 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe and Interpretable Multimodal Path Planning for Multi-Agent Cooperation
Feb 22, 2026Successful cooperation among decentralized agents requires each agent to quickly adapt its plan to the behavior of other agents. In scenarios where agents cannot confidently predict one another's intentions and plans, language communication can be crucial for ensuring safety. In this work, we focus on path-level cooperation in which agents must adapt their paths to one another in order to avoid collisions or perform physical collaboration such as joint carrying. In particular, we propose a safe and interpretable multimodal path planning method, CaPE (Code as Path Editor), which generates and updates path plans for an agent based on the environment and language communication from other agents. CaPE leverages a vision-language model (VLM) to synthesize a path editing program verified by a model-based planner, grounding communication to path plan updates in a safe and interpretable way. We evaluate our approach in diverse simulated and real-world scenarios, including multi-robot and human-robot cooperation in autonomous driving, household, and joint carrying tasks. Experimental results demonstrate that CaPE can be integrated into different robotic systems as a plug-and-play module, greatly enhancing a robot's ability to align its plan to language communication from other robots or humans. We also show that the combination of the VLM-based path editing program synthesis and model-based planning safety enables robots to achieve open-ended cooperation while maintaining safety and interpretability.
PartInstruct: Part-level Instruction Following for Fine-grained Robot Manipulation
May 27, 2025Fine-grained robot manipulation, such as lifting and rotating a bottle to display the label on the cap, requires robust reasoning about object parts and their relationships with intended tasks. Despite recent advances in training general-purpose robot manipulation policies guided by language instructions, there is a notable lack of large-scale datasets for fine-grained manipulation tasks with part-level instructions and diverse 3D object instances annotated with part-level labels. In this work, we introduce PartInstruct, the first large-scale benchmark for training and evaluating fine-grained robot manipulation models using part-level instructions. PartInstruct comprises 513 object instances across 14 categories, each annotated with part-level information, and 1302 fine-grained manipulation tasks organized into 16 task classes. Our training set consists of over 10,000 expert demonstrations synthesized in a 3D simulator, where each demonstration is paired with a high-level task instruction, a chain of base part-based skill instructions, and ground-truth 3D information about the object and its parts. Additionally, we designed a comprehensive test suite to evaluate the generalizability of learned policies across new states, objects, and tasks. We evaluated several state-of-the-art robot manipulation approaches, including end-to-end vision-language policy learning and bi-level planning models for robot manipulation on our benchmark. The experimental results reveal that current models struggle to robustly ground part concepts and predict actions in 3D space, and face challenges when manipulating object parts in long-horizon tasks.
Semantic Convergence: Harmonizing Recommender Systems via Two-Stage Alignment and Behavioral Semantic Tokenization
Dec 18, 2024



Large language models (LLMs), endowed with exceptional reasoning capabilities, are adept at discerning profound user interests from historical behaviors, thereby presenting a promising avenue for the advancement of recommendation systems. However, a notable discrepancy persists between the sparse collaborative semantics typically found in recommendation systems and the dense token representations within LLMs. In our study, we propose a novel framework that harmoniously merges traditional recommendation models with the prowess of LLMs. We initiate this integration by transforming ItemIDs into sequences that align semantically with the LLMs space, through the proposed Alignment Tokenization module. Additionally, we design a series of specialized supervised learning tasks aimed at aligning collaborative signals with the subtleties of natural language semantics. To ensure practical applicability, we optimize online inference by pre-caching the top-K results for each user, reducing latency and improving effciency. Extensive experimental evidence indicates that our model markedly improves recall metrics and displays remarkable scalability of recommendation systems.
Enabling Mammography with Co-Robotic Ultrasound
Dec 16, 2023Ultrasound (US) imaging is a vital adjunct to mammography in breast cancer screening and diagnosis, but its reliance on hand-held transducers often lacks repeatability and heavily depends on sonographers' skills. Integrating US systems from different vendors further complicates clinical standards and workflows. This research introduces a co-robotic US platform for repeatable, accurate, and vendor-independent breast US image acquisition. The platform can autonomously perform 3D volume scans or swiftly acquire real-time 2D images of suspicious lesions. Utilizing a Universal Robot UR5 with an RGB camera, a force sensor, and an L7-4 linear array transducer, the system achieves autonomous navigation, motion control, and image acquisition. The calibrations, including camera-mammogram, robot-camera, and robot-US, were rigorously conducted and validated. Governed by a PID force control, the robot-held transducer maintains a constant contact force with the compression plate during the scan for safety and patient comfort. The framework was validated on a lesion-mimicking phantom. Our results indicate that the developed co-robotic US platform promises to enhance the precision and repeatability of breast cancer screening and diagnosis. Additionally, the platform offers straightforward integration into most mammographic devices to ensure vendor-independence.
Applications of Uncalibrated Image Based Visual Servoing in Micro- and Macroscale Robotics
Apr 17, 2023We present a robust markerless image based visual servoing method that enables precision robot control without hand-eye and camera calibrations in 1, 3, and 5 degrees-of-freedom. The system uses two cameras for observing the workspace and a combination of classical image processing algorithms and deep learning based methods to detect features on camera images. The only restriction on the placement of the two cameras is that relevant image features must be visible in both views. The system enables precise robot-tool to workspace interactions even when the physical setup is disturbed, for example if cameras are moved or the workspace shifts during manipulation. The usefulness of the visual servoing method is demonstrated and evaluated in two applications: in the calibration of a micro-robotic system that dissects mosquitoes for the automated production of a malaria vaccine, and a macro-scale manipulation system for fastening screws using a UR10 robot. Evaluation results indicate that our image based visual servoing method achieves human-like manipulation accuracy in challenging setups even without camera calibration.
High-order Spatial Interactions Enhanced Lightweight Model for Optical Remote Sensing Image-based Small Ship Detection
Apr 07, 2023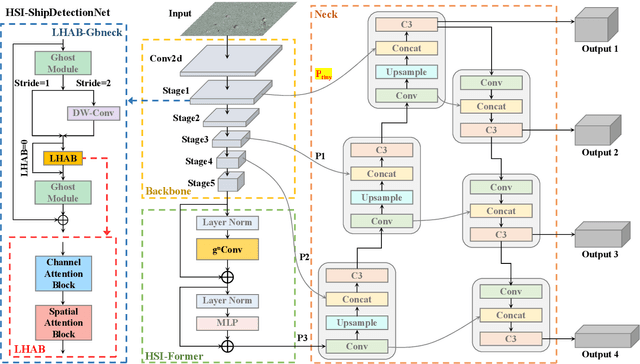
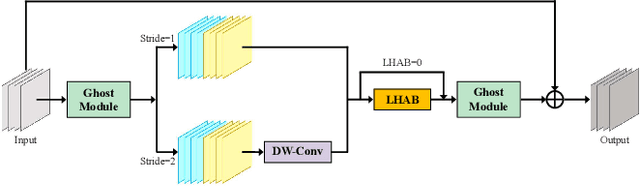
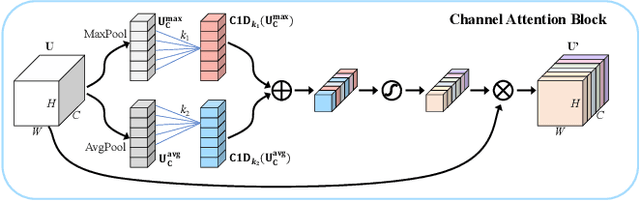
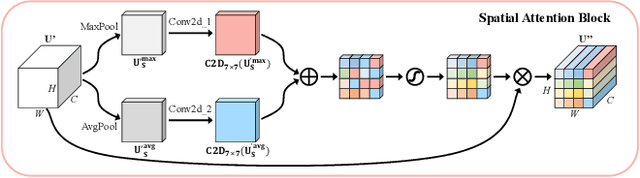
Accurate and reliable optical remote sensing image-based small-ship detection is crucial for maritime surveillance systems, but existing methods often struggle with balancing detection performance and computational complexity. In this paper, we propose a novel lightweight framework called \textit{HSI-ShipDetectionNet} that is based on high-order spatial interactions and is suitable for deployment on resource-limited platforms, such as satellites and unmanned aerial vehicles. HSI-ShipDetectionNet includes a prediction branch specifically for tiny ships and a lightweight hybrid attention block for reduced complexity. Additionally, the use of a high-order spatial interactions module improves advanced feature understanding and modeling ability. Our model is evaluated using the public Kaggle marine ship detection dataset and compared with multiple state-of-the-art models including small object detection models, lightweight detection models, and ship detection models. The results show that HSI-ShipDetectionNet outperforms the other models in terms of recall, and mean average precision (mAP) while being lightweight and suitable for deployment on resource-limited platforms.
Video In Sentences Out
Aug 09, 2014
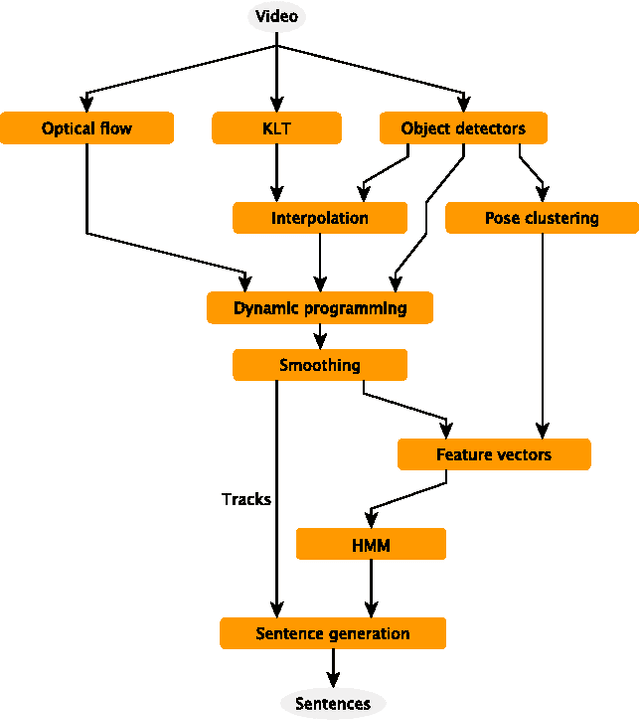


We present a system that produces sentential descriptions of video: who did what to whom, and where and how they did it. Action class is rendered as a verb, participant objects as noun phrases, properties of those objects as adjectival modifiers in those noun phrases, spatial relations between those participants as prepositional phrases, and characteristics of the event as prepositional-phrase adjuncts and adverbial modifiers. Extracting the information needed to render these linguistic entities requires an approach to event recognition that recovers object tracks, the trackto-role assignments, and changing body posture.
Large-Scale Automatic Labeling of Video Events with Verbs Based on Event-Participant Interaction
Apr 16, 2012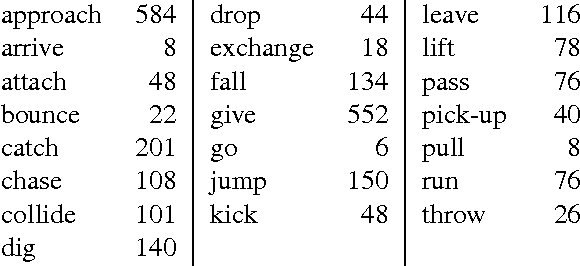



We present an approach to labeling short video clips with English verbs as event descriptions. A key distinguishing aspect of this work is that it labels videos with verbs that describe the spatiotemporal interaction between event participants, humans and objects interacting with each other, abstracting away all object-class information and fine-grained image characteristics, and relying solely on the coarse-grained motion of the event participants. We apply our approach to a large set of 22 distinct verb classes and a corpus of 2,584 videos, yielding two surprising outcomes. First, a classification accuracy of greater than 70% on a 1-out-of-22 labeling task and greater than 85% on a variety of 1-out-of-10 subsets of this labeling task is independent of the choice of which of two different time-series classifiers we employ. Second, we achieve this level of accuracy using a highly impoverished intermediate representation consisting solely of the bounding boxes of one or two event participants as a function of time. This indicates that successful event recognition depends more on the choice of appropriate features that characterize the linguistic invariants of the event classes than on the particular classifier algorithms.