 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Amazing Race TM: Robot Edition
Oct 28, 2020


State-of-the-art natural-language-driven autonomous-navigation systems generally lack the ability to operate in real unknown environments without crutches, such as having a map of the environment in advance or requiring a strict syntactic structure for natural-language commands. Practical artificial-intelligent systems should not have to depend on such prior knowledge. To encourage effort towards this goal, we propose The Amazing Race TM: Robot Edition, a new task of finding a room in an unknown and unmodified office environment by following instructions obtained in spoken dialog from an untrained person. We present a solution that treats this challenge as a series of sub-tasks: natural-language interpretation, autonomous navigation, and semantic mapping. The solution consists of a finite-state-machine system design whose states solve these sub-tasks to complete The Amazing Race TM. Our design is deployed on a real robot and its performance is demonstrated in 52 trials on 4 floors of each of 3 different previously unseen buildings with 13 untrained volunteers.
Object classification from randomized EEG trials
Apr 09, 2020

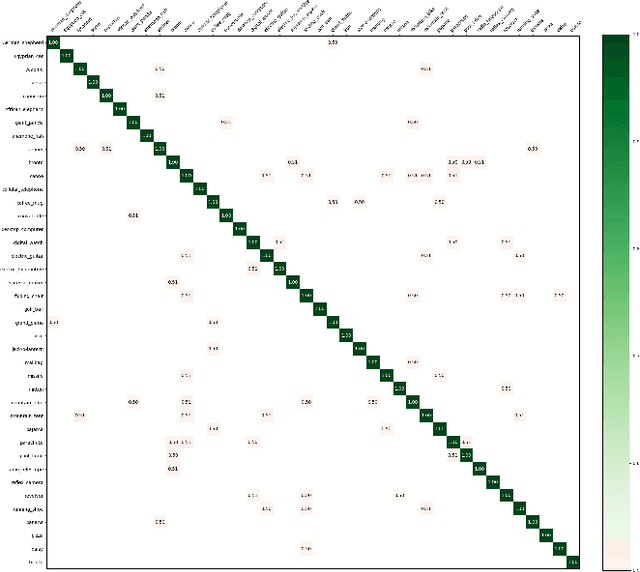
New results suggest strong limits to the feasibility of classifying human brain activity evoked from image stimuli, as measured through EEG. Considerable prior work suffers from a confound between the stimulus class and the time since the start of the experiment. A prior attempt to avoid this confound using randomized trials was unable to achieve results above chance in a statistically significant fashion when the data sets were of the same size as the original experiments. Here, we again attempt to replicate these experiments with randomized trials on a far larger (20x) dataset of 1,000 stimulus presentations of each of forty classes, all from a single subject. To our knowledge, this is the largest such EEG data collection effort from a single subject and is at the bounds of feasibility. We obtain classification accuracy that is marginally above chance and above chance in a statistically significant fashion, and further assess how accuracy depends on the classifier used, the amount of training data used, and the number of classes. Reaching the limits of data collection without substantial improvement in classification accuracy suggests limits to the feasibility of this enterprise.
Training on the test set? An analysis of Spampinato et al.
Dec 18, 2018
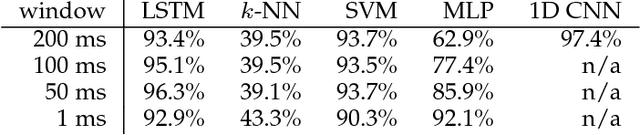

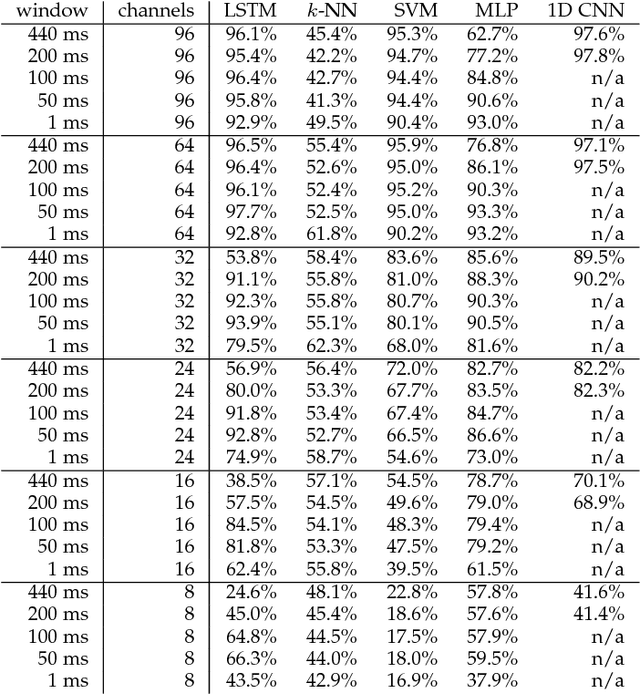
A recent paper [31] claims to classify brain processing evoked in subjects watching ImageNet stimuli as measured with EEG and to use a representation derived from this processing to create a novel object classifier. That paper, together with a series of subsequent papers [8, 15, 17, 20, 21, 30, 35], claims to revolutionize the field by achieving extremely successful results on several computer-vision tasks, including object classification, transfer learning, and generation of images depicting human perception and thought using brain-derived representations measured through EEG. Our novel experiments and analyses demonstrate that their results crucially depend on the block design that they use, where all stimuli of a given class are presented together, and fail with a rapid-event design, where stimuli of different classes are randomly intermixed. The block design leads to classification of arbitrary brain states based on block-level temporal correlations that tend to exist in all EEG data, rather than stimulus-related activity. Because every trial in their test sets comes from the same block as many trials in the corresponding training sets, their block design thus leads to surreptitiously training on the test set. This invalidates all subsequent analyses performed on this data in multiple published papers and calls into question all of the purported results. We further show that a novel object classifier constructed with a random codebook performs as well as or better than a novel object classifier constructed with the representation extracted from EEG data, suggesting that the performance of their classifier constructed with a representation extracted from EEG data does not benefit at all from the brain-derived representation. Our results calibrate the underlying difficulty of the tasks involved and caution against sensational and overly optimistic, but false, claims to the contrary.
Automatic differentiation in machine learning: a survey
Feb 05, 2018

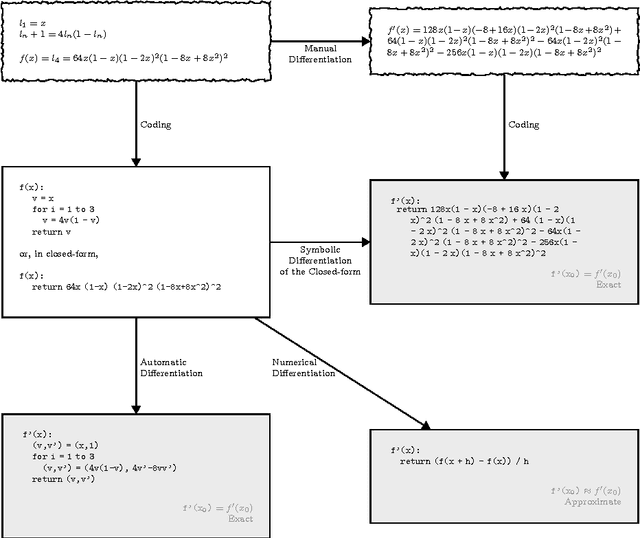

Derivatives, mostly in the form of gradients and Hessians, are ubiquitous in machine learning. Automatic differentiation (AD), also called algorithmic differentiation or simply "autodiff", is a family of techniques similar to but more general than backpropagation for efficiently and accurately evaluating derivatives of numeric functions expressed as computer programs. AD is a small but established field with applications in areas including computational fluid dynamics, atmospheric sciences, and engineering design optimization. Until very recently, the fields of machine learning and AD have largely been unaware of each other and, in some cases, have independently discovered each other's results. Despite its relevance, general-purpose AD has been missing from the machine learning toolbox, a situation slowly changing with its ongoing adoption under the names "dynamic computational graphs" and "differentiable programming". We survey the intersection of AD and machine learning, cover applications where AD has direct relevance, and address the main implementation techniques. By precisely defining the main differentiation techniques and their interrelationships, we aim to bring clarity to the usage of the terms "autodiff", "automatic differentiation", and "symbolic differentiation" as these are encountered more and more in machine learning settings.
* 43 pages, 5 figures
Tricks from Deep Learning
Nov 10, 2016The deep learning community has devised a diverse set of methods to make gradient optimization, using large datasets, of large and highly complex models with deeply cascaded nonlinearities, practical. Taken as a whole, these methods constitute a breakthrough, allowing computational structures which are quite wide, very deep, and with an enormous number and variety of free parameters to be effectively optimized. The result now dominates much of practical machine learning, with applications in machine translation, computer vision, and speech recognition. Many of these methods, viewed through the lens of algorithmic differentiation (AD), can be seen as either addressing issues with the gradient itself, or finding ways of achieving increased efficiency using tricks that are AD-related, but not provided by current AD systems. The goal of this paper is to explain not just those methods of most relevance to AD, but also the technical constraints and mindset which led to their discovery. After explaining this context, we present a "laundry list" of methods developed by the deep learning community. Two of these are discussed in further mathematical detail: a way to dramatically reduce the size of the tape when performing reverse-mode AD on a (theoretically) time-reversible process like an ODE integrator; and a new mathematical insight that allows for the implementation of a stochastic Newton's method.
DiffSharp: An AD Library for .NET Languages
Nov 10, 2016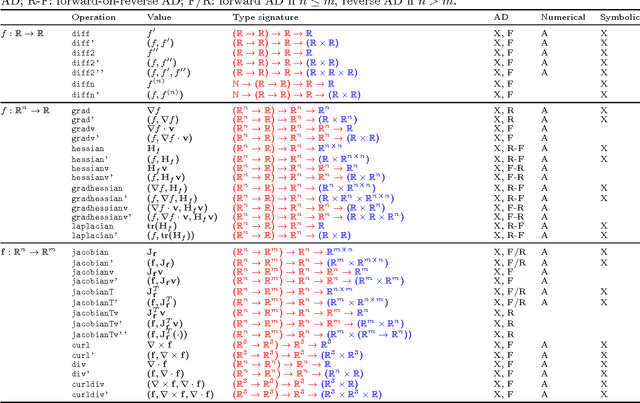
DiffSharp is an algorithmic differentiation or automatic differentiation (AD) library for the .NET ecosystem, which is targeted by the C# and F# languages, among others. The library has been designed with machine learning applications in mind, allowing very succinct implementations of models and optimization routines. DiffSharp is implemented in F# and exposes forward and reverse AD operators as general nestable higher-order functions, usable by any .NET language. It provides high-performance linear algebra primitives---scalars, vectors, and matrices, with a generalization to tensors underway---that are fully supported by all the AD operators, and which use a BLAS/LAPACK backend via the highly optimized OpenBLAS library. DiffSharp currently uses operator overloading, but we are developing a transformation-based version of the library using F#'s "code quotation" metaprogramming facility. Work on a CUDA-based GPU backend is also underway.
Binomial Checkpointing for Arbitrary Programs with No User Annotation
Nov 10, 2016
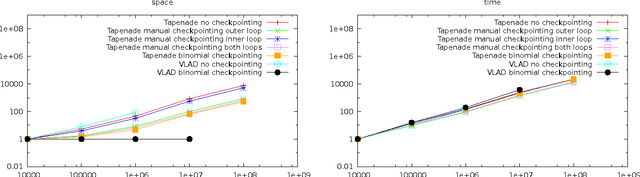
Heretofore, automatic checkpointing at procedure-call boundaries, to reduce the space complexity of reverse mode, has been provided by systems like Tapenade. However, binomial checkpointing, or treeverse, has only been provided in Automatic Differentiation (AD) systems in special cases, e.g., through user-provided pragmas on DO loops in Tapenade, or as the nested taping mechanism in adol-c for time integration processes, which requires that user code be refactored. We present a framework for applying binomial checkpointing to arbitrary code with no special annotation or refactoring required. This is accomplished by applying binomial checkpointing directly to a program trace. This trace is produced by a general-purpose checkpointing mechanism that is orthogonal to AD.
Sentence Directed Video Object Codetection
Jan 26, 2016

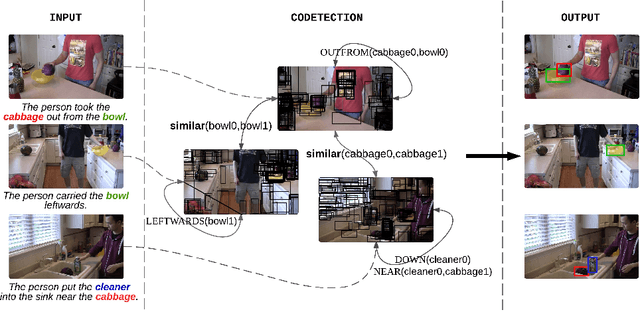
We tackle the problem of video object codetection by leveraging the weak semantic constraint implied by sentences that describe the video content. Unlike most existing work that focuses on codetecting large objects which are usually salient both in size and appearance, we can codetect objects that are small or medium sized. Our method assumes no human pose or depth information such as is required by the most recent state-of-the-art method. We employ weak semantic constraint on the codetection process by pairing the video with sentences. Although the semantic information is usually simple and weak, it can greatly boost the performance of our codetection framework by reducing the search space of the hypothesized object detections. Our experiment demonstrates an average IoU score of 0.423 on a new challenging dataset which contains 15 object classes and 150 videos with 12,509 frames in total, and an average IoU score of 0.373 on a subset of an existing dataset, originally intended for activity recognition, which contains 5 object classes and 75 videos with 8,854 frames in total.
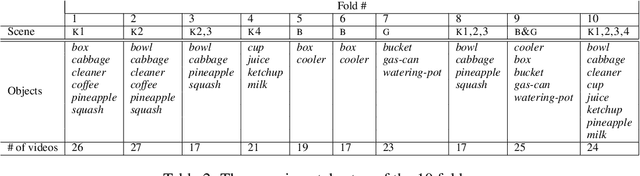
Collecting and Annotating the Large Continuous Action Dataset
Nov 18, 2015


We make available to the community a new dataset to support action-recognition research. This dataset is different from prior datasets in several key ways. It is significantly larger. It contains streaming video with long segments containing multiple action occurrences that often overlap in space and/or time. All actions were filmed in the same collection of backgrounds so that background gives little clue as to action class. We had five humans replicate the annotation of temporal extent of action occurrences labeled with their class and measured a surprisingly low level of intercoder agreement. A baseline experiment shows that recent state-of-the-art methods perform poorly on this dataset. This suggests that this will be a challenging dataset to foster advances in action-recognition research. This manuscript serves to describe the novel content and characteristics of the LCA dataset, present the design decisions made when filming the dataset, and document the novel methods employed to annotate the dataset.
Robot Language Learning, Generation, and Comprehension
Aug 25, 2015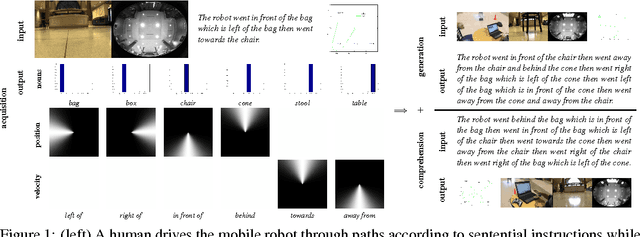



We present a unified framework which supports grounding natural-language semantics in robotic driving. This framework supports acquisition (learning grounded meanings of nouns and prepositions from human annotation of robotic driving paths), generation (using such acquired meanings to generate sentential description of new robotic driving paths), and comprehension (using such acquired meanings to support automated driving to accomplish navigational goals specified in natural language). We evaluate the performance of these three tasks by having independent human judges rate the semantic fidelity of the sentences associated with paths, achieving overall average correctness of 94.6% and overall average completeness of 85.6%.