 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollecting and Annotating the Large Continuous Action Dataset
Paper and Code
Nov 18, 2015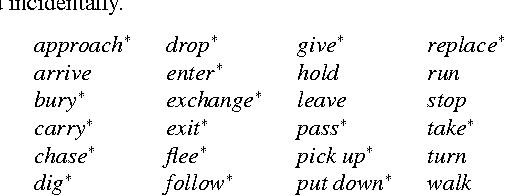

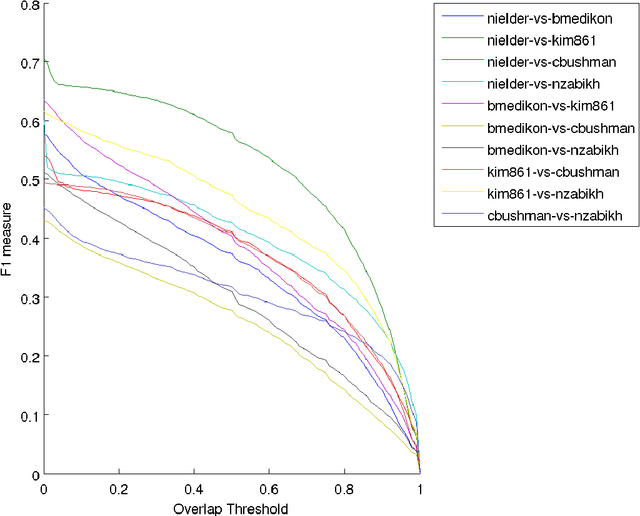

We make available to the community a new dataset to support action-recognition research. This dataset is different from prior datasets in several key ways. It is significantly larger. It contains streaming video with long segments containing multiple action occurrences that often overlap in space and/or time. All actions were filmed in the same collection of backgrounds so that background gives little clue as to action class. We had five humans replicate the annotation of temporal extent of action occurrences labeled with their class and measured a surprisingly low level of intercoder agreement. A baseline experiment shows that recent state-of-the-art methods perform poorly on this dataset. This suggests that this will be a challenging dataset to foster advances in action-recognition research. This manuscript serves to describe the novel content and characteristics of the LCA dataset, present the design decisions made when filming the dataset, and document the novel methods employed to annotate the dataset.