 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollecting and Annotating the Large Continuous Action Dataset
Nov 18, 2015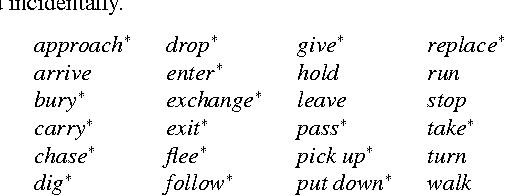

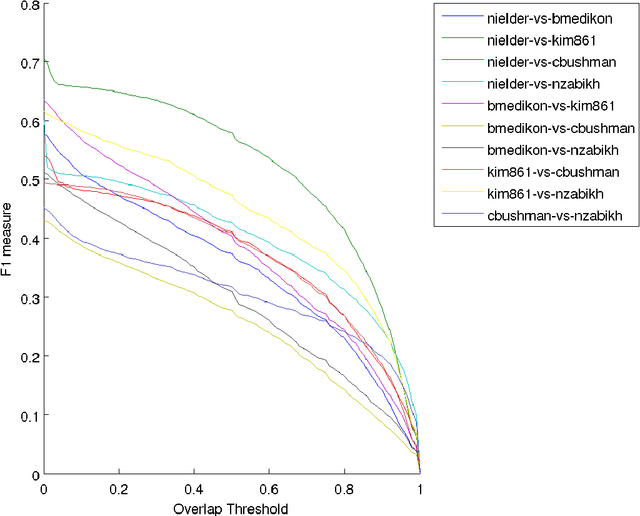

We make available to the community a new dataset to support action-recognition research. This dataset is different from prior datasets in several key ways. It is significantly larger. It contains streaming video with long segments containing multiple action occurrences that often overlap in space and/or time. All actions were filmed in the same collection of backgrounds so that background gives little clue as to action class. We had five humans replicate the annotation of temporal extent of action occurrences labeled with their class and measured a surprisingly low level of intercoder agreement. A baseline experiment shows that recent state-of-the-art methods perform poorly on this dataset. This suggests that this will be a challenging dataset to foster advances in action-recognition research. This manuscript serves to describe the novel content and characteristics of the LCA dataset, present the design decisions made when filming the dataset, and document the novel methods employed to annotate the dataset.
Robot Language Learning, Generation, and Comprehension
Aug 25, 2015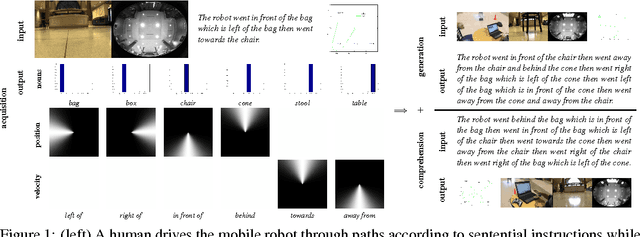



We present a unified framework which supports grounding natural-language semantics in robotic driving. This framework supports acquisition (learning grounded meanings of nouns and prepositions from human annotation of robotic driving paths), generation (using such acquired meanings to generate sentential description of new robotic driving paths), and comprehension (using such acquired meanings to support automated driving to accomplish navigational goals specified in natural language). We evaluate the performance of these three tasks by having independent human judges rate the semantic fidelity of the sentences associated with paths, achieving overall average correctness of 94.6% and overall average completeness of 85.6%.
Felzenszwalb-Baum-Welch: Event Detection by Changing Appearance
Jun 20, 2013
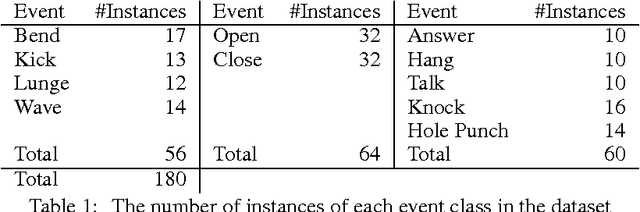

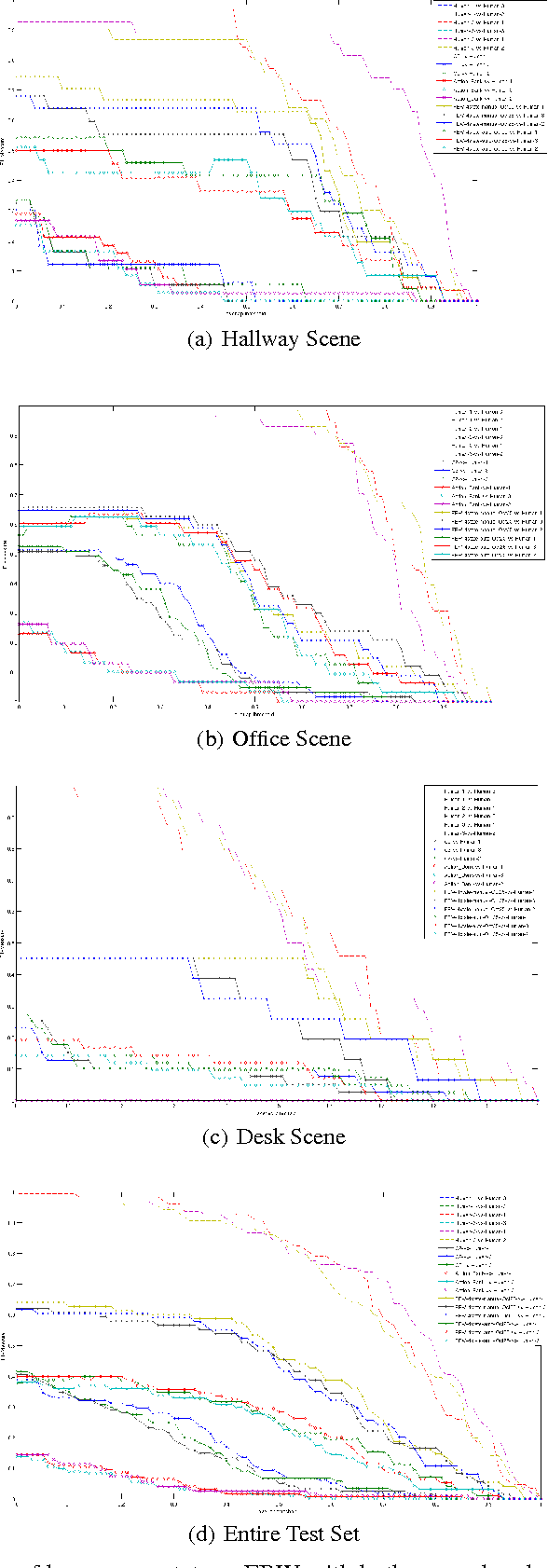
We propose a method which can detect events in videos by modeling the change in appearance of the event participants over time. This method makes it possible to detect events which are characterized not by motion, but by the changing state of the people or objects involved. This is accomplished by using object detectors as output models for the states of a hidden Markov model (HMM). The method allows an HMM to model the sequence of poses of the event participants over time, and is effective for poses of humans and inanimate objects. The ability to use existing object-detection methods as part of an event model makes it possible to leverage ongoing work in the object-detection community. A novel training method uses an EM loop to simultaneously learn the temporal structure and object models automatically, without the need to specify either the individual poses to be modeled or the frames in which they occur. The E-step estimates the latent assignment of video frames to HMM states, while the M-step estimates both the HMM transition probabilities and state output models, including the object detectors, which are trained on the weighted subset of frames assigned to their state. A new dataset was gathered because little work has been done on events characterized by changing object pose, and suitable datasets are not available. Our method produced results superior to that of comparison systems on this dataset.