 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre LLMs good pragmatic speakers?
Paper and Code
Nov 03, 2024

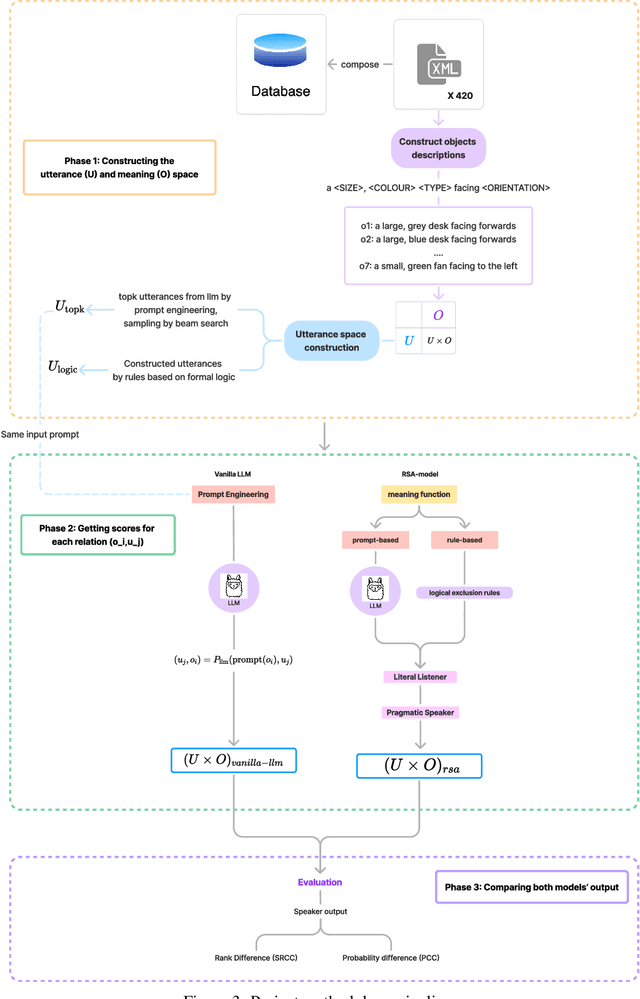

Large language models (LLMs) are trained on data assumed to include natural language pragmatics, but do they actually behave like pragmatic speakers? We attempt to answer this question using the Rational Speech Act (RSA) framework, which models pragmatic reasoning in human communication. Using the paradigm of a reference game constructed from the TUNA corpus, we score candidate referential utterances in both a state-of-the-art LLM (Llama3-8B-Instruct) and in the RSA model, comparing and contrasting these scores. Given that RSA requires defining alternative utterances and a truth-conditional meaning function, we explore such comparison for different choices of each of these requirements. We find that while scores from the LLM have some positive correlation with those from RSA, there isn't sufficient evidence to claim that it behaves like a pragmatic speaker. This initial study paves way for further targeted efforts exploring different models and settings, including human-subject evaluation, to see if LLMs truly can, or be made to, behave like pragmatic speakers.