 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComp-X: On Defining an Interactive Learned Image Compression Paradigm With Expert-driven LLM Agent
Aug 21, 2025We present Comp-X, the first intelligently interactive image compression paradigm empowered by the impressive reasoning capability of large language model (LLM) agent. Notably, commonly used image codecs usually suffer from limited coding modes and rely on manual mode selection by engineers, making them unfriendly for unprofessional users. To overcome this, we advance the evolution of image coding paradigm by introducing three key innovations: (i) multi-functional coding framework, which unifies different coding modes of various objective/requirements, including human-machine perception, variable coding, and spatial bit allocation, into one framework. (ii) interactive coding agent, where we propose an augmented in-context learning method with coding expert feedback to teach the LLM agent how to understand the coding request, mode selection, and the use of the coding tools. (iii) IIC-bench, the first dedicated benchmark comprising diverse user requests and the corresponding annotations from coding experts, which is systematically designed for intelligently interactive image compression evaluation. Extensive experimental results demonstrate that our proposed Comp-X can understand the coding requests efficiently and achieve impressive textual interaction capability. Meanwhile, it can maintain comparable compression performance even with a single coding framework, providing a promising avenue for artificial general intelligence (AGI) in image compression.
UniMIC: Towards Universal Multi-modality Perceptual Image Compression
Dec 09, 2024



We present UniMIC, a universal multi-modality image compression framework, intending to unify the rate-distortion-perception (RDP) optimization for multiple image codecs simultaneously through excavating cross-modality generative priors. Unlike most existing works that need to design and optimize image codecs from scratch, our UniMIC introduces the visual codec repository, which incorporates amounts of representative image codecs and directly uses them as the basic codecs for various practical applications. Moreover, we propose multi-grained textual coding, where variable-length content prompt and compression prompt are designed and encoded to assist the perceptual reconstruction through the multi-modality conditional generation. In particular, a universal perception compensator is proposed to improve the perception quality of decoded images from all basic codecs at the decoder side by reusing text-assisted diffusion priors from stable diffusion. With the cooperation of the above three strategies, our UniMIC achieves a significant improvement of RDP optimization for different compression codecs, e.g., traditional and learnable codecs, and different compression costs, e.g., ultra-low bitrates. The code will be available in https://github.com/Amygyx/UniMIC .
Towards Defining an Efficient and Expandable File Format for AI-Generated Contents
Oct 15, 2024



Recently, AI-generated content (AIGC) has gained significant traction due to its powerful creation capability. However, the storage and transmission of large amounts of high-quality AIGC images inevitably pose new challenges for recent file formats. To overcome this, we define a new file format for AIGC images, named AIGIF, enabling ultra-low bitrate coding of AIGC images. Unlike compressing AIGC images intuitively with pixel-wise space as existing file formats, AIGIF instead compresses the generation syntax. This raises a crucial question: Which generation syntax elements, e.g., text prompt, device configuration, etc, are necessary for compression/transmission? To answer this question, we systematically investigate the effects of three essential factors: platform, generative model, and data configuration. We experimentally find that a well-designed composable bitstream structure incorporating the above three factors can achieve an impressive compression ratio of even up to 1/10,000 while still ensuring high fidelity. We also introduce an expandable syntax in AIGIF to support the extension of the most advanced generation models to be developed in the future.
Conditional Neural Video Coding with Spatial-Temporal Super-Resolution
Jan 25, 2024This document is an expanded version of a one-page abstract originally presented at the 2024 Data Compression Conference. It describes our proposed method for the video track of the Challenge on Learned Image Compression (CLIC) 2024. Our scheme follows the typical hybrid coding framework with some novel techniques. Firstly, we adopt Spynet network to produce accurate motion vectors for motion estimation. Secondly, we introduce the context mining scheme with conditional frame coding to fully exploit the spatial-temporal information. As for the low target bitrates given by CLIC, we integrate spatial-temporal super-resolution modules to improve rate-distortion performance. Our team name is IMCLVC.
NVTC: Nonlinear Vector Transform Coding
May 25, 2023



In theory, vector quantization (VQ) is always better than scalar quantization (SQ) in terms of rate-distortion (R-D) performance. Recent state-of-the-art methods for neural image compression are mainly based on nonlinear transform coding (NTC) with uniform scalar quantization, overlooking the benefits of VQ due to its exponentially increased complexity. In this paper, we first investigate on some toy sources, demonstrating that even if modern neural networks considerably enhance the compression performance of SQ with nonlinear transform, there is still an insurmountable chasm between SQ and VQ. Therefore, revolving around VQ, we propose a novel framework for neural image compression named Nonlinear Vector Transform Coding (NVTC). NVTC solves the critical complexity issue of VQ through (1) a multi-stage quantization strategy and (2) nonlinear vector transforms. In addition, we apply entropy-constrained VQ in latent space to adaptively determine the quantization boundaries for joint rate-distortion optimization, which improves the performance both theoretically and experimentally. Compared to previous NTC approaches, NVTC demonstrates superior rate-distortion performance, faster decoding speed, and smaller model size. Our code is available at https://github.com/USTC-IMCL/NVTC
Exploring the Rate-Distortion-Complexity Optimization in Neural Image Compression
May 12, 2023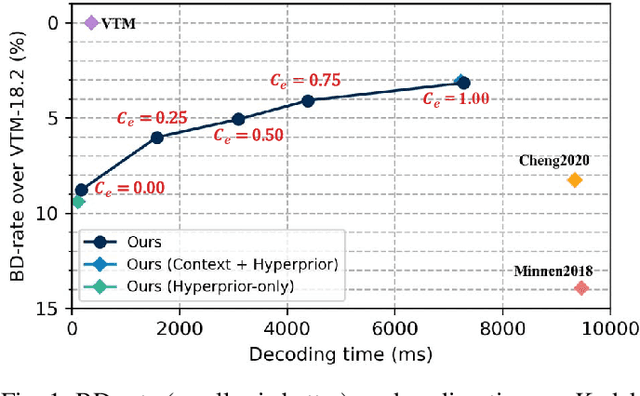
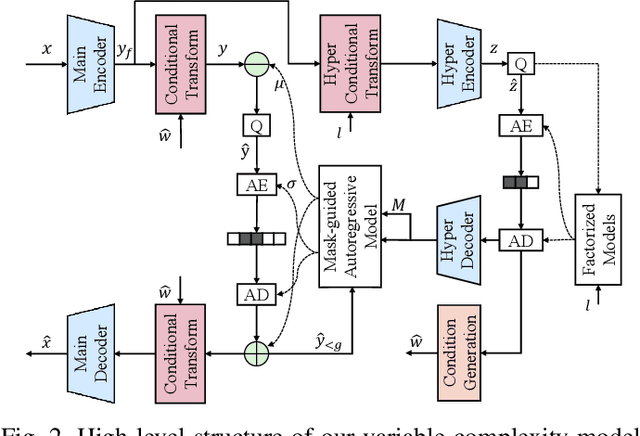
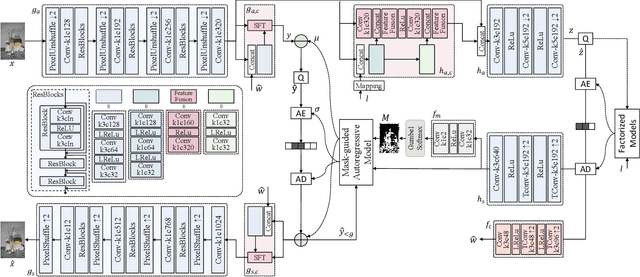
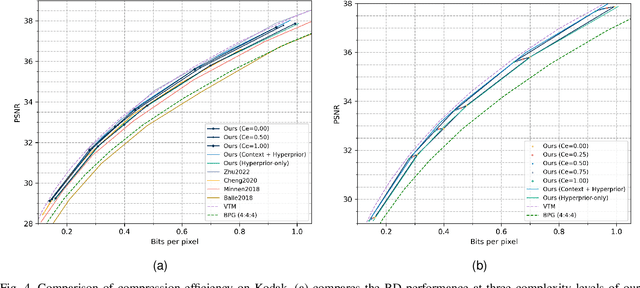
Despite a short history, neural image codecs have been shown to surpass classical image codecs in terms of rate-distortion performance. However, most of them suffer from significantly longer decoding times, which hinders the practical applications of neural image codecs. This issue is especially pronounced when employing an effective yet time-consuming autoregressive context model since it would increase entropy decoding time by orders of magnitude. In this paper, unlike most previous works that pursue optimal RD performance while temporally overlooking the coding complexity, we make a systematical investigation on the rate-distortion-complexity (RDC) optimization in neural image compression. By quantifying the decoding complexity as a factor in the optimization goal, we are now able to precisely control the RDC trade-off and then demonstrate how the rate-distortion performance of neural image codecs could adapt to various complexity demands. Going beyond the investigation of RDC optimization, a variable-complexity neural codec is designed to leverage the spatial dependencies adaptively according to industrial demands, which supports fine-grained complexity adjustment by balancing the RDC tradeoff. By implementing this scheme in a powerful base model, we demonstrate the feasibility and flexibility of RDC optimization for neural image codecs.
Semantically Structured Image Compression via Irregular Group-Based Decoupling
May 04, 2023



Image compression techniques typically focus on compressing rectangular images for human consumption, however, resulting in transmitting redundant content for downstream applications. To overcome this limitation, some previous works propose to semantically structure the bitstream, which can meet specific application requirements by selective transmission and reconstruction. Nevertheless, they divide the input image into multiple rectangular regions according to semantics and ignore avoiding information interaction among them, causing waste of bitrate and distorted reconstruction of region boundaries. In this paper, we propose to decouple an image into multiple groups with irregular shapes based on a customized group mask and compress them independently. Our group mask describes the image at a finer granularity, enabling significant bitrate saving by reducing the transmission of redundant content. Moreover, to ensure the fidelity of selective reconstruction, this paper proposes the concept of group-independent transform that maintain the independence among distinct groups. And we instantiate it by the proposed Group-Independent Swin-Block (GI Swin-Block). Experimental results demonstrate that our framework structures the bitstream with negligible cost, and exhibits superior performance on both visual quality and intelligent task supporting.
Image Coding for Machines with Omnipotent Feature Learning
Jul 07, 2022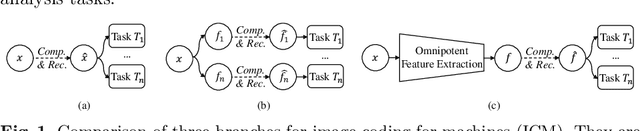

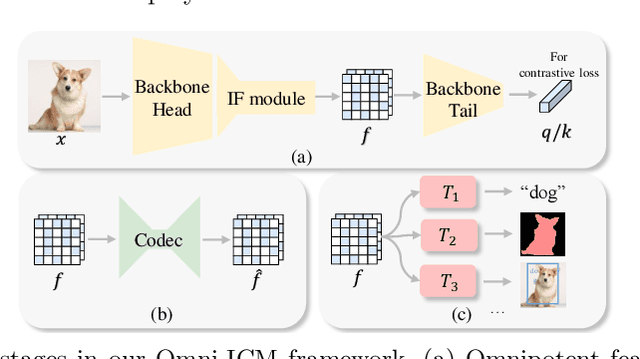
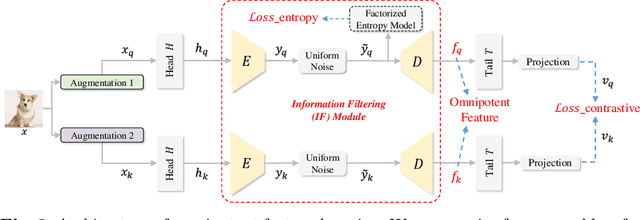
Image Coding for Machines (ICM) aims to compress images for AI tasks analysis rather than meeting human perception. Learning a kind of feature that is both general (for AI tasks) and compact (for compression) is pivotal for its success. In this paper, we attempt to develop an ICM framework by learning universal features while also considering compression. We name such features as omnipotent features and the corresponding framework as Omni-ICM. Considering self-supervised learning (SSL) improves feature generalization, we integrate it with the compression task into the Omni-ICM framework to learn omnipotent features. However, it is non-trivial to coordinate semantics modeling in SSL and redundancy removing in compression, so we design a novel information filtering (IF) module between them by co-optimization of instance distinguishment and entropy minimization to adaptively drop information that is weakly related to AI tasks (e.g., some texture redundancy). Different from previous task-specific solutions, Omni-ICM could directly support AI tasks analysis based on the learned omnipotent features without joint training or extra transformation. Albeit simple and intuitive, Omni-ICM significantly outperforms existing traditional and learning-based codecs on multiple fundamental vision tasks.
Semantically Video Coding: Instill Static-Dynamic Clues into Structured Bitstream for AI Tasks
Jan 25, 2022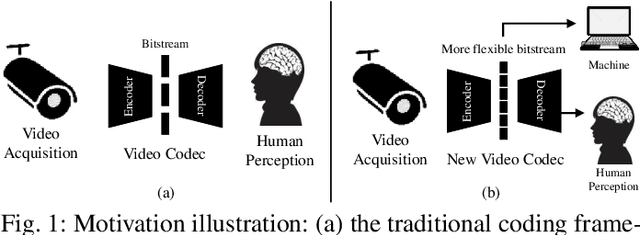
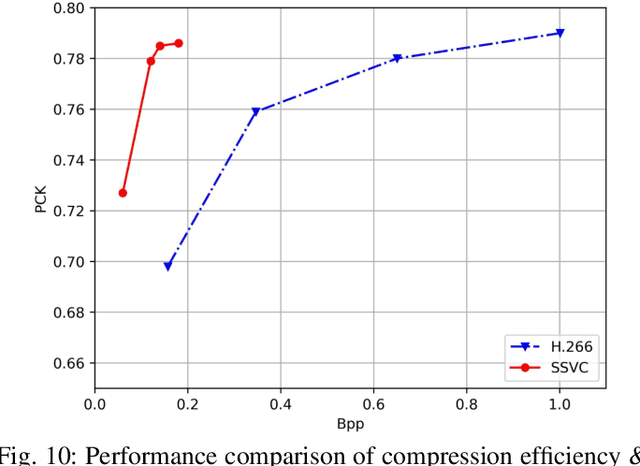
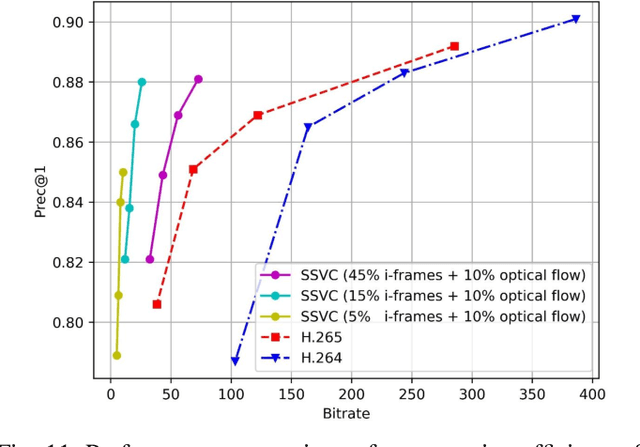

Traditional media coding schemes typically encode image/video into a semantic-unknown binary stream, which fails to directly support downstream intelligent tasks at the bitstream level. Semantically Structured Image Coding (SSIC) framework makes the first attempt to enable decoding-free or partial-decoding image intelligent task analysis via a Semantically Structured Bitstream (SSB). However, the SSIC only considers image coding and its generated SSB only contains the static object information. In this paper, we extend the idea of semantically structured coding from video coding perspective and propose an advanced Semantically Structured Video Coding (SSVC) framework to support heterogeneous intelligent applications. Video signals contain more rich dynamic motion information and exist more redundancy due to the similarity between adjacent frames. Thus, we present a reformulation of semantically structured bitstream (SSB) in SSVC which contains both static object characteristics and dynamic motion clues. Specifically, we introduce optical flow to encode continuous motion information and reduce cross-frame redundancy via a predictive coding architecture, then the optical flow and residual information are reorganized into SSB, which enables the proposed SSVC could better adaptively support video-based downstream intelligent applications. Extensive experiments demonstrate that the proposed SSVC framework could directly support multiple intelligent tasks just depending on a partially decoded bitstream. This avoids the full bitstream decompression and thus significantly saves bitrate/bandwidth consumption for intelligent analytics. We verify this point on the tasks of image object detection, pose estimation, video action recognition, video object segmentation, etc.
Learning Cross-Scale Prediction for Efficient Neural Video Compression
Dec 26, 2021


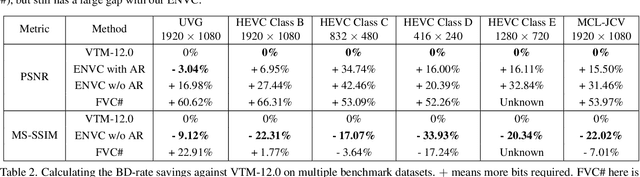
In this paper, we present the first neural video codec that can compete with the latest coding standard H.266/VVC in terms of sRGB PSNR on UVG dataset for the low-latency mode. Existing neural hybrid video coding approaches rely on optical flow or Gaussian-scale flow for prediction, which cannot support fine-grained adaptation to diverse motion content. Towards more content-adaptive prediction, we propose a novel cross-scale prediction module that achieves more effective motion compensation. Specifically, on the one hand, we produce a reference feature pyramid as prediction sources, then transmit cross-scale flows that leverage the feature scale to control the precision of prediction. On the other hand, we introduce the mechanism of weighted prediction into the scenario of prediction with a single reference frame, where cross-scale weight maps are transmitted to synthesize a fine prediction result. In addition to the cross-scale prediction module, we further propose a multi-stage quantization strategy, which improves the rate-distortion performance with no extra computational penalty during inference. We show the encouraging performance of our efficient neural video codec (ENVC) on several common benchmark datasets and analyze in detail the effectiveness of every important component.