 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldBench: Disambiguating Physics for Diagnostic Evaluation of World Models
Jan 29, 2026Recent advances in generative foundational models, often termed "world models," have propelled interest in applying them to critical tasks like robotic planning and autonomous system training. For reliable deployment, these models must exhibit high physical fidelity, accurately simulating real-world dynamics. Existing physics-based video benchmarks, however, suffer from entanglement, where a single test simultaneously evaluates multiple physical laws and concepts, fundamentally limiting their diagnostic capability. We introduce WorldBench, a novel video-based benchmark specifically designed for concept-specific, disentangled evaluation, allowing us to rigorously isolate and assess understanding of a single physical concept or law at a time. To make WorldBench comprehensive, we design benchmarks at two different levels: 1) an evaluation of intuitive physical understanding with concepts such as object permanence or scale/perspective, and 2) an evaluation of low-level physical constants and material properties such as friction coefficients or fluid viscosity. When SOTA video-based world models are evaluated on WorldBench, we find specific patterns of failure in particular physics concepts, with all tested models lacking the physical consistency required to generate reliable real-world interactions. Through its concept-specific evaluation, WorldBench offers a more nuanced and scalable framework for rigorously evaluating the physical reasoning capabilities of video generation and world models, paving the way for more robust and generalizable world-model-driven learning.
SpatialLLM: A Compound 3D-Informed Design towards Spatially-Intelligent Large Multimodal Models
May 01, 2025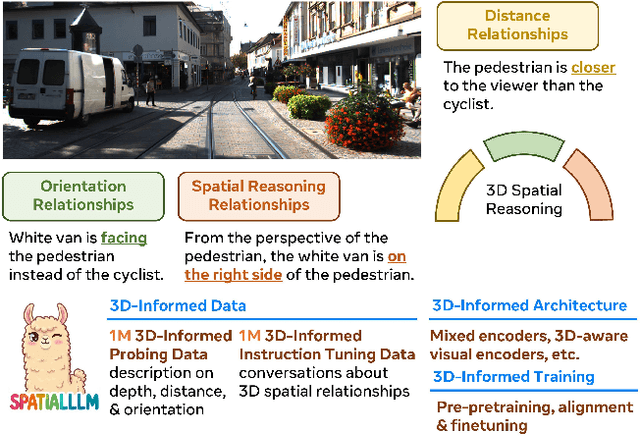
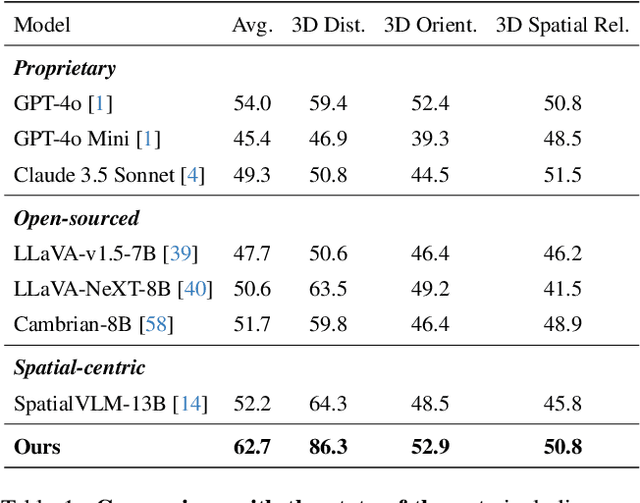
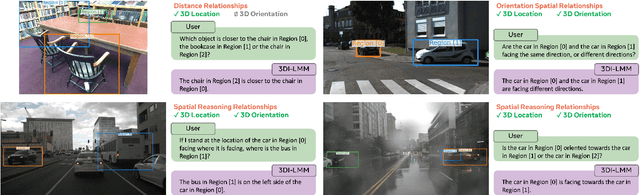
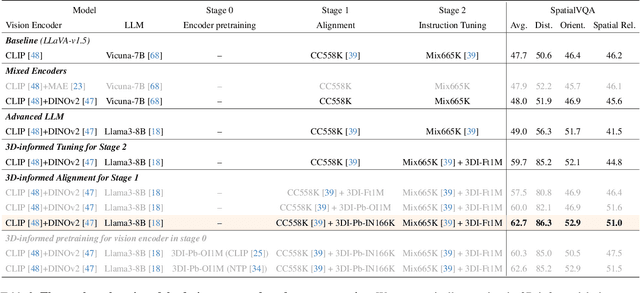
Humans naturally understand 3D spatial relationships, enabling complex reasoning like predicting collisions of vehicles from different directions. Current large multimodal models (LMMs), however, lack of this capability of 3D spatial reasoning. This limitation stems from the scarcity of 3D training data and the bias in current model designs toward 2D data. In this paper, we systematically study the impact of 3D-informed data, architecture, and training setups, introducing SpatialLLM, a large multi-modal model with advanced 3D spatial reasoning abilities. To address data limitations, we develop two types of 3D-informed training datasets: (1) 3D-informed probing data focused on object's 3D location and orientation, and (2) 3D-informed conversation data for complex spatial relationships. Notably, we are the first to curate VQA data that incorporate 3D orientation relationships on real images. Furthermore, we systematically integrate these two types of training data with the architectural and training designs of LMMs, providing a roadmap for optimal design aimed at achieving superior 3D reasoning capabilities. Our SpatialLLM advances machines toward highly capable 3D-informed reasoning, surpassing GPT-4o performance by 8.7%. Our systematic empirical design and the resulting findings offer valuable insights for future research in this direction.
PulseCheck457: A Diagnostic Benchmark for 6D Spatial Reasoning of Large Multimodal Models
Feb 13, 2025Although large multimodal models (LMMs) have demonstrated remarkable capabilities in visual scene interpretation and reasoning, their capacity for complex and precise 3-dimensional spatial reasoning remains uncertain. Existing benchmarks focus predominantly on 2D spatial understanding and lack a framework to comprehensively evaluate 6D spatial reasoning across varying complexities. To address this limitation, we present PulseCheck457, a scalable and unbiased synthetic dataset designed with 4 key capability for spatial reasoning: multi-object recognition, 2D location, 3D location, and 3D orientation. We develop a cascading evaluation structure, constructing 7 question types across 5 difficulty levels that range from basic single object recognition to our new proposed complex 6D spatial reasoning tasks. We evaluated various large multimodal models (LMMs) on PulseCheck457, observing a general decline in performance as task complexity increases, particularly in 3D reasoning and 6D spatial tasks. To quantify these challenges, we introduce the Relative Performance Dropping Rate (RPDR), highlighting key weaknesses in 3D reasoning capabilities. Leveraging the unbiased attribute design of our dataset, we also uncover prediction biases across different attributes, with similar patterns observed in real-world image settings.
PulseCheck457: A Diagnostic Benchmark for Comprehensive Spatial Reasoning of Large Multimodal Models
Feb 12, 2025Although large multimodal models (LMMs) have demonstrated remarkable capabilities in visual scene interpretation and reasoning, their capacity for complex and precise 3-dimensional spatial reasoning remains uncertain. Existing benchmarks focus predominantly on 2D spatial understanding and lack a framework to comprehensively evaluate 6D spatial reasoning across varying complexities. To address this limitation, we present PulseCheck457, a scalable and unbiased synthetic dataset designed with 4 key capability for spatial reasoning: multi-object recognition, 2D location, 3D location, and 3D orientation. We develop a cascading evaluation structure, constructing 7 question types across 5 difficulty levels that range from basic single object recognition to our new proposed complex 6D spatial reasoning tasks. We evaluated various large multimodal models (LMMs) on PulseCheck457, observing a general decline in performance as task complexity increases, particularly in 3D reasoning and 6D spatial tasks. To quantify these challenges, we introduce the Relative Performance Dropping Rate (RPDR), highlighting key weaknesses in 3D reasoning capabilities. Leveraging the unbiased attribute design of our dataset, we also uncover prediction biases across different attributes, with similar patterns observed in real-world image settings.
3DSRBench: A Comprehensive 3D Spatial Reasoning Benchmark
Dec 10, 20243D spatial reasoning is the ability to analyze and interpret the positions, orientations, and spatial relationships of objects within the 3D space. This allows models to develop a comprehensive understanding of the 3D scene, enabling their applicability to a broader range of areas, such as autonomous navigation, robotics, and AR/VR. While large multi-modal models (LMMs) have achieved remarkable progress in a wide range of image and video understanding tasks, their capabilities to perform 3D spatial reasoning on diverse natural images are less studied. In this work we present the first comprehensive 3D spatial reasoning benchmark, 3DSRBench, with 2,772 manually annotated visual question-answer pairs across 12 question types. We conduct robust and thorough evaluation of 3D spatial reasoning capabilities by balancing the data distribution and adopting a novel FlipEval strategy. To further study the robustness of 3D spatial reasoning w.r.t. camera 3D viewpoints, our 3DSRBench includes two subsets with 3D spatial reasoning questions on paired images with common and uncommon viewpoints. We benchmark a wide range of open-sourced and proprietary LMMs, uncovering their limitations in various aspects of 3D awareness, such as height, orientation, location, and multi-object reasoning, as well as their degraded performance on images with uncommon camera viewpoints. Our 3DSRBench provide valuable findings and insights about the future development of LMMs with strong 3D reasoning capabilities. Our project page and dataset is available https://3dsrbench.github.io.
ConceptAgent: LLM-Driven Precondition Grounding and Tree Search for Robust Task Planning and Execution
Oct 08, 2024



Robotic planning and execution in open-world environments is a complex problem due to the vast state spaces and high variability of task embodiment. Recent advances in perception algorithms, combined with Large Language Models (LLMs) for planning, offer promising solutions to these challenges, as the common sense reasoning capabilities of LLMs provide a strong heuristic for efficiently searching the action space. However, prior work fails to address the possibility of hallucinations from LLMs, which results in failures to execute the planned actions largely due to logical fallacies at high- or low-levels. To contend with automation failure due to such hallucinations, we introduce ConceptAgent, a natural language-driven robotic platform designed for task execution in unstructured environments. With a focus on scalability and reliability of LLM-based planning in complex state and action spaces, we present innovations designed to limit these shortcomings, including 1) Predicate Grounding to prevent and recover from infeasible actions, and 2) an embodied version of LLM-guided Monte Carlo Tree Search with self reflection. In simulation experiments, ConceptAgent achieved a 19% task completion rate across three room layouts and 30 easy level embodied tasks outperforming other state-of-the-art LLM-driven reasoning baselines that scored 10.26% and 8.11% on the same benchmark. Additionally, ablation studies on moderate to hard embodied tasks revealed a 20% increase in task completion from the baseline agent to the fully enhanced ConceptAgent, highlighting the individual and combined contributions of Predicate Grounding and LLM-guided Tree Search to enable more robust automation in complex state and action spaces.