 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodiedRAG: Dynamic 3D Scene Graph Retrieval for Efficient and Scalable Robot Task Planning
Oct 31, 2024



Recent advances in Large Language Models (LLMs) have helped facilitate exciting progress for robotic planning in real, open-world environments. 3D scene graphs (3DSGs) offer a promising environment representation for grounding such LLM-based planners as they are compact and semantically rich. However, as the robot's environment scales (e.g., number of entities tracked) and the complexity of scene graph information increases (e.g., maintaining more attributes), providing the 3DSG as-is to an LLM-based planner quickly becomes infeasible due to input token count limits and attentional biases present in LLMs. Inspired by the successes of Retrieval-Augmented Generation (RAG) methods that retrieve query-relevant document chunks for LLM question and answering, we adapt the paradigm for our embodied domain. Specifically, we propose a 3D scene subgraph retrieval framework, called EmbodiedRAG, that we augment an LLM-based planner with for executing natural language robotic tasks. Notably, our retrieved subgraphs adapt to changes in the environment as well as changes in task-relevancy as the robot executes its plan. We demonstrate EmbodiedRAG's ability to significantly reduce input token counts (by an order of magnitude) and planning time (up to 70% reduction in average time per planning step) while improving success rates on AI2Thor simulated household tasks with a single-arm, mobile manipulator. Additionally, we implement EmbodiedRAG on a quadruped with a manipulator to highlight the performance benefits for robot deployment at the edge in real environments.
ConceptAgent: LLM-Driven Precondition Grounding and Tree Search for Robust Task Planning and Execution
Oct 08, 2024



Robotic planning and execution in open-world environments is a complex problem due to the vast state spaces and high variability of task embodiment. Recent advances in perception algorithms, combined with Large Language Models (LLMs) for planning, offer promising solutions to these challenges, as the common sense reasoning capabilities of LLMs provide a strong heuristic for efficiently searching the action space. However, prior work fails to address the possibility of hallucinations from LLMs, which results in failures to execute the planned actions largely due to logical fallacies at high- or low-levels. To contend with automation failure due to such hallucinations, we introduce ConceptAgent, a natural language-driven robotic platform designed for task execution in unstructured environments. With a focus on scalability and reliability of LLM-based planning in complex state and action spaces, we present innovations designed to limit these shortcomings, including 1) Predicate Grounding to prevent and recover from infeasible actions, and 2) an embodied version of LLM-guided Monte Carlo Tree Search with self reflection. In simulation experiments, ConceptAgent achieved a 19% task completion rate across three room layouts and 30 easy level embodied tasks outperforming other state-of-the-art LLM-driven reasoning baselines that scored 10.26% and 8.11% on the same benchmark. Additionally, ablation studies on moderate to hard embodied tasks revealed a 20% increase in task completion from the baseline agent to the fully enhanced ConceptAgent, highlighting the individual and combined contributions of Predicate Grounding and LLM-guided Tree Search to enable more robust automation in complex state and action spaces.
Envelopes and Waves: Safe Multivehicle Collision Avoidance for Horizontal Non-deterministic Turns
May 10, 2022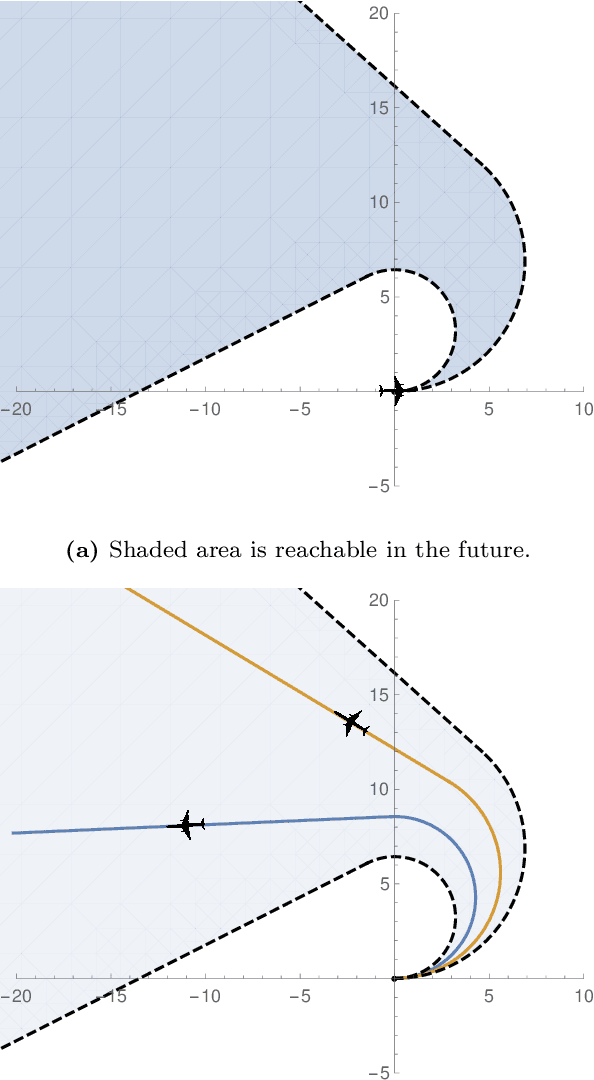

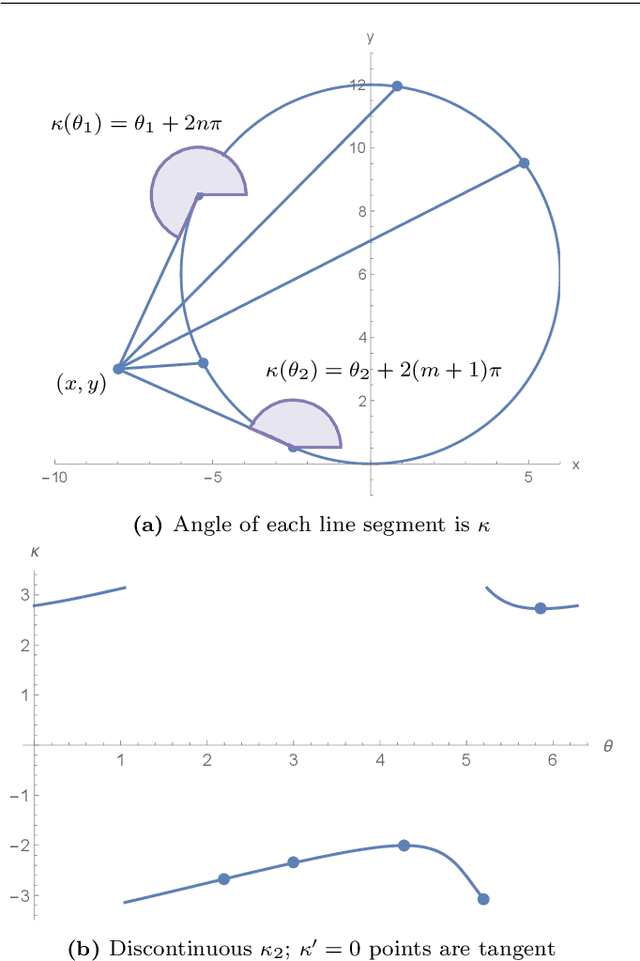
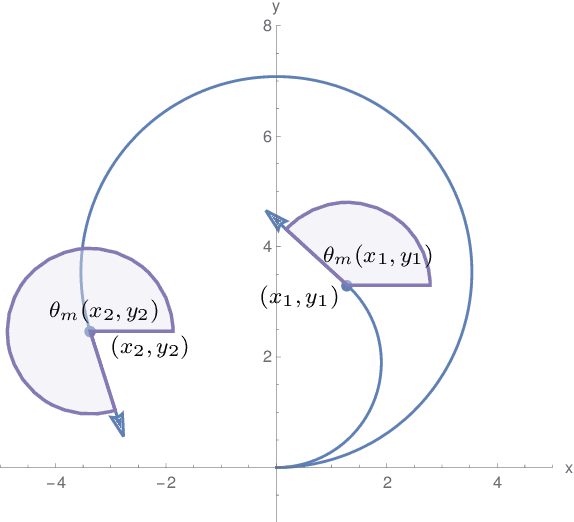
We present an approach to analyzing the safety of asynchronous, independent, non-deterministic, turn-to-bearing horizontal maneuvers for two vehicles. Future turn rates, final bearings, and continuously varying ground speeds throughout the encounter are unknown but restricted to known ranges. We develop a library of formal proofs about turning kinematics, and apply the library to create a formally verified timing computation. Additionally, we create a technique that evaluates future collision possibilities that is based on waves of position possibilities and relies on the timing computation. The result either determines that the encounter will be collision-free, or computes a safe overapproximation for when and where collisions may occur.
* Coq proofs are at https://bitbucket.org/ykouskoulas/ottb-foundation-proofs; Accepted 08 Mar 2022 (International Journal on Software Tools for Technology Transfer)
Incorrect by Construction: Fine Tuning Neural Networks for Guaranteed Performance on Finite Sets of Examples
Aug 03, 2020

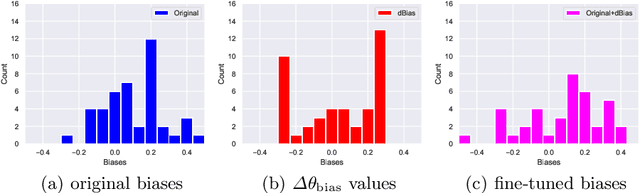
There is great interest in using formal methods to guarantee the reliability of deep neural networks. However, these techniques may also be used to implant carefully selected input-output pairs. We present initial results on a novel technique for using SMT solvers to fine tune the weights of a ReLU neural network to guarantee outcomes on a finite set of particular examples. This procedure can be used to ensure performance on key examples, but it could also be used to insert difficult-to-find incorrect examples that trigger unexpected performance. We demonstrate this approach by fine tuning an MNIST network to incorrectly classify a particular image and discuss the potential for the approach to compromise reliability of freely-shared machine learning models.