 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence-Calibrated Small-Large Language Model Collaboration for Cost-Efficient Reasoning
Mar 04, 2026Large language models (LLMs) demonstrate superior reasoning capabilities compared to small language models (SLMs), but incur substantially higher costs. We propose COllaborative REAsoner (COREA), a system that cascades an SLM with an LLM to achieve a balance between accuracy and cost in complex reasoning tasks. COREA first attempts to answer questions using the SLM, which outputs both an answer and a verbalized confidence score. Questions with confidence below a predefined threshold are deferred to the LLM for more accurate resolution. We introduce a reinforcement learning-based training algorithm that aligns the SLM's confidence through an additional confidence calibration reward. Extensive experiments demonstrate that our method jointly improves the SLM's reasoning ability and confidence calibration across diverse datasets and model backbones. Compared to using the LLM alone, COREA reduces cost by 21.5% and 16.8% on out-of-domain math and non-math datasets, respectively, with only an absolute pass@1 drop within 2%.
Your AI-Generated Image Detector Can Secretly Achieve SOTA Accuracy, If Calibrated
Feb 02, 2026Despite being trained on balanced datasets, existing AI-generated image detectors often exhibit systematic bias at test time, frequently misclassifying fake images as real. We hypothesize that this behavior stems from distributional shift in fake samples and implicit priors learned during training. Specifically, models tend to overfit to superficial artifacts that do not generalize well across different generation methods, leading to a misaligned decision threshold when faced with test-time distribution shift. To address this, we propose a theoretically grounded post-hoc calibration framework based on Bayesian decision theory. In particular, we introduce a learnable scalar correction to the model's logits, optimized on a small validation set from the target distribution while keeping the backbone frozen. This parametric adjustment compensates for distributional shift in model output, realigning the decision boundary even without requiring ground-truth labels. Experiments on challenging benchmarks show that our approach significantly improves robustness without retraining, offering a lightweight and principled solution for reliable and adaptive AI-generated image detection in the open world. Code is available at https://github.com/muliyangm/AIGI-Det-Calib.
Conditional Neural Video Coding with Spatial-Temporal Super-Resolution
Jan 25, 2024This document is an expanded version of a one-page abstract originally presented at the 2024 Data Compression Conference. It describes our proposed method for the video track of the Challenge on Learned Image Compression (CLIC) 2024. Our scheme follows the typical hybrid coding framework with some novel techniques. Firstly, we adopt Spynet network to produce accurate motion vectors for motion estimation. Secondly, we introduce the context mining scheme with conditional frame coding to fully exploit the spatial-temporal information. As for the low target bitrates given by CLIC, we integrate spatial-temporal super-resolution modules to improve rate-distortion performance. Our team name is IMCLVC.
MiNL: Micro-images based Neural Representation for Light Fields
Sep 17, 2022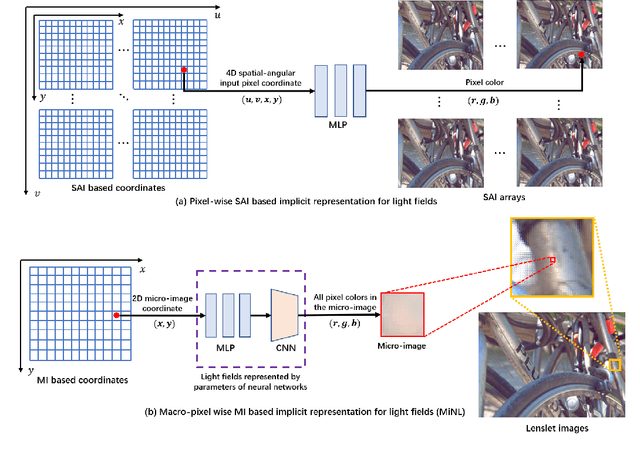
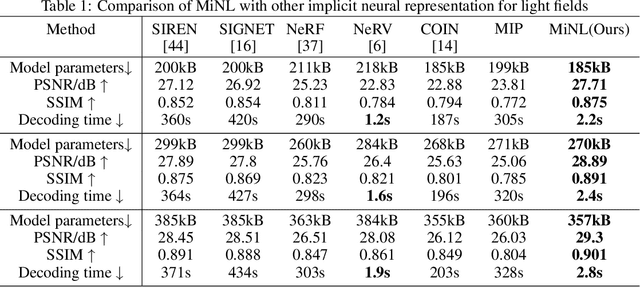
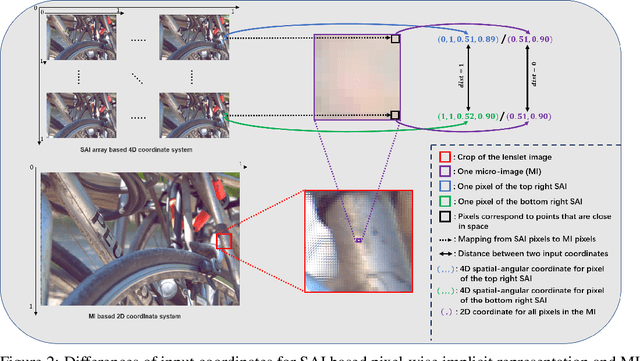
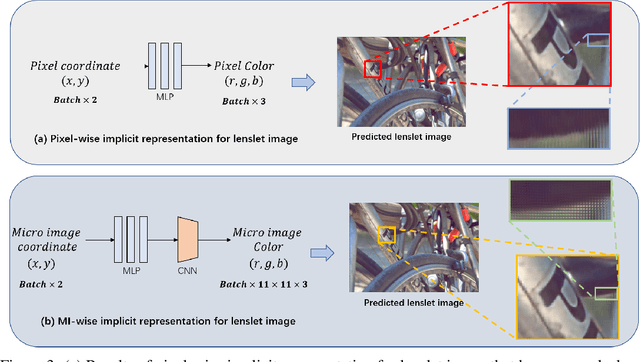
Traditional representations for light fields can be separated into two types: explicit representation and implicit representation. Unlike explicit representation that represents light fields as Sub-Aperture Images (SAIs) based arrays or Micro-Images (MIs) based lenslet images, implicit representation treats light fields as neural networks, which is inherently a continuous representation in contrast to discrete explicit representation. However, at present almost all the implicit representations for light fields utilize SAIs to train an MLP to learn a pixel-wise mapping from 4D spatial-angular coordinate to pixel colors, which is neither compact nor of low complexity. Instead, in this paper we propose MiNL, a novel MI-wise implicit neural representation for light fields that train an MLP + CNN to learn a mapping from 2D MI coordinates to MI colors. Given the micro-image's coordinate, MiNL outputs the corresponding micro-image's RGB values. Light field encoding in MiNL is just training a neural network to regress the micro-images and the decoding process is a simple feedforward operation. Compared with common pixel-wise implicit representation, MiNL is more compact and efficient that has faster decoding speed (\textbf{$\times$80$\sim$180} speed-up) as well as better visual quality (\textbf{1$\sim$4dB} PSNR improvement on average).