 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 Challenge on Short-form UGC Video Restoration in the Wild with Generative Models: Datasets, Methods and Results
Apr 12, 2026This paper presents an overview of the NTIRE 2026 Challenge on Short-form UGC Video Restoration in the Wild with Generative Models. This challenge utilizes a new short-form UGC (S-UGC) video restoration benchmark, termed KwaiVIR, which is contributed by USTC and Kuaishou Technology. It contains both synthetically distorted videos and real-world short-form UGC videos in the wild. For this edition, the released data include 200 synthetic training videos, 48 wild training videos, 11 validation videos, and 20 testing videos. The primary goal of this challenge is to establish a strong and practical benchmark for restoring short-form UGC videos under complex real-world degradations, especially in the emerging paradigm of generative-model-based S-UGC video restoration. This challenge has two tracks: (i) the primary track is a subjective track, where the evaluation is based on a user study; (ii) the second track is an objective track. These two tracks enable a comprehensive assessment of restoration quality. In total, 95 teams have registered for this competition. And 12 teams submitted valid final solutions and fact sheets for the testing phase. The submitted methods achieved strong performance on the KwaiVIR benchmark, demonstrating encouraging progress in short-form UGC video restoration in the wild.
UniMIC: Towards Universal Multi-modality Perceptual Image Compression
Dec 09, 2024



We present UniMIC, a universal multi-modality image compression framework, intending to unify the rate-distortion-perception (RDP) optimization for multiple image codecs simultaneously through excavating cross-modality generative priors. Unlike most existing works that need to design and optimize image codecs from scratch, our UniMIC introduces the visual codec repository, which incorporates amounts of representative image codecs and directly uses them as the basic codecs for various practical applications. Moreover, we propose multi-grained textual coding, where variable-length content prompt and compression prompt are designed and encoded to assist the perceptual reconstruction through the multi-modality conditional generation. In particular, a universal perception compensator is proposed to improve the perception quality of decoded images from all basic codecs at the decoder side by reusing text-assisted diffusion priors from stable diffusion. With the cooperation of the above three strategies, our UniMIC achieves a significant improvement of RDP optimization for different compression codecs, e.g., traditional and learnable codecs, and different compression costs, e.g., ultra-low bitrates. The code will be available in https://github.com/Amygyx/UniMIC .
MambaCSR: Dual-Interleaved Scanning for Compressed Image Super-Resolution With SSMs
Aug 21, 2024We present MambaCSR, a simple but effective framework based on Mamba for the challenging compressed image super-resolution (CSR) task. Particularly, the scanning strategies of Mamba are crucial for effective contextual knowledge modeling in the restoration process despite it relying on selective state space modeling for all tokens. In this work, we propose an efficient dual-interleaved scanning paradigm (DIS) for CSR, which is composed of two scanning strategies: (i) hierarchical interleaved scanning is designed to comprehensively capture and utilize the most potential contextual information within an image by simultaneously taking advantage of the local window-based and sequential scanning methods; (ii) horizontal-to-vertical interleaved scanning is proposed to reduce the computational cost by leaving the redundancy between the scanning of different directions. To overcome the non-uniform compression artifacts, we also propose position-aligned cross-scale scanning to model multi-scale contextual information. Experimental results on multiple benchmarks have shown the great performance of our MambaCSR in the compressed image super-resolution task. The code will be soon available in~\textcolor{magenta}{\url{https://github.com/renyulin-f/MambaCSR}}.
UCIP: A Universal Framework for Compressed Image Super-Resolution using Dynamic Prompt
Jul 18, 2024



Compressed Image Super-resolution (CSR) aims to simultaneously super-resolve the compressed images and tackle the challenging hybrid distortions caused by compression. However, existing works on CSR usually focuses on a single compression codec, i.e., JPEG, ignoring the diverse traditional or learning-based codecs in the practical application, e.g., HEVC, VVC, HIFIC, etc. In this work, we propose the first universal CSR framework, dubbed UCIP, with dynamic prompt learning, intending to jointly support the CSR distortions of any compression codecs/modes. Particularly, an efficient dynamic prompt strategy is proposed to mine the content/spatial-aware task-adaptive contextual information for the universal CSR task, using only a small amount of prompts with spatial size 1x1. To simplify contextual information mining, we introduce the novel MLP-like framework backbone for our UCIP by adapting the Active Token Mixer (ATM) to CSR tasks for the first time, where the global information modeling is only taken in horizontal and vertical directions with offset prediction. We also build an all-in-one benchmark dataset for the CSR task by collecting the datasets with the popular 6 diverse traditional and learning-based codecs, including JPEG, HEVC, VVC, HIFIC, etc., resulting in 23 common degradations. Extensive experiments have shown the consistent and excellent performance of our UCIP on universal CSR tasks. The project can be found in https://lixinustc.github.io/UCIP.github.io
MoE-DiffIR: Task-customized Diffusion Priors for Universal Compressed Image Restoration
Jul 15, 2024We present MoE-DiffIR, an innovative universal compressed image restoration (CIR) method with task-customized diffusion priors. This intends to handle two pivotal challenges in the existing CIR methods: (i) lacking adaptability and universality for different image codecs, e.g., JPEG and WebP; (ii) poor texture generation capability, particularly at low bitrates. Specifically, our MoE-DiffIR develops the powerful mixture-of-experts (MoE) prompt module, where some basic prompts cooperate to excavate the task-customized diffusion priors from Stable Diffusion (SD) for each compression task. Moreover, the degradation-aware routing mechanism is proposed to enable the flexible assignment of basic prompts. To activate and reuse the cross-modality generation prior of SD, we design the visual-to-text adapter for MoE-DiffIR, which aims to adapt the embedding of low-quality images from the visual domain to the textual domain as the textual guidance for SD, enabling more consistent and reasonable texture generation. We also construct one comprehensive benchmark dataset for universal CIR, covering 21 types of degradations from 7 popular traditional and learned codecs. Extensive experiments on universal CIR have demonstrated the excellent robustness and texture restoration capability of our proposed MoE-DiffIR. The project can be found at https://renyulin-f.github.io/MoE-DiffIR.github.io/.
Diffusion Models for Image Restoration and Enhancement -- A Comprehensive Survey
Aug 18, 2023
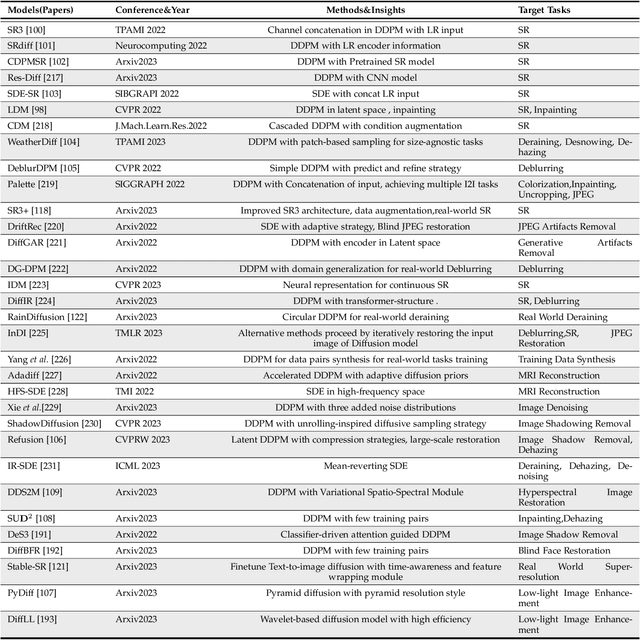
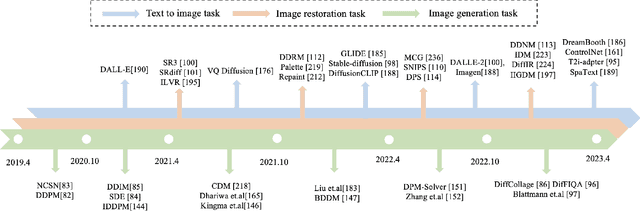
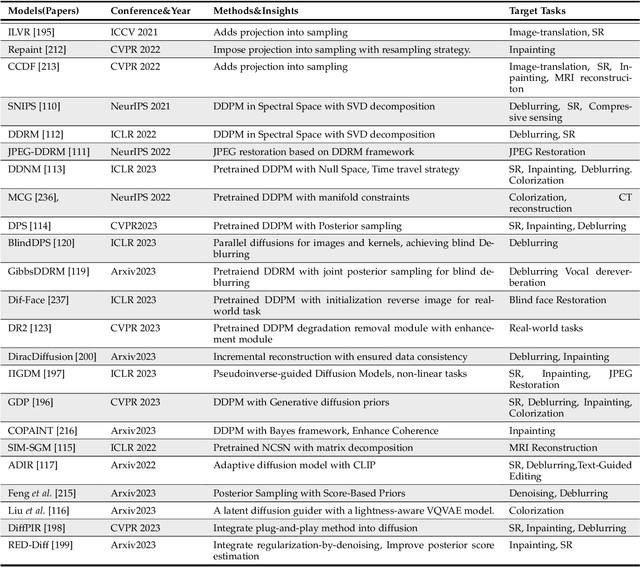
Image restoration (IR) has been an indispensable and challenging task in the low-level vision field, which strives to improve the subjective quality of images distorted by various forms of degradation. Recently, the diffusion model has achieved significant advancements in the visual generation of AIGC, thereby raising an intuitive question, "whether diffusion model can boost image restoration". To answer this, some pioneering studies attempt to integrate diffusion models into the image restoration task, resulting in superior performances than previous GAN-based methods. Despite that, a comprehensive and enlightening survey on diffusion model-based image restoration remains scarce. In this paper, we are the first to present a comprehensive review of recent diffusion model-based methods on image restoration, encompassing the learning paradigm, conditional strategy, framework design, modeling strategy, and evaluation. Concretely, we first introduce the background of the diffusion model briefly and then present two prevalent workflows that exploit diffusion models in image restoration. Subsequently, we classify and emphasize the innovative designs using diffusion models for both IR and blind/real-world IR, intending to inspire future development. To evaluate existing methods thoroughly, we summarize the commonly-used dataset, implementation details, and evaluation metrics. Additionally, we present the objective comparison for open-sourced methods across three tasks, including image super-resolution, deblurring, and inpainting. Ultimately, informed by the limitations in existing works, we propose five potential and challenging directions for the future research of diffusion model-based IR, including sampling efficiency, model compression, distortion simulation and estimation, distortion invariant learning, and framework design.