-VQGAN: Towards Complex Scene Representation via Semantic Guided Clustering Codebook
Sep 09, 2024Vector quantization (VQ) is a method for deterministically learning features through discrete codebook representations. Recent works have utilized visual tokenizers to discretize visual regions for self-supervised representation learning. However, a notable limitation of these tokenizers is lack of semantics, as they are derived solely from the pretext task of reconstructing raw image pixels in an auto-encoder paradigm. Additionally, issues like imbalanced codebook distribution and codebook collapse can adversely impact performance due to inefficient codebook utilization. To address these challenges, We introduce SGC-VQGAN through Semantic Online Clustering method to enhance token semantics through Consistent Semantic Learning. Utilizing inference results from segmentation model , our approach constructs a temporospatially consistent semantic codebook, addressing issues of codebook collapse and imbalanced token semantics. Our proposed Pyramid Feature Learning pipeline integrates multi-level features to capture both image details and semantics simultaneously. As a result, SGC-VQGAN achieves SOTA performance in both reconstruction quality and various downstream tasks. Its simplicity, requiring no additional parameter learning, enables its direct application in downstream tasks, presenting significant potential.
StreetSurf: Extending Multi-view Implicit Surface Reconstruction to Street Views
Jun 08, 2023



We present a novel multi-view implicit surface reconstruction technique, termed StreetSurf, that is readily applicable to street view images in widely-used autonomous driving datasets, such as Waymo-perception sequences, without necessarily requiring LiDAR data. As neural rendering research expands rapidly, its integration into street views has started to draw interests. Existing approaches on street views either mainly focus on novel view synthesis with little exploration of the scene geometry, or rely heavily on dense LiDAR data when investigating reconstruction. Neither of them investigates multi-view implicit surface reconstruction, especially under settings without LiDAR data. Our method extends prior object-centric neural surface reconstruction techniques to address the unique challenges posed by the unbounded street views that are captured with non-object-centric, long and narrow camera trajectories. We delimit the unbounded space into three parts, close-range, distant-view and sky, with aligned cuboid boundaries, and adapt cuboid/hyper-cuboid hash-grids along with road-surface initialization scheme for finer and disentangled representation. To further address the geometric errors arising from textureless regions and insufficient viewing angles, we adopt geometric priors that are estimated using general purpose monocular models. Coupled with our implementation of efficient and fine-grained multi-stage ray marching strategy, we achieve state of the art reconstruction quality in both geometry and appearance within only one to two hours of training time with a single RTX3090 GPU for each street view sequence. Furthermore, we demonstrate that the reconstructed implicit surfaces have rich potential for various downstream tasks, including ray tracing and LiDAR simulation.
Self-supervised Amodal Video Object Segmentation
Oct 23, 2022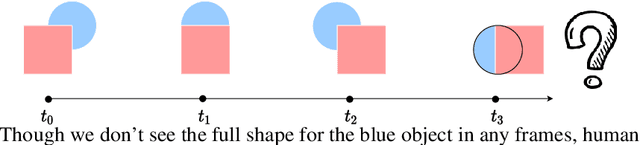
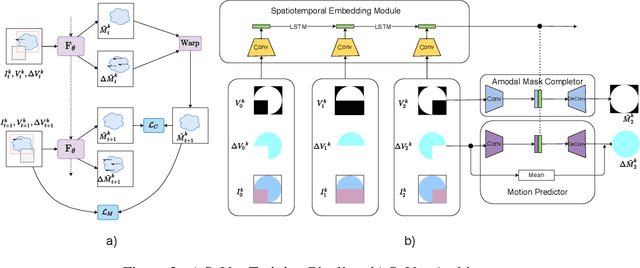
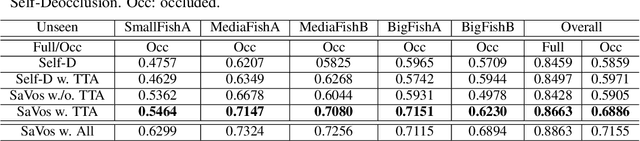

Amodal perception requires inferring the full shape of an object that is partially occluded. This task is particularly challenging on two levels: (1) it requires more information than what is contained in the instant retina or imaging sensor, (2) it is difficult to obtain enough well-annotated amodal labels for supervision. To this end, this paper develops a new framework of Self-supervised amodal Video object segmentation (SaVos). Our method efficiently leverages the visual information of video temporal sequences to infer the amodal mask of objects. The key intuition is that the occluded part of an object can be explained away if that part is visible in other frames, possibly deformed as long as the deformation can be reasonably learned. Accordingly, we derive a novel self-supervised learning paradigm that efficiently utilizes the visible object parts as the supervision to guide the training on videos. In addition to learning type prior to complete masks for known types, SaVos also learns the spatiotemporal prior, which is also useful for the amodal task and could generalize to unseen types. The proposed framework achieves the state-of-the-art performance on the synthetic amodal segmentation benchmark FISHBOWL and the real world benchmark KINS-Video-Car. Further, it lends itself well to being transferred to novel distributions using test-time adaptation, outperforming existing models even after the transfer to a new distribution.