 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRWKV:Frequency-Domain Linear Attention for Long-Term Time Series Forecasting
Dec 09, 2025Traditional Transformers face a major bottleneck in long-sequence time series forecasting due to their quadratic complexity $(\mathcal{O}(T^2))$ and their limited ability to effectively exploit frequency-domain information. Inspired by RWKV's $\mathcal{O}(T)$ linear attention and frequency-domain modeling, we propose FRWKV, a frequency-domain linear-attention framework that overcomes these limitations. Our model integrates linear attention mechanisms with frequency-domain analysis, achieving $\mathcal{O}(T)$ computational complexity in the attention path while exploiting spectral information to enhance temporal feature representations for scalable long-sequence modeling. Across eight real-world datasets, FRWKV achieves a first-place average rank. Our ablation studies confirm the critical roles of both the linear attention and frequency-encoder components. This work demonstrates the powerful synergy between linear attention and frequency analysis, establishing a new paradigm for scalable time series modeling. Code is available at this repository: https://github.com/yangqingyuan-byte/FRWKV.
FOAM: A General Frequency-Optimized Anti-Overlapping Framework for Overlapping Object Perception
Jun 16, 2025Overlapping object perception aims to decouple the randomly overlapping foreground-background features, extracting foreground features while suppressing background features, which holds significant application value in fields such as security screening and medical auxiliary diagnosis. Despite some research efforts to tackle the challenge of overlapping object perception, most solutions are confined to the spatial domain. Through frequency domain analysis, we observe that the degradation of contours and textures due to the overlapping phenomenon can be intuitively reflected in the magnitude spectrum. Based on this observation, we propose a general Frequency-Optimized Anti-Overlapping Framework (FOAM) to assist the model in extracting more texture and contour information, thereby enhancing the ability for anti-overlapping object perception. Specifically, we design the Frequency Spatial Transformer Block (FSTB), which can simultaneously extract features from both the frequency and spatial domains, helping the network capture more texture features from the foreground. In addition, we introduce the Hierarchical De-Corrupting (HDC) mechanism, which aligns adjacent features in the separately constructed base branch and corruption branch using a specially designed consistent loss during the training phase. This mechanism suppresses the response to irrelevant background features of FSTBs, thereby improving the perception of foreground contour. We conduct extensive experiments to validate the effectiveness and generalization of the proposed FOAM, which further improves the accuracy of state-of-the-art models on four datasets, specifically for the three overlapping object perception tasks: Prohibited Item Detection, Prohibited Item Segmentation, and Pneumonia Detection. The code will be open source once the paper is accepted.
GAA-TSO: Geometry-Aware Assisted Depth Completion for Transparent and Specular Objects
Mar 21, 2025



Transparent and specular objects are frequently encountered in daily life, factories, and laboratories. However, due to the unique optical properties, the depth information on these objects is usually incomplete and inaccurate, which poses significant challenges for downstream robotics tasks. Therefore, it is crucial to accurately restore the depth information of transparent and specular objects. Previous depth completion methods for these objects usually use RGB information as an additional channel of the depth image to perform depth prediction. Due to the poor-texture characteristics of transparent and specular objects, these methods that rely heavily on color information tend to generate structure-less depth predictions. Moreover, these 2D methods cannot effectively explore the 3D structure hidden in the depth channel, resulting in depth ambiguity. To this end, we propose a geometry-aware assisted depth completion method for transparent and specular objects, which focuses on exploring the 3D structural cues of the scene. Specifically, besides extracting 2D features from RGB-D input, we back-project the input depth to a point cloud and build the 3D branch to extract hierarchical scene-level 3D structural features. To exploit 3D geometric information, we design several gated cross-modal fusion modules to effectively propagate multi-level 3D geometric features to the image branch. In addition, we propose an adaptive correlation aggregation strategy to appropriately assign 3D features to the corresponding 2D features. Extensive experiments on ClearGrasp, OOD, TransCG, and STD datasets show that our method outperforms other state-of-the-art methods. We further demonstrate that our method significantly enhances the performance of downstream robotic grasping tasks.
CSPCL: Category Semantic Prior Contrastive Learning for Deformable DETR-Based Prohibited Item Detectors
Jan 28, 2025



Prohibited item detection based on X-ray images is one of the most effective security inspection methods. However, the foreground-background feature coupling caused by the overlapping phenomenon specific to X-ray images makes general detectors designed for natural images perform poorly. To address this issue, we propose a Category Semantic Prior Contrastive Learning (CSPCL) mechanism, which aligns the class prototypes perceived by the classifier with the content queries to correct and supplement the missing semantic information responsible for classification, thereby enhancing the model sensitivity to foreground features.To achieve this alignment, we design a specific contrastive loss, CSP loss, which includes Intra-Class Truncated Attraction (ITA) loss and Inter-Class Adaptive Repulsion (IAR) loss, and outperforms classic N-pair loss and InfoNCE loss. Specifically, ITA loss leverages class prototypes to attract intra-class category-specific content queries while preserving necessary distinctiveness. IAR loss utilizes class prototypes to adaptively repel inter-class category-specific content queries based on the similarity between class prototypes, helping disentangle features of similar categories.CSPCL is general and can be easily integrated into Deformable DETR-based models. Extensive experiments on the PIXray and OPIXray datasets demonstrate that CSPCL significantly enhances the performance of various state-of-the-art models without increasing complexity.The code will be open source once the paper is accepted.
CRoF: CLIP-based Robust Few-shot Learning on Noisy Labels
Dec 17, 2024



Noisy labels threaten the robustness of few-shot learning (FSL) due to the inexact features in a new domain. CLIP, a large-scale vision-language model, performs well in FSL on image-text embedding similarities, but it is susceptible to misclassification caused by noisy labels. How to enhance domain generalization of CLIP on noisy data within FSL tasks is a critical challenge. In this paper, we provide a novel view to mitigate the influence of noisy labels, CLIP-based Robust Few-shot learning (CRoF). CRoF is a general plug-in module for CLIP-based models. To avoid misclassification and confused label embedding, we design the few-shot task-oriented prompt generator to give more discriminative descriptions of each category. The proposed prompt achieves larger distances of inter-class textual embedding. Furthermore, rather than fully trusting zero-shot classification by CLIP, we fine-tune CLIP on noisy few-shot data in a new domain with a weighting strategy like label-smooth. The weights for multiple potentially correct labels consider the relationship between CLIP's prior knowledge and original label information to ensure reliability. Our multiple label loss function further supports robust training under this paradigm. Comprehensive experiments show that CRoF, as a plug-in, outperforms fine-tuned and vanilla CLIP models on different noise types and noise ratios.
Learning Pattern-Specific Experts for Time Series Forecasting Under Patch-level Distribution Shift
Oct 13, 2024



Time series forecasting, which aims to predict future values based on historical data, has garnered significant attention due to its broad range of applications. However, real-world time series often exhibit complex non-uniform distribution with varying patterns across segments, such as season, operating condition, or semantic meaning, making accurate forecasting challenging. Existing approaches, which typically train a single model to capture all these diverse patterns, often struggle with the pattern drifts between patches and may lead to poor generalization. To address these challenges, we propose \textbf{TFPS}, a novel architecture that leverages pattern-specific experts for more accurate and adaptable time series forecasting. TFPS employs a dual-domain encoder to capture both time-domain and frequency-domain features, enabling a more comprehensive understanding of temporal dynamics. It then uses subspace clustering to dynamically identify distinct patterns across data patches. Finally, pattern-specific experts model these unique patterns, delivering tailored predictions for each patch. By explicitly learning and adapting to evolving patterns, TFPS achieves significantly improved forecasting accuracy. Extensive experiments on real-world datasets demonstrate that TFPS outperforms state-of-the-art methods, particularly in long-term forecasting, through its dynamic and pattern-aware learning approach. The data and codes are available: \url{https://github.com/syrGitHub/TFPS}.
DriveScape: Towards High-Resolution Controllable Multi-View Driving Video Generation
Sep 11, 2024



Recent advancements in generative models have provided promising solutions for synthesizing realistic driving videos, which are crucial for training autonomous driving perception models. However, existing approaches often struggle with multi-view video generation due to the challenges of integrating 3D information while maintaining spatial-temporal consistency and effectively learning from a unified model. In this paper, we propose an end-to-end framework named DriveScape for multi-view, 3D condition-guided video generation. DriveScape not only streamlines the process by integrating camera data to ensure comprehensive spatial-temporal coverage, but also introduces a Bi-Directional Modulated Transformer module to effectively align 3D road structural information. As a result, our approach enables precise control over video generation, significantly enhancing realism and providing a robust solution for generating multi-view driving videos. Our framework achieves state-of-the-art results on the nuScenes dataset, demonstrating impressive generative quality metrics with an FID score of 8.34 and an FVD score of 76.39, as well as superior performance across various perception tasks. This paves the way for more accurate environmental simulations in autonomous driving. Our project homepage: https://metadrivescape.github.io/papers_project/drivescapev1/index.html
Fine-Grained Domain Generalization with Feature Structuralization
Jun 17, 2024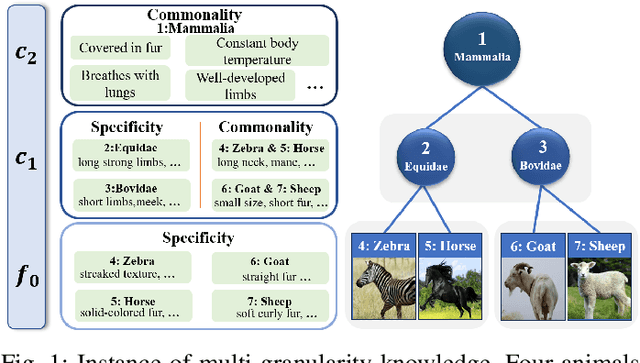
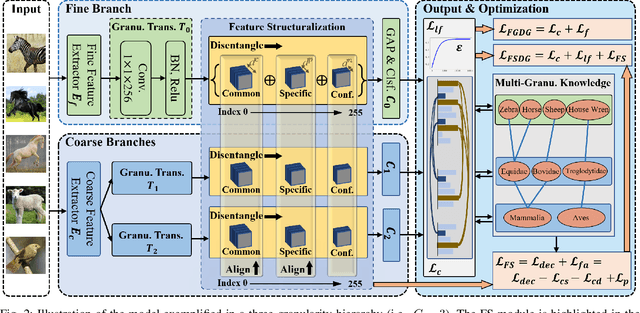
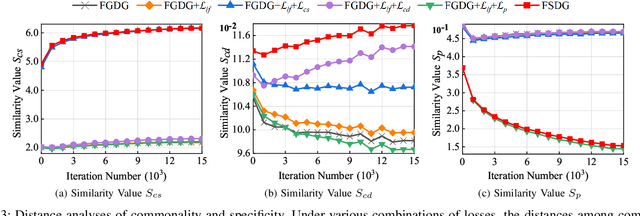
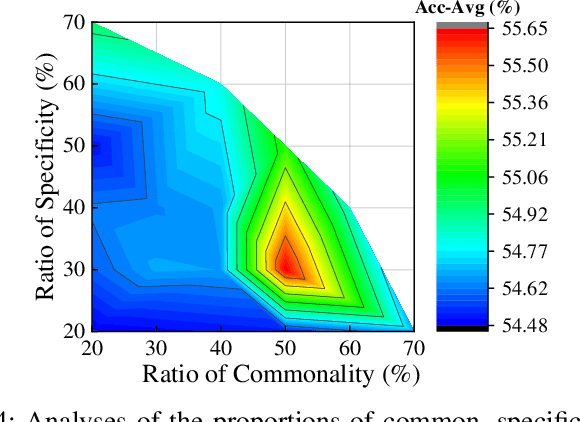
Fine-grained domain generalization (FGDG) is a more challenging task than traditional DG tasks due to its small inter-class variations and relatively large intra-class disparities. When domain distribution changes, the vulnerability of subtle features leads to a severe deterioration in model performance. Nevertheless, humans inherently demonstrate the capacity for generalizing to out-of-distribution data, leveraging structured multi-granularity knowledge that emerges from discerning the commonality and specificity within categories. Likewise, we propose a Feature Structuralized Domain Generalization (FSDG) model, wherein features experience structuralization into common, specific, and confounding segments, harmoniously aligned with their relevant semantic concepts, to elevate performance in FGDG. Specifically, feature structuralization (FS) is accomplished through joint optimization of five constraints: a decorrelation function applied to disentangled segments, three constraints ensuring common feature consistency and specific feature distinctiveness, and a prediction calibration term. By imposing these stipulations, FSDG is prompted to disentangle and align features based on multi-granularity knowledge, facilitating robust subtle distinctions among categories. Extensive experimentation on three benchmarks consistently validates the superiority of FSDG over state-of-the-art counterparts, with an average improvement of 6.2% in FGDG performance. Beyond that, the explainability analysis on explicit concept matching intensity between the shared concepts among categories and the model channels, along with experiments on various mainstream model architectures, substantiates the validity of FS.
Open-Vocabulary X-ray Prohibited Item Detection via Fine-tuning CLIP
Jun 16, 2024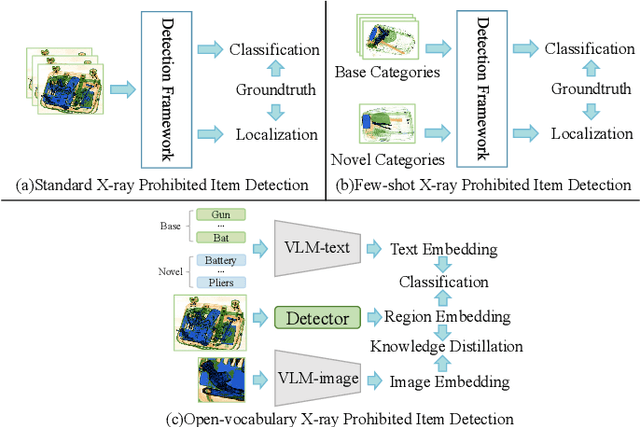
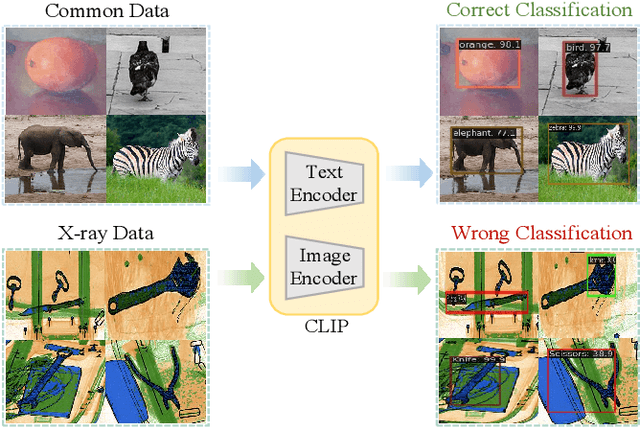
X-ray prohibited item detection is an essential component of security check and categories of prohibited item are continuously increasing in accordance with the latest laws. Previous works all focus on close-set scenarios, which can only recognize known categories used for training and often require time-consuming as well as labor-intensive annotations when learning novel categories, resulting in limited real-world applications. Although the success of vision-language models (e.g. CLIP) provides a new perspectives for open-set X-ray prohibited item detection, directly applying CLIP to X-ray domain leads to a sharp performance drop due to domain shift between X-ray data and general data used for pre-training CLIP. To address aforementioned challenges, in this paper, we introduce distillation-based open-vocabulary object detection (OVOD) task into X-ray security inspection domain by extending CLIP to learn visual representations in our specific X-ray domain, aiming to detect novel prohibited item categories beyond base categories on which the detector is trained. Specifically, we propose X-ray feature adapter and apply it to CLIP within OVOD framework to develop OVXD model. X-ray feature adapter containing three adapter submodules of bottleneck architecture, which is simple but can efficiently integrate new knowledge of X-ray domain with original knowledge, further bridge domain gap and promote alignment between X-ray images and textual concepts. Extensive experiments conducted on PIXray and PIDray datasets demonstrate that proposed method performs favorably against other baseline OVOD methods in detecting novel categories in X-ray scenario. It outperforms previous best result by 15.2 AP50 and 1.5 AP50 on PIXray and PIDray with achieving 21.0 AP50 and 27.8 AP50 respectively.
MMCL: Boosting Deformable DETR-Based Detectors with Multi-Class Min-Margin Contrastive Learning for Superior Prohibited Item Detection
Jun 05, 2024Prohibited Item detection in X-ray images is one of the most effective security inspection methods.However, differing from natural light images, the unique overlapping phenomena in X-ray images lead to the coupling of foreground and background features, thereby lowering the accuracy of general object detectors.Therefore, we propose a Multi-Class Min-Margin Contrastive Learning (MMCL) method that, by clarifying the category semantic information of content queries under the deformable DETR architecture, aids the model in extracting specific category foreground information from coupled features.Specifically, after grouping content queries by the number of categories, we employ the Multi-Class Inter-Class Exclusion (MIE) loss to push apart content queries from different groups. Concurrently, the Intra-Class Min-Margin Clustering (IMC) loss is utilized to attract content queries within the same group, while ensuring the preservation of necessary disparity. As training, the inherent Hungarian matching of the model progressively strengthens the alignment between each group of queries and the semantic features of their corresponding category of objects. This evolving coherence ensures a deep-seated grasp of category characteristics, consequently bolstering the anti-overlapping detection capabilities of models.MMCL is versatile and can be easily plugged into any deformable DETR-based model with dozens of lines of code. Extensive experiments on the PIXray and OPIXray datasets demonstrate that MMCL significantly enhances the performance of various state-of-the-art models without increasing complexity. The code has been released at https://github.com/anonymity0403/MMCL.