 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomalyPainter: Vision-Language-Diffusion Synergy for Zero-Shot Realistic and Diverse Industrial Anomaly Synthesis
Mar 11, 2025While existing anomaly synthesis methods have made remarkable progress, achieving both realism and diversity in synthesis remains a major obstacle. To address this, we propose AnomalyPainter, a zero-shot framework that breaks the diversity-realism trade-off dilemma through synergizing Vision Language Large Model (VLLM), Latent Diffusion Model (LDM), and our newly introduced texture library Tex-9K. Tex-9K is a professional texture library containing 75 categories and 8,792 texture assets crafted for diverse anomaly synthesis. Leveraging VLLM's general knowledge, reasonable anomaly text descriptions are generated for each industrial object and matched with relevant diverse textures from Tex-9K. These textures then guide the LDM via ControlNet to paint on normal images. Furthermore, we introduce Texture-Aware Latent Init to stabilize the natural-image-trained ControlNet for industrial images. Extensive experiments show that AnomalyPainter outperforms existing methods in realism, diversity, and generalization, achieving superior downstream performance.
Director3D: Real-world Camera Trajectory and 3D Scene Generation from Text
Jun 25, 2024


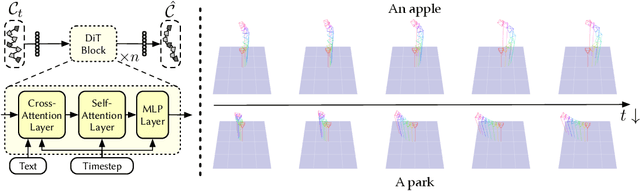
Recent advancements in 3D generation have leveraged synthetic datasets with ground truth 3D assets and predefined cameras. However, the potential of adopting real-world datasets, which can produce significantly more realistic 3D scenes, remains largely unexplored. In this work, we delve into the key challenge of the complex and scene-specific camera trajectories found in real-world captures. We introduce Director3D, a robust open-world text-to-3D generation framework, designed to generate both real-world 3D scenes and adaptive camera trajectories. To achieve this, (1) we first utilize a Trajectory Diffusion Transformer, acting as the Cinematographer, to model the distribution of camera trajectories based on textual descriptions. (2) Next, a Gaussian-driven Multi-view Latent Diffusion Model serves as the Decorator, modeling the image sequence distribution given the camera trajectories and texts. This model, fine-tuned from a 2D diffusion model, directly generates pixel-aligned 3D Gaussians as an immediate 3D scene representation for consistent denoising. (3) Lastly, the 3D Gaussians are refined by a novel SDS++ loss as the Detailer, which incorporates the prior of the 2D diffusion model. Extensive experiments demonstrate that Director3D outperforms existing methods, offering superior performance in real-world 3D generation.
Dual3D: Efficient and Consistent Text-to-3D Generation with Dual-mode Multi-view Latent Diffusion
May 16, 2024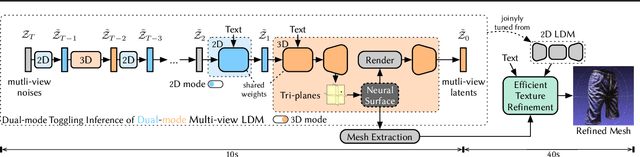



We present Dual3D, a novel text-to-3D generation framework that generates high-quality 3D assets from texts in only $1$ minute.The key component is a dual-mode multi-view latent diffusion model. Given the noisy multi-view latents, the 2D mode can efficiently denoise them with a single latent denoising network, while the 3D mode can generate a tri-plane neural surface for consistent rendering-based denoising. Most modules for both modes are tuned from a pre-trained text-to-image latent diffusion model to circumvent the expensive cost of training from scratch. To overcome the high rendering cost during inference, we propose the dual-mode toggling inference strategy to use only $1/10$ denoising steps with 3D mode, successfully generating a 3D asset in just $10$ seconds without sacrificing quality. The texture of the 3D asset can be further enhanced by our efficient texture refinement process in a short time. Extensive experiments demonstrate that our method delivers state-of-the-art performance while significantly reducing generation time. Our project page is available at https://dual3d.github.io