 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre LLMs good pragmatic speakers?
Nov 03, 2024

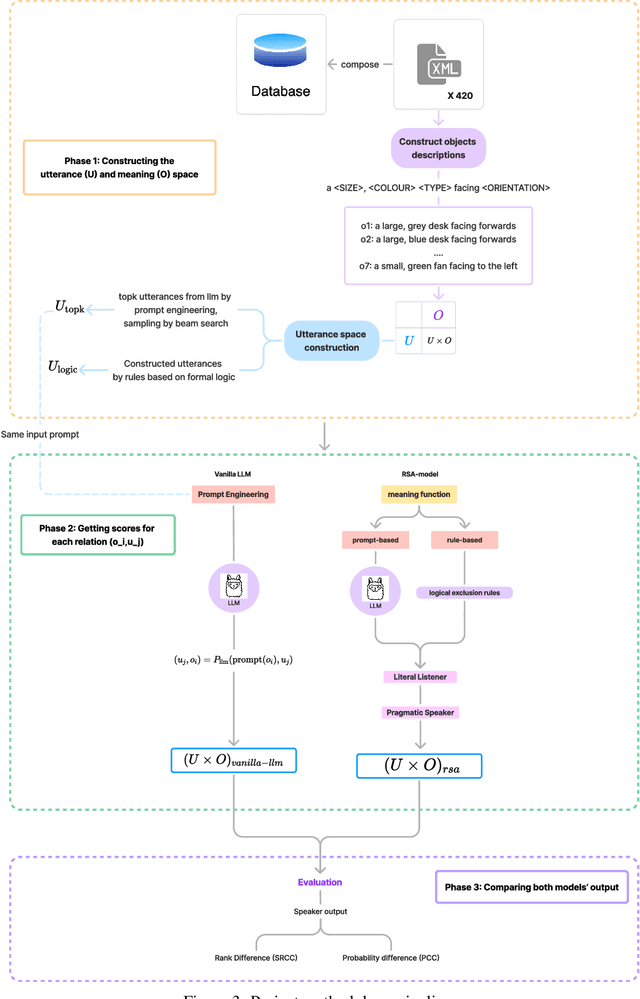

Large language models (LLMs) are trained on data assumed to include natural language pragmatics, but do they actually behave like pragmatic speakers? We attempt to answer this question using the Rational Speech Act (RSA) framework, which models pragmatic reasoning in human communication. Using the paradigm of a reference game constructed from the TUNA corpus, we score candidate referential utterances in both a state-of-the-art LLM (Llama3-8B-Instruct) and in the RSA model, comparing and contrasting these scores. Given that RSA requires defining alternative utterances and a truth-conditional meaning function, we explore such comparison for different choices of each of these requirements. We find that while scores from the LLM have some positive correlation with those from RSA, there isn't sufficient evidence to claim that it behaves like a pragmatic speaker. This initial study paves way for further targeted efforts exploring different models and settings, including human-subject evaluation, to see if LLMs truly can, or be made to, behave like pragmatic speakers.
Disentangling Disentanglement
Dec 06, 2018
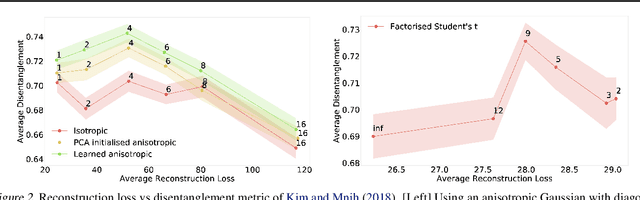
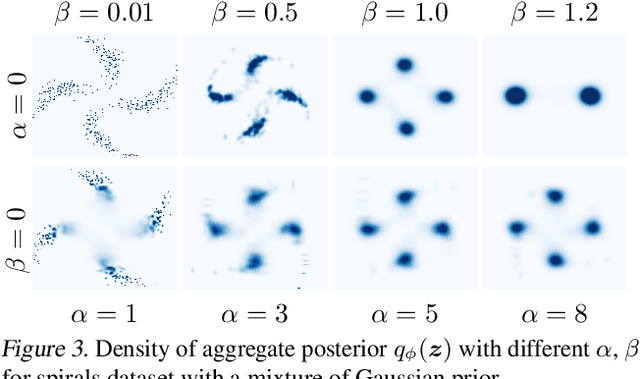
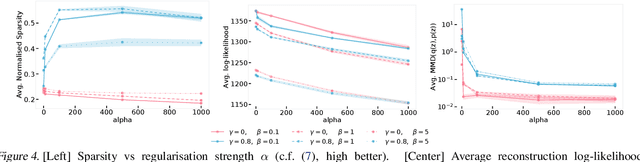
We develop a generalised notion of disentanglement in Variational Auto-Encoders (VAEs) by casting it as a \emph{decomposition} of the latent representation, characterised by i) enforcing an appropriate level of overlap in the latent encodings of the data, and ii) regularisation of the average encoding to a desired structure, represented through the prior. We motivate this by showing that a) the $\beta$-VAE disentangles purely through regularisation of the overlap in latent encodings, and through its average (Gaussian) encoder variance, and b) disentanglement, as independence between latents, can be cast as a regularisation of the aggregate posterior to a prior with specific characteristics. We validate this characterisation by showing that simple manipulations of these factors, such as using rotationally variant priors, can help improve disentanglement, and discuss how this characterisation provides a more general framework to incorporate notions of decomposition beyond just independence between the latents.
Video In Sentences Out
Aug 09, 2014
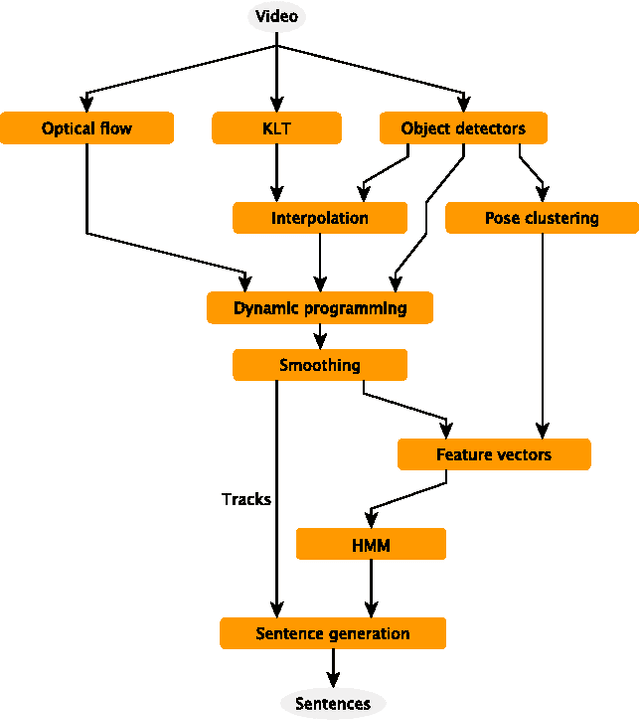


We present a system that produces sentential descriptions of video: who did what to whom, and where and how they did it. Action class is rendered as a verb, participant objects as noun phrases, properties of those objects as adjectival modifiers in those noun phrases, spatial relations between those participants as prepositional phrases, and characteristics of the event as prepositional-phrase adjuncts and adverbial modifiers. Extracting the information needed to render these linguistic entities requires an approach to event recognition that recovers object tracks, the trackto-role assignments, and changing body posture.
Large-Scale Automatic Labeling of Video Events with Verbs Based on Event-Participant Interaction
Apr 16, 2012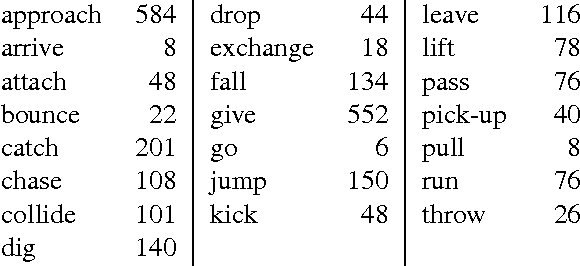



We present an approach to labeling short video clips with English verbs as event descriptions. A key distinguishing aspect of this work is that it labels videos with verbs that describe the spatiotemporal interaction between event participants, humans and objects interacting with each other, abstracting away all object-class information and fine-grained image characteristics, and relying solely on the coarse-grained motion of the event participants. We apply our approach to a large set of 22 distinct verb classes and a corpus of 2,584 videos, yielding two surprising outcomes. First, a classification accuracy of greater than 70% on a 1-out-of-22 labeling task and greater than 85% on a variety of 1-out-of-10 subsets of this labeling task is independent of the choice of which of two different time-series classifiers we employ. Second, we achieve this level of accuracy using a highly impoverished intermediate representation consisting solely of the bounding boxes of one or two event participants as a function of time. This indicates that successful event recognition depends more on the choice of appropriate features that characterize the linguistic invariants of the event classes than on the particular classifier algorithms.
Seeing Unseeability to See the Unseeable
Apr 12, 2012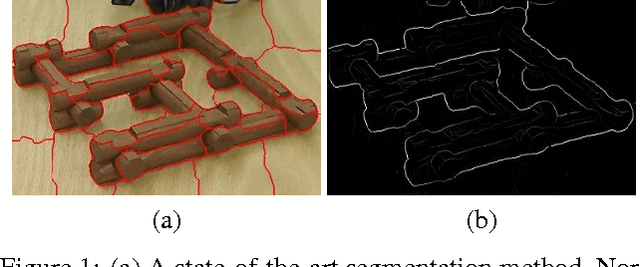

We present a framework that allows an observer to determine occluded portions of a structure by finding the maximum-likelihood estimate of those occluded portions consistent with visible image evidence and a consistency model. Doing this requires determining which portions of the structure are occluded in the first place. Since each process relies on the other, we determine a solution to both problems in tandem. We extend our framework to determine confidence of one's assessment of which portions of an observed structure are occluded, and the estimate of that occluded structure, by determining the sensitivity of one's assessment to potential new observations. We further extend our framework to determine a robotic action whose execution would allow a new observation that would maximally increase one's confidence.
Simultaneous Object Detection, Tracking, and Event Recognition
Apr 12, 2012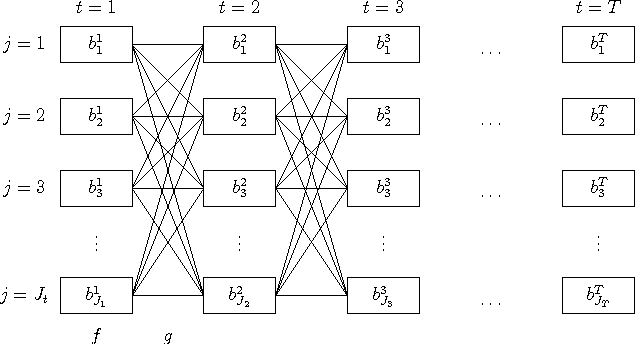



The common internal structure and algorithmic organization of object detection, detection-based tracking, and event recognition facilitates a general approach to integrating these three components. This supports multidirectional information flow between these components allowing object detection to influence tracking and event recognition and event recognition to influence tracking and object detection. The performance of the combination can exceed the performance of the components in isolation. This can be done with linear asymptotic complexity.