 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialReasoner: Towards Explicit and Generalizable 3D Spatial Reasoning
Apr 28, 2025



Recent studies in 3D spatial reasoning explore data-driven approaches and achieve enhanced spatial reasoning performance with reinforcement learning (RL). However, these methods typically perform spatial reasoning in an implicit manner, and it remains underexplored whether the acquired 3D knowledge generalizes to unseen question types at any stage of the training. In this work we introduce SpatialReasoner, a novel large vision-language model (LVLM) that address 3D spatial reasoning with explicit 3D representations shared between stages -- 3D perception, computation, and reasoning. Explicit 3D representations provide a coherent interface that supports advanced 3D spatial reasoning and enable us to study the factual errors made by LVLMs. Results show that our SpatialReasoner achieve improved performance on a variety of spatial reasoning benchmarks and generalizes better when evaluating on novel 3D spatial reasoning questions. Our study bridges the 3D parsing capabilities of prior visual foundation models with the powerful reasoning abilities of large language models, opening new directions for 3D spatial reasoning.
KeyVID: Keyframe-Aware Video Diffusion for Audio-Synchronized Visual Animation
Apr 13, 2025Generating video from various conditions, such as text, image, and audio, enables both spatial and temporal control, leading to high-quality generation results. Videos with dramatic motions often require a higher frame rate to ensure smooth motion. Currently, most audio-to-visual animation models use uniformly sampled frames from video clips. However, these uniformly sampled frames fail to capture significant key moments in dramatic motions at low frame rates and require significantly more memory when increasing the number of frames directly. In this paper, we propose KeyVID, a keyframe-aware audio-to-visual animation framework that significantly improves the generation quality for key moments in audio signals while maintaining computation efficiency. Given an image and an audio input, we first localize keyframe time steps from the audio. Then, we use a keyframe generator to generate the corresponding visual keyframes. Finally, we generate all intermediate frames using the motion interpolator. Through extensive experiments, we demonstrate that KeyVID significantly improves audio-video synchronization and video quality across multiple datasets, particularly for highly dynamic motions. The code is released in https://github.com/XingruiWang/KeyVID.
PulseCheck457: A Diagnostic Benchmark for 6D Spatial Reasoning of Large Multimodal Models
Feb 13, 2025Although large multimodal models (LMMs) have demonstrated remarkable capabilities in visual scene interpretation and reasoning, their capacity for complex and precise 3-dimensional spatial reasoning remains uncertain. Existing benchmarks focus predominantly on 2D spatial understanding and lack a framework to comprehensively evaluate 6D spatial reasoning across varying complexities. To address this limitation, we present PulseCheck457, a scalable and unbiased synthetic dataset designed with 4 key capability for spatial reasoning: multi-object recognition, 2D location, 3D location, and 3D orientation. We develop a cascading evaluation structure, constructing 7 question types across 5 difficulty levels that range from basic single object recognition to our new proposed complex 6D spatial reasoning tasks. We evaluated various large multimodal models (LMMs) on PulseCheck457, observing a general decline in performance as task complexity increases, particularly in 3D reasoning and 6D spatial tasks. To quantify these challenges, we introduce the Relative Performance Dropping Rate (RPDR), highlighting key weaknesses in 3D reasoning capabilities. Leveraging the unbiased attribute design of our dataset, we also uncover prediction biases across different attributes, with similar patterns observed in real-world image settings.
PulseCheck457: A Diagnostic Benchmark for Comprehensive Spatial Reasoning of Large Multimodal Models
Feb 12, 2025Although large multimodal models (LMMs) have demonstrated remarkable capabilities in visual scene interpretation and reasoning, their capacity for complex and precise 3-dimensional spatial reasoning remains uncertain. Existing benchmarks focus predominantly on 2D spatial understanding and lack a framework to comprehensively evaluate 6D spatial reasoning across varying complexities. To address this limitation, we present PulseCheck457, a scalable and unbiased synthetic dataset designed with 4 key capability for spatial reasoning: multi-object recognition, 2D location, 3D location, and 3D orientation. We develop a cascading evaluation structure, constructing 7 question types across 5 difficulty levels that range from basic single object recognition to our new proposed complex 6D spatial reasoning tasks. We evaluated various large multimodal models (LMMs) on PulseCheck457, observing a general decline in performance as task complexity increases, particularly in 3D reasoning and 6D spatial tasks. To quantify these challenges, we introduce the Relative Performance Dropping Rate (RPDR), highlighting key weaknesses in 3D reasoning capabilities. Leveraging the unbiased attribute design of our dataset, we also uncover prediction biases across different attributes, with similar patterns observed in real-world image settings.
GSemSplat: Generalizable Semantic 3D Gaussian Splatting from Uncalibrated Image Pairs
Dec 22, 2024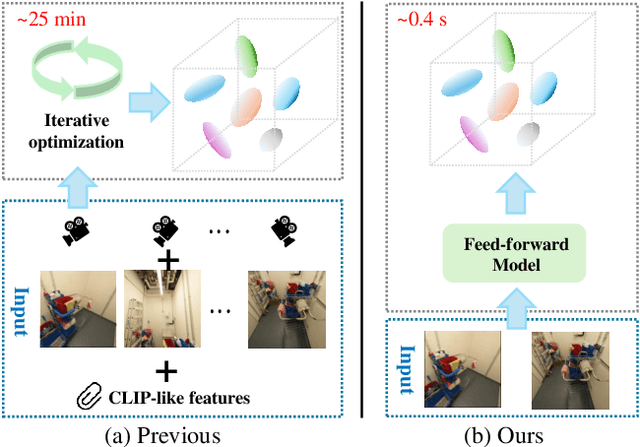



Modeling and understanding the 3D world is crucial for various applications, from augmented reality to robotic navigation. Recent advancements based on 3D Gaussian Splatting have integrated semantic information from multi-view images into Gaussian primitives. However, these methods typically require costly per-scene optimization from dense calibrated images, limiting their practicality. In this paper, we consider the new task of generalizable 3D semantic field modeling from sparse, uncalibrated image pairs. Building upon the Splatt3R architecture, we introduce GSemSplat, a framework that learns open-vocabulary semantic representations linked to 3D Gaussians without the need for per-scene optimization, dense image collections or calibration. To ensure effective and reliable learning of semantic features in 3D space, we employ a dual-feature approach that leverages both region-specific and context-aware semantic features as supervision in the 2D space. This allows us to capitalize on their complementary strengths. Experimental results on the ScanNet++ dataset demonstrate the effectiveness and superiority of our approach compared to the traditional scene-specific method. We hope our work will inspire more research into generalizable 3D understanding.
TIV-Diffusion: Towards Object-Centric Movement for Text-driven Image to Video Generation
Dec 13, 2024



Text-driven Image to Video Generation (TI2V) aims to generate controllable video given the first frame and corresponding textual description. The primary challenges of this task lie in two parts: (i) how to identify the target objects and ensure the consistency between the movement trajectory and the textual description. (ii) how to improve the subjective quality of generated videos. To tackle the above challenges, we propose a new diffusion-based TI2V framework, termed TIV-Diffusion, via object-centric textual-visual alignment, intending to achieve precise control and high-quality video generation based on textual-described motion for different objects. Concretely, we enable our TIV-Diffuion model to perceive the textual-described objects and their motion trajectory by incorporating the fused textual and visual knowledge through scale-offset modulation. Moreover, to mitigate the problems of object disappearance and misaligned objects and motion, we introduce an object-centric textual-visual alignment module, which reduces the risk of misaligned objects/motion by decoupling the objects in the reference image and aligning textual features with each object individually. Based on the above innovations, our TIV-Diffusion achieves state-of-the-art high-quality video generation compared with existing TI2V methods.
MoE-DiffIR: Task-customized Diffusion Priors for Universal Compressed Image Restoration
Jul 15, 2024We present MoE-DiffIR, an innovative universal compressed image restoration (CIR) method with task-customized diffusion priors. This intends to handle two pivotal challenges in the existing CIR methods: (i) lacking adaptability and universality for different image codecs, e.g., JPEG and WebP; (ii) poor texture generation capability, particularly at low bitrates. Specifically, our MoE-DiffIR develops the powerful mixture-of-experts (MoE) prompt module, where some basic prompts cooperate to excavate the task-customized diffusion priors from Stable Diffusion (SD) for each compression task. Moreover, the degradation-aware routing mechanism is proposed to enable the flexible assignment of basic prompts. To activate and reuse the cross-modality generation prior of SD, we design the visual-to-text adapter for MoE-DiffIR, which aims to adapt the embedding of low-quality images from the visual domain to the textual domain as the textual guidance for SD, enabling more consistent and reasonable texture generation. We also construct one comprehensive benchmark dataset for universal CIR, covering 21 types of degradations from 7 popular traditional and learned codecs. Extensive experiments on universal CIR have demonstrated the excellent robustness and texture restoration capability of our proposed MoE-DiffIR. The project can be found at https://renyulin-f.github.io/MoE-DiffIR.github.io/.
CoNo: Consistency Noise Injection for Tuning-free Long Video Diffusion
Jun 07, 2024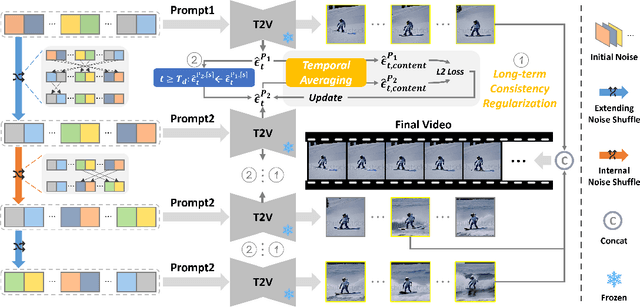
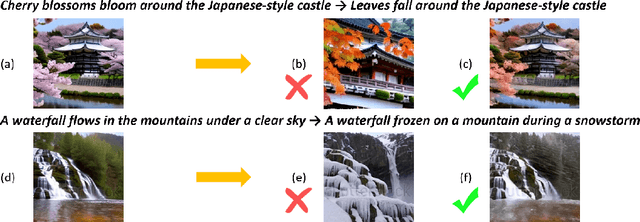
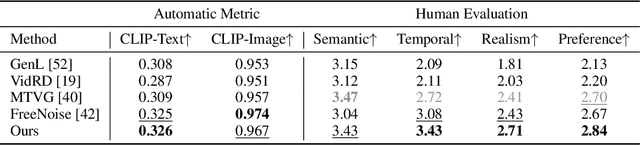
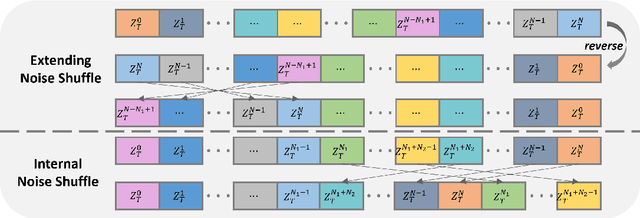
Tuning-free long video diffusion has been proposed to generate extended-duration videos with enriched content by reusing the knowledge from pre-trained short video diffusion model without retraining. However, most works overlook the fine-grained long-term video consistency modeling, resulting in limited scene consistency (i.e., unreasonable object or background transitions), especially with multiple text inputs. To mitigate this, we propose the Consistency Noise Injection, dubbed CoNo, which introduces the "look-back" mechanism to enhance the fine-grained scene transition between different video clips, and designs the long-term consistency regularization to eliminate the content shifts when extending video contents through noise prediction. In particular, the "look-back" mechanism breaks the noise scheduling process into three essential parts, where one internal noise prediction part is injected into two video-extending parts, intending to achieve a fine-grained transition between two video clips. The long-term consistency regularization focuses on explicitly minimizing the pixel-wise distance between the predicted noises of the extended video clip and the original one, thereby preventing abrupt scene transitions. Extensive experiments have shown the effectiveness of the above strategies by performing long-video generation under both single- and multi-text prompt conditions. The project has been available in https://wxrui182.github.io/CoNo.github.io/.
Compositional 4D Dynamic Scenes Understanding with Physics Priors for Video Question Answering
Jun 02, 2024



For vision-language models (VLMs), understanding the dynamic properties of objects and their interactions within 3D scenes from video is crucial for effective reasoning. In this work, we introduce a video question answering dataset SuperCLEVR-Physics that focuses on the dynamics properties of objects. We concentrate on physical concepts -- velocity, acceleration, and collisions within 4D scenes, where the model needs to fully understand these dynamics properties and answer the questions built on top of them. From the evaluation of a variety of current VLMs, we find that these models struggle with understanding these dynamic properties due to the lack of explicit knowledge about the spatial structure in 3D and world dynamics in time variants. To demonstrate the importance of an explicit 4D dynamics representation of the scenes in understanding world dynamics, we further propose NS-4Dynamics, a Neural-Symbolic model for reasoning on 4D Dynamics properties under explicit scene representation from videos. Using scene rendering likelihood combining physical prior distribution, the 4D scene parser can estimate the dynamics properties of objects over time to and interpret the observation into 4D scene representation as world states. By further incorporating neural-symbolic reasoning, our approach enables advanced applications in future prediction, factual reasoning, and counterfactual reasoning. Our experiments show that our NS-4Dynamics suppresses previous VLMs in understanding the dynamics properties and answering questions about factual queries, future prediction, and counterfactual reasoning. Moreover, based on the explicit 4D scene representation, our model is effective in reconstructing the 4D scenes and re-simulate the future or counterfactual events.
3D-Aware Visual Question Answering about Parts, Poses and Occlusions
Oct 27, 2023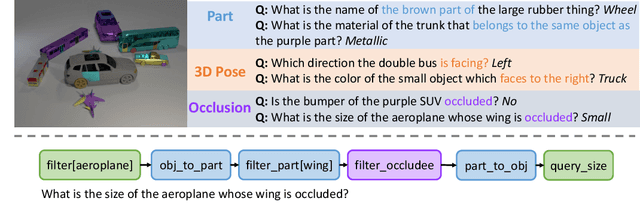
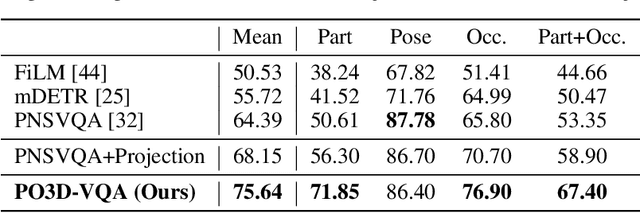
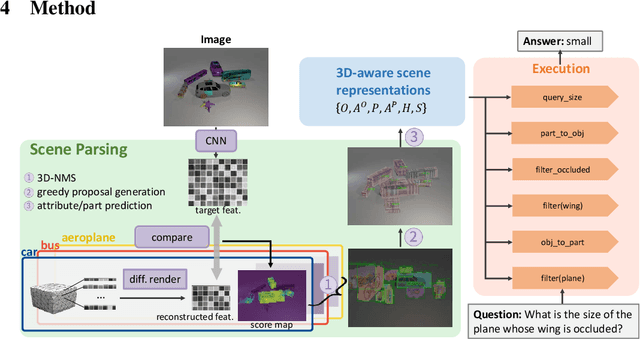
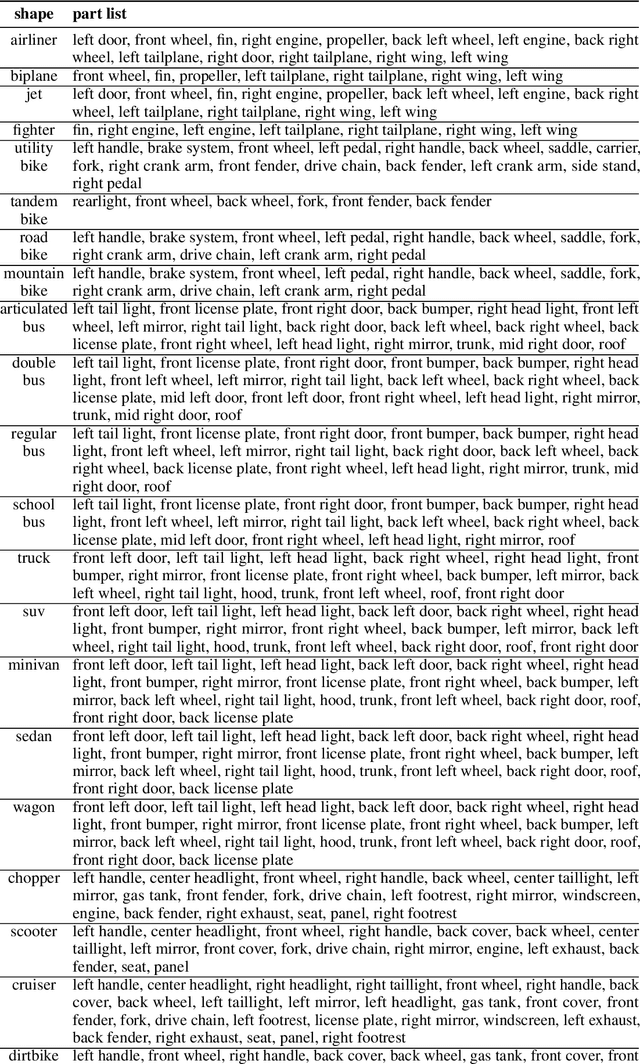
Despite rapid progress in Visual question answering (VQA), existing datasets and models mainly focus on testing reasoning in 2D. However, it is important that VQA models also understand the 3D structure of visual scenes, for example to support tasks like navigation or manipulation. This includes an understanding of the 3D object pose, their parts and occlusions. In this work, we introduce the task of 3D-aware VQA, which focuses on challenging questions that require a compositional reasoning over the 3D structure of visual scenes. We address 3D-aware VQA from both the dataset and the model perspective. First, we introduce Super-CLEVR-3D, a compositional reasoning dataset that contains questions about object parts, their 3D poses, and occlusions. Second, we propose PO3D-VQA, a 3D-aware VQA model that marries two powerful ideas: probabilistic neural symbolic program execution for reasoning and deep neural networks with 3D generative representations of objects for robust visual recognition. Our experimental results show our model PO3D-VQA outperforms existing methods significantly, but we still observe a significant performance gap compared to 2D VQA benchmarks, indicating that 3D-aware VQA remains an important open research area.