 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentence Directed Video Object Codetection
Paper and Code
Jan 26, 2016

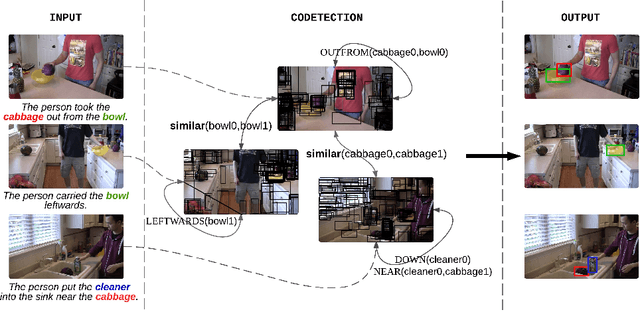
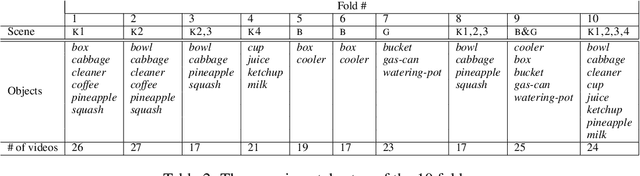
We tackle the problem of video object codetection by leveraging the weak semantic constraint implied by sentences that describe the video content. Unlike most existing work that focuses on codetecting large objects which are usually salient both in size and appearance, we can codetect objects that are small or medium sized. Our method assumes no human pose or depth information such as is required by the most recent state-of-the-art method. We employ weak semantic constraint on the codetection process by pairing the video with sentences. Although the semantic information is usually simple and weak, it can greatly boost the performance of our codetection framework by reducing the search space of the hypothesized object detections. Our experiment demonstrates an average IoU score of 0.423 on a new challenging dataset which contains 15 object classes and 150 videos with 12,509 frames in total, and an average IoU score of 0.373 on a subset of an existing dataset, originally intended for activity recognition, which contains 5 object classes and 75 videos with 8,854 frames in total.